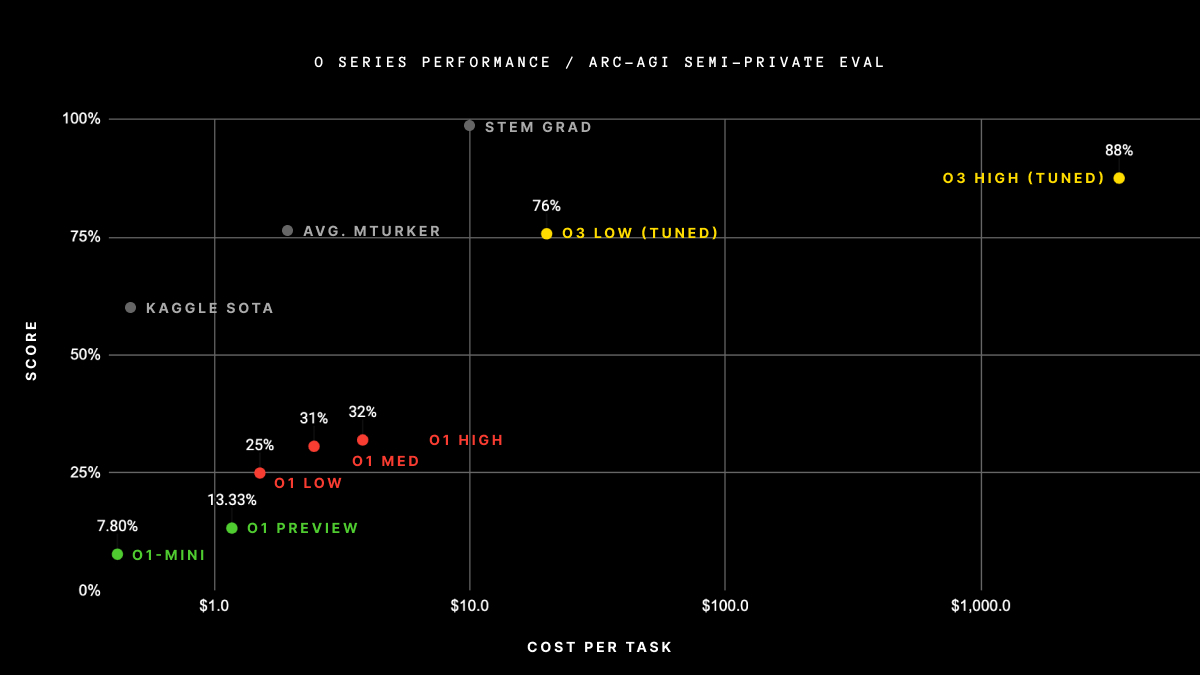
2024年,大语言模型在推理能力方面取得了显著突破。以O系列模型为例,在ARC-AGI评估任务中展现了令人瞩目的性能【1】:
- O3模型达到了87.5%的准确率,尽管每个任务的计算成本较高(超过$1,000)
- 相比之下,未采用特殊推理技术的传统LLMs准确率通常低于25%
如何通过有效的Prompting 来激发大语言模型的深层次推理能力,一直是研究者和开发者关注的核心问题。以下是几种主要的触发方法:
- 少量示例CoT提示(Few-shot CoT):通过提供少量推理示例,引导模型学习推理模式并应用到新问题中。
- 指令型提示(Instruction prompting):明确指导模型逐步思考问题,避免直接跳至答案。
- 指令微调(Instruction tuning):针对多步思考的推理任务对模型进行微调,提升其在类似任务中生成连贯思维链的能力。
- 强化学习(Reinforcement learning):利用强化学习技术训练模型,使其能够生成更完整、更准确的推理链。
本文重点:
我们将深入探讨Inference-time techniques,特别关注如何通过扩展token预算来提升LLM的推理能力。主要包括三个维度:
- 基本提示词技巧:使用更多的token预算来生成单一的解决方案。
- 从多个候选中进行搜索和选择,增加推理的宽度。
- 模型迭代自我改进,增加推理的深度,最终到达最优解。
使用更多的Token生成单一解决方案
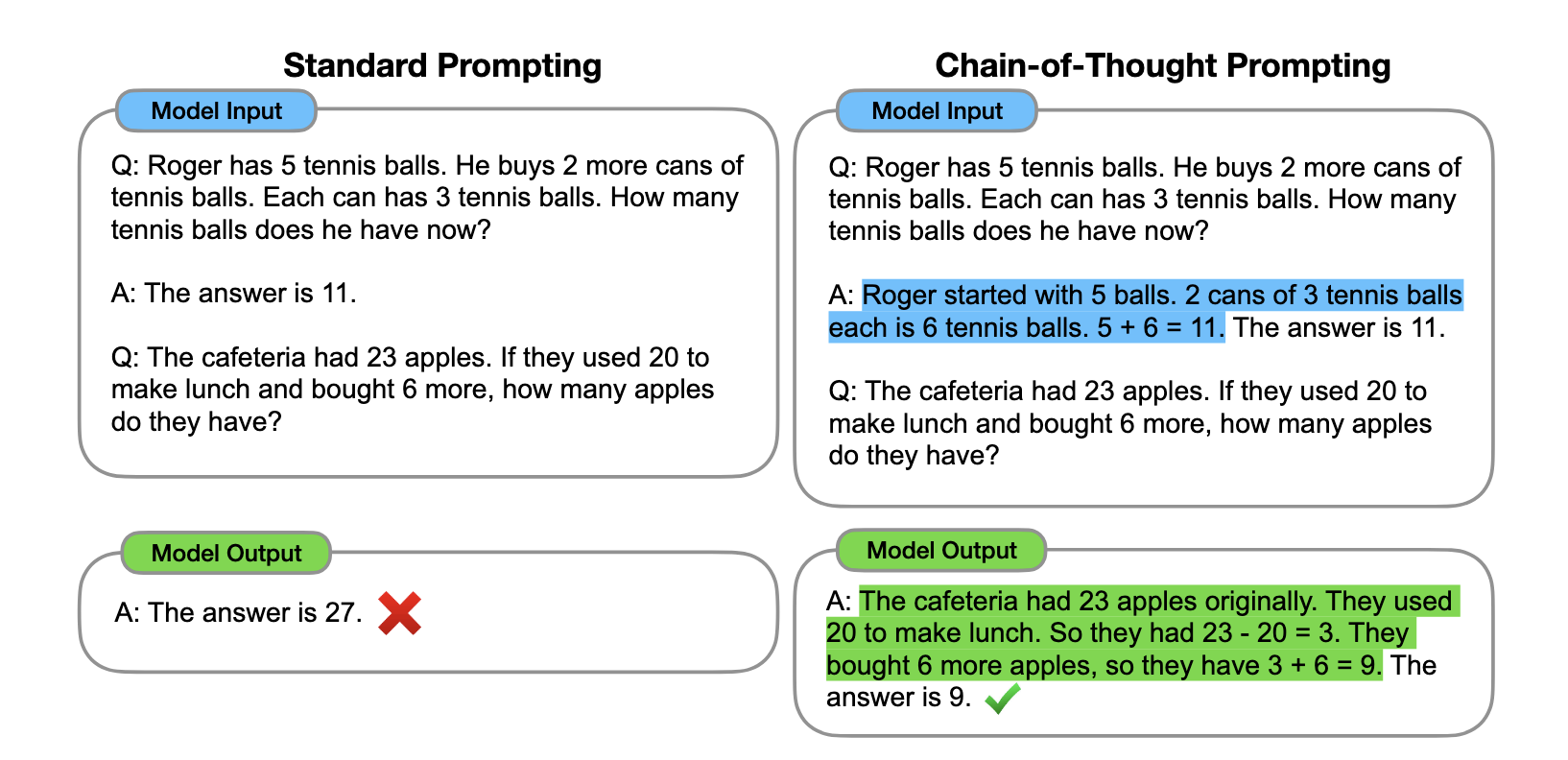
优化提示词能显著提升模型在各类任务中的表现。本节将介绍一些提示词工程技术,帮助我们更好地完成复杂任务。 下图对比了Standard Prompting和CoT Prompting两种方法【2】【3】:
- Standard Prompting:仅给出最终答案,没有推理过程,容易导致错误结果。
- CoT Prompting:展示完整的推理过程,让模型清晰地说明从问题到答案的推导步骤。
Zero-shot CoT Prompting:通过指令引导生成思维链推理
0-shot CoT 是一种通过简短指令引导LLM进行推理的方法,无需依赖任何示例。在这种方法中,模型不需要看到具体的示范或训练数据,仅通过一个简单的指令(如"Let’s think step by step.")(Fig.3)即可开始推理【4】。

优缺点:
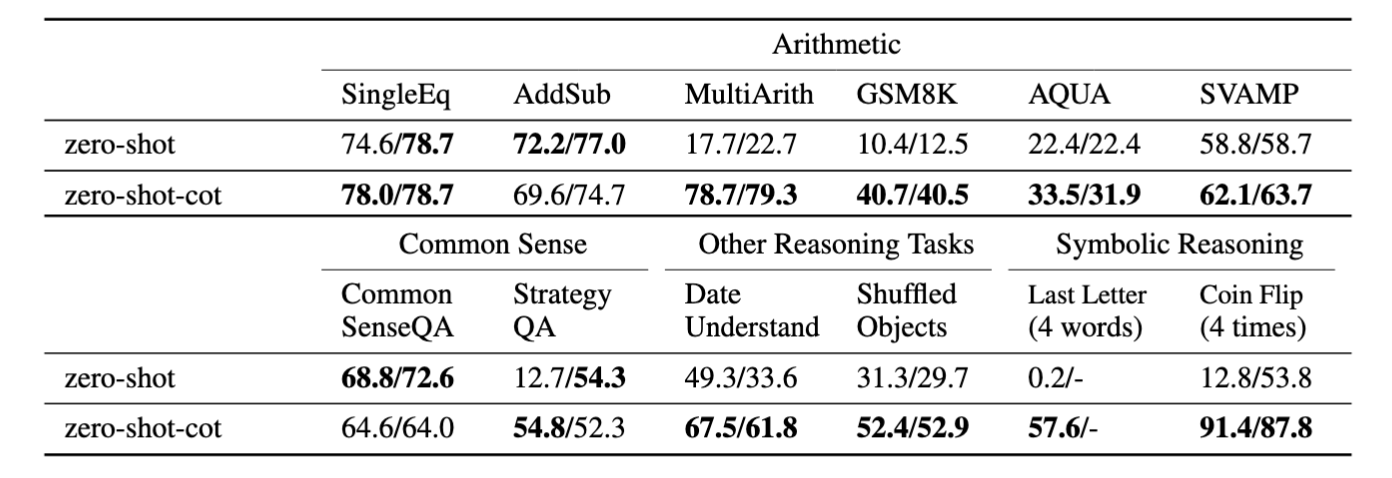
- 0-shot CoT的表现显著优于普通的0-shot方法,特别是在数学和符号推理等较难的任务中(Fig.4)
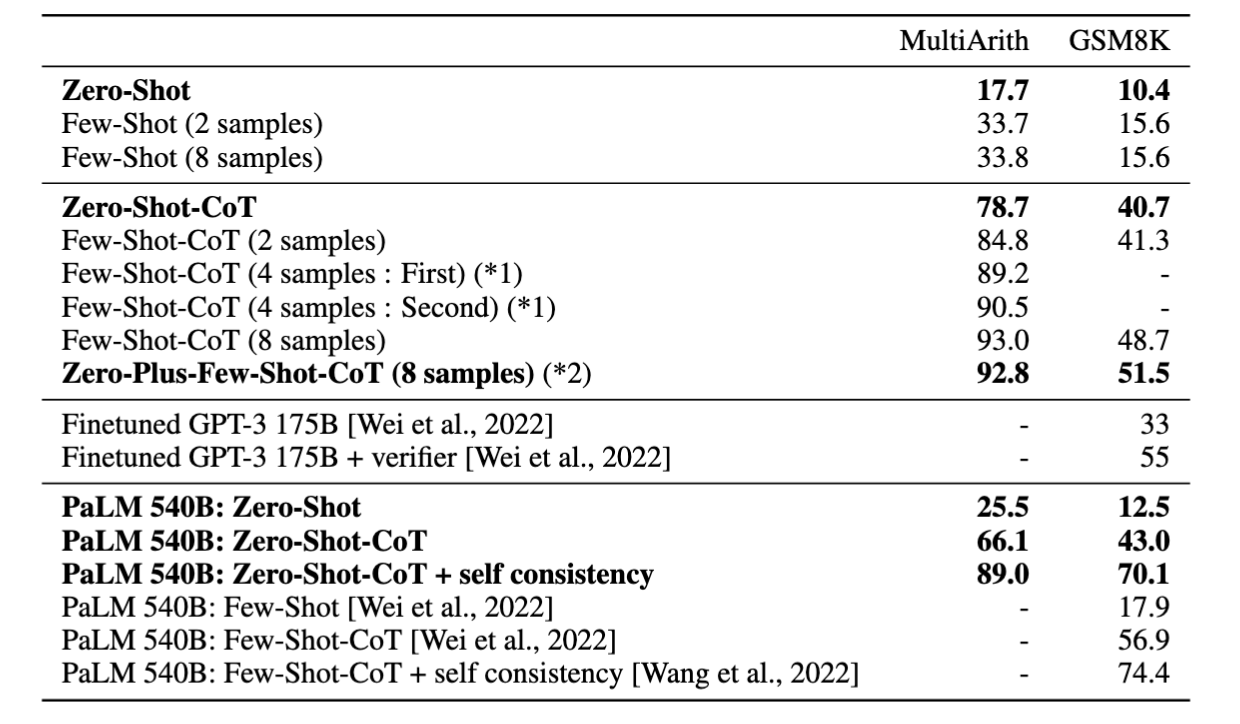
- 相比Few-shot CoT,0-shot CoT更加便捷,因为无需手动标注示例。但从性能来看,0-shot CoT的表现仍然不如Few-shot CoT(Fig.5)
Analogical Prompting:让模型自主生成参考案例
在analogical prompting中,我们并不直接向LLM提供样本,而是先指示模型回忆相关的示例,然后再解决测试问题(fig.6)。具体来说,模型会首先自我生成一些相关示例,接着利用这些示例去解决目标问题。【5】
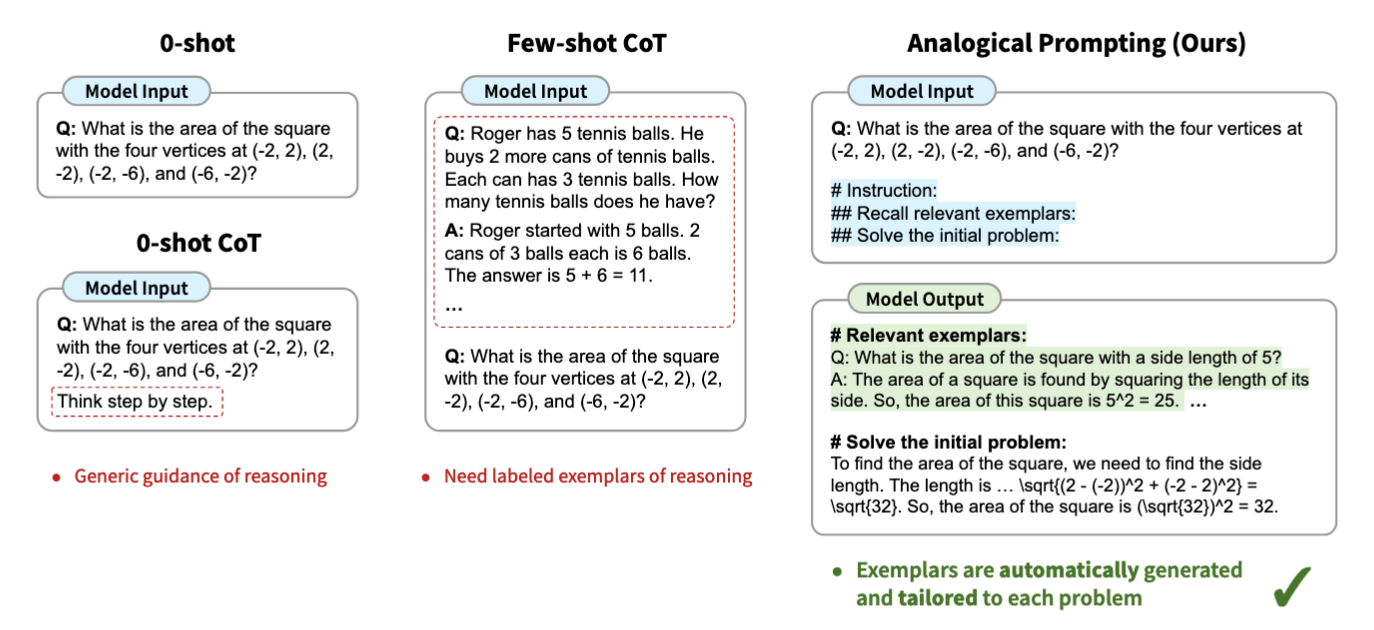
Analogical prompting 表现优于 0-shot CoT和 Few-shot CoT方法。
优势:
- 示例由LLM自主生成,无需手动标注
- 生成的示例能够根据特定问题量身定制,更具相关性。
- 除了生成示例外,LLM还能产生更高层次的知识概括,为问题提供更广泛的见解,从而帮助解决原始问题。(Fig.7)

局限性:
- 自动生成示例可能比人工标注示例包含更多错误。
- 有时生成的示例可能与问题无关,或包含错误的解题步骤,影响最终的推理质量。
LLM作为优化器,迭代改进Prompt
在这种方法中,我们将LLM作为优化器,通过分析历史轨迹(即已尝试的提示词及其对应的效果分数)来不断改进提示词质量【6】。具体实现需要两个LLM配合(Fig.8):
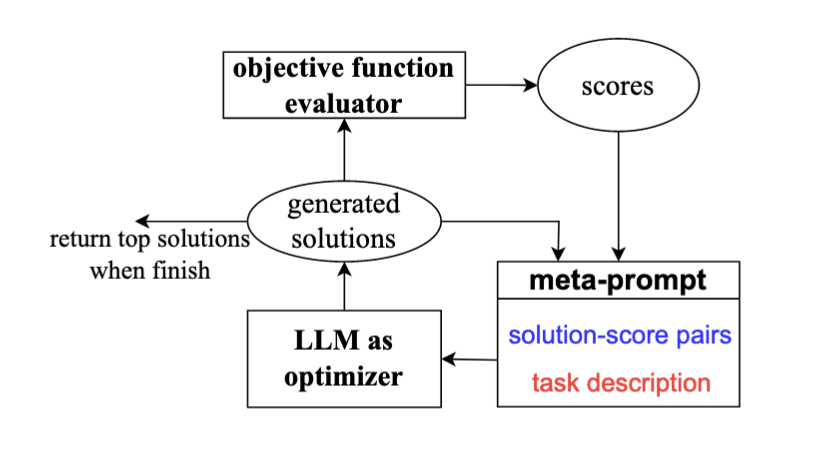
- Optimizer:基于历史提示词和任务示例,生成新的更优提示词
- Evaluator:评估提示词的准确性表现
为实现这一目标,我们需要设计Meta prompt(Fig.9),主要包含两个关键要素:**Trajectory(记录过往提示词及准确率)**和 Exemplars:(展示待优化的目标任务)

实验结果表明,这种方法效果显著(Fig.10):

- 从基础提示词"Let’s solve the problem"(准确率60.8%)开始
- 优化后的最佳提示词比"Let’s think step by step"提升了约8%,达到80.7%的准确率,与PaLM-2使用少量示例CoT的效果相当
这种方法带来两个重要启示:
- 无需手动编写示例即可达到与few-shot CoT相当的性能
- 不仅节省了人工调优时间,还能发现一些意想不到的新视角,比如"Take a deep breath and work on this problem“这样的提示策略(Fig.10)
Least-to-most prompting: 通过问题分解实现推理能力提升
Least-to-most prompting的核心思想是通过指导LLM如何分解复杂问题来提升其推理能力【7】。这种方法包含2个关键步骤(Fig.11):
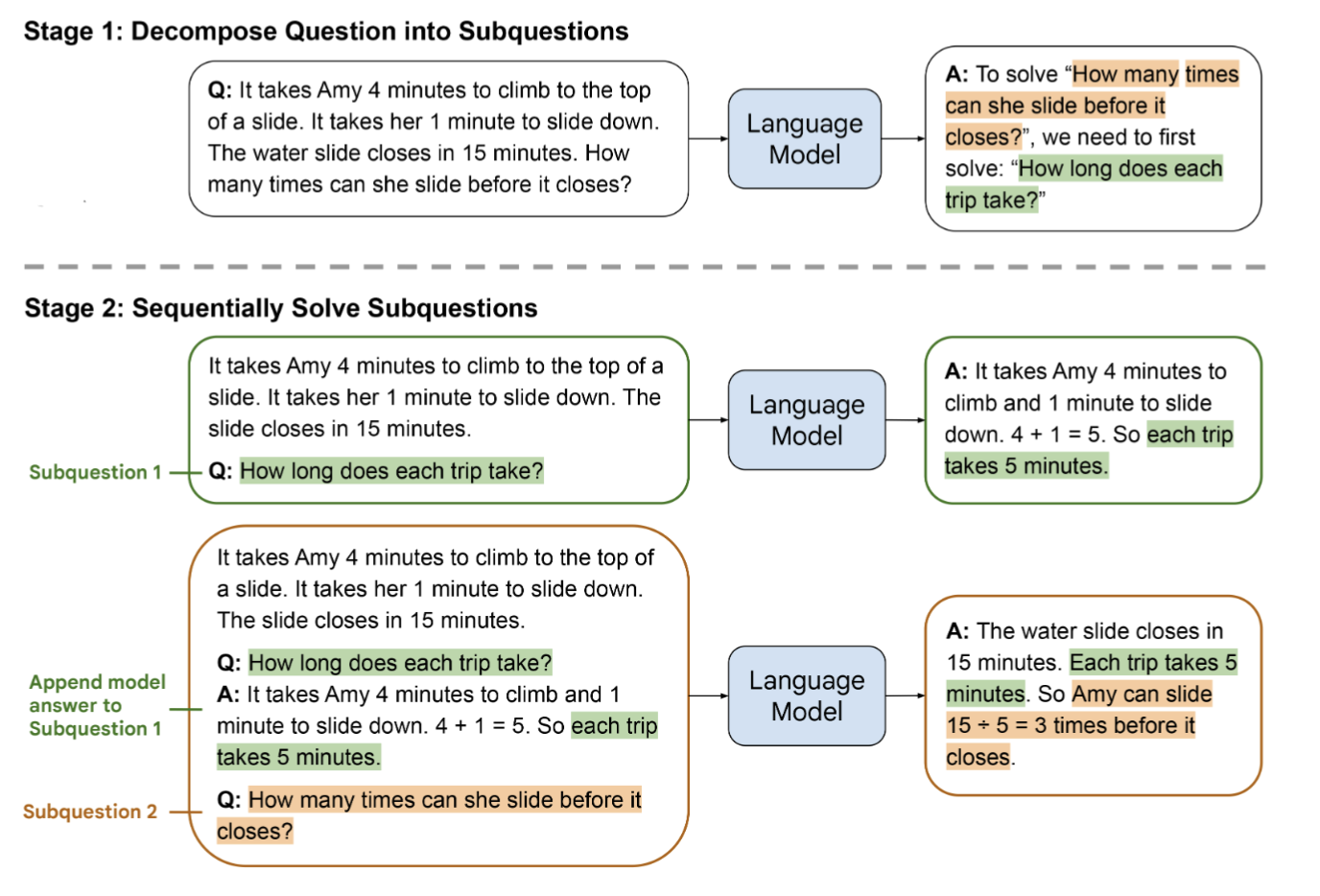
- Problem reduction:将复杂问题分解为简单的子问题
- Sequentially solve subquestions:按顺序解决子问题,并将解决方案组合起来得到最终答案
Example: 解决SCAN任务
任务目标:将合成的自然语言命令转换为对应的动作序列。比如,“look thrice after jump”可能转换为“JUMP LOOK LOOK LOOK”。(Fig.12)

实验结果:使用从易到难提示法,模型在该任务上取得了接近完美的表现,准确率高达99.7% (Fig.13)

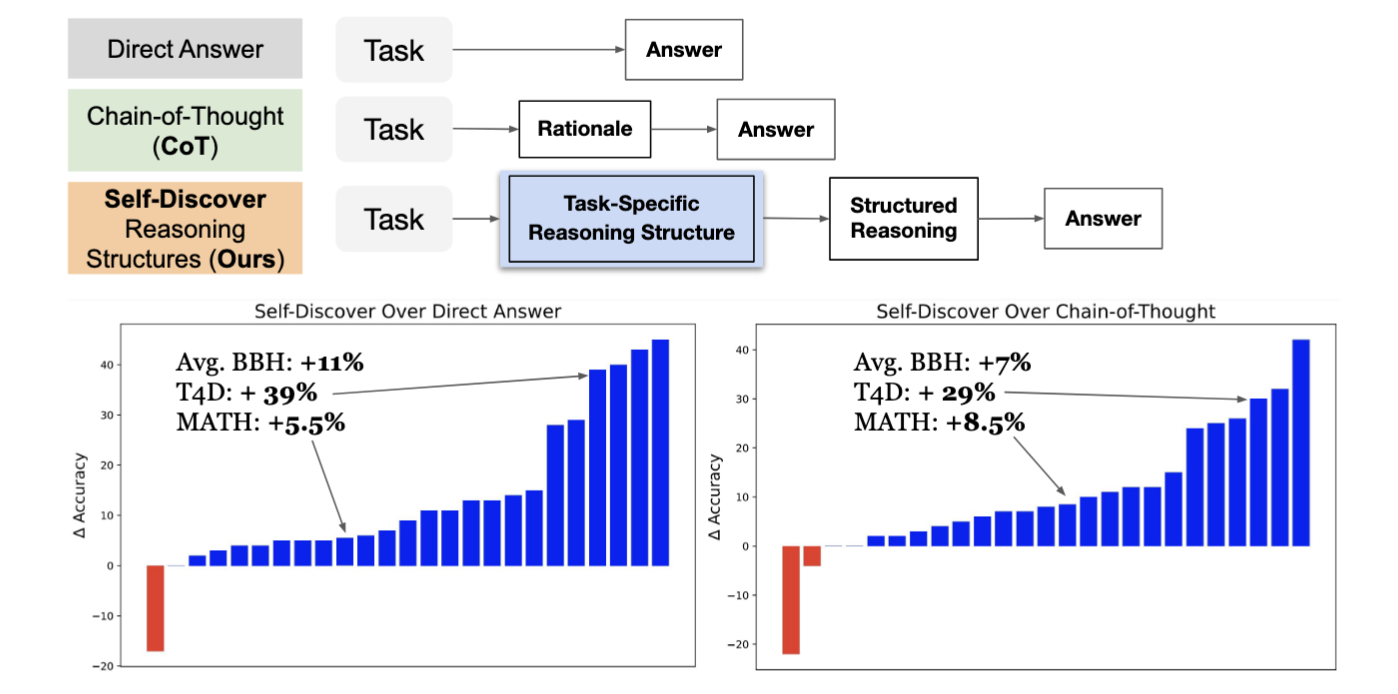
Self-Discover:让模型自主构建推理结构
不同的推理任务往往需要不同的推理结构,包括任务分解方式和各阶段的规划等。Self-Discover方法的创新之处在于,引导模型自动构建特定任务的推理结构,且无需手动编写示例【8】。这种方法分为两个主要阶段(Fig.14):
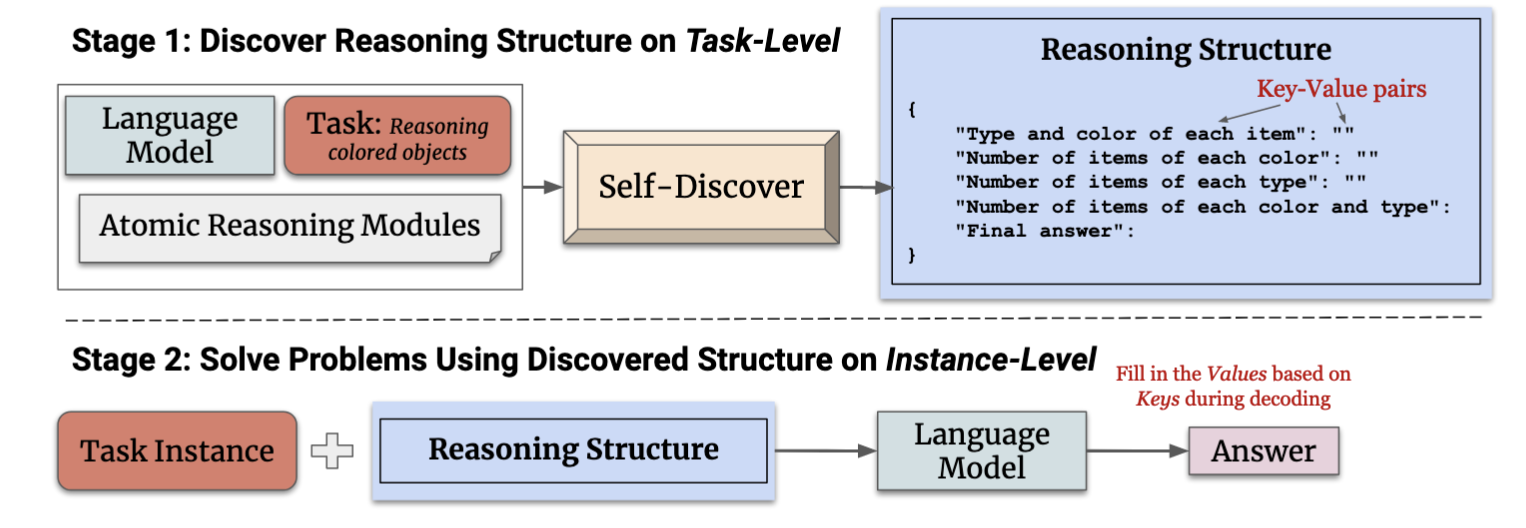
- Stage 1: 模型通过Self-Discover模块自动发现并生成适合任务的推理结构
- Stage 2: 模型利用已发现的推理结构来解答具体的任务实例
优势:Self-Discover方法在处理复杂推理任务时表现优异,相比传统的直接答案和链式思维方法,在多个复杂推理任务中展现出了优越的性能。尤其在需要进行多步推理的任务中,Self-Discover能够提供更高的准确率和更强的推理能力(Fig.15)。
增加推理的宽度,探索更广泛的解决方案空间
为提升LLM的推理能力,我们不应该局限为每个问题只生成1个解决方案。通过探索多个推理分支,可以让模型从不同角度进行问题求解,从而提高推理的准确性和灵活性。
Self-consistency: 多路径推理提升准确率
Self-consistency 是一个简单但效果显著的方法。它的核心思想是让模型生成多个推理路径,然后从中选择最一致的答案,而不是仅依赖单一推理过程【9】。具体实现包含2个关键步骤(Fig.16):
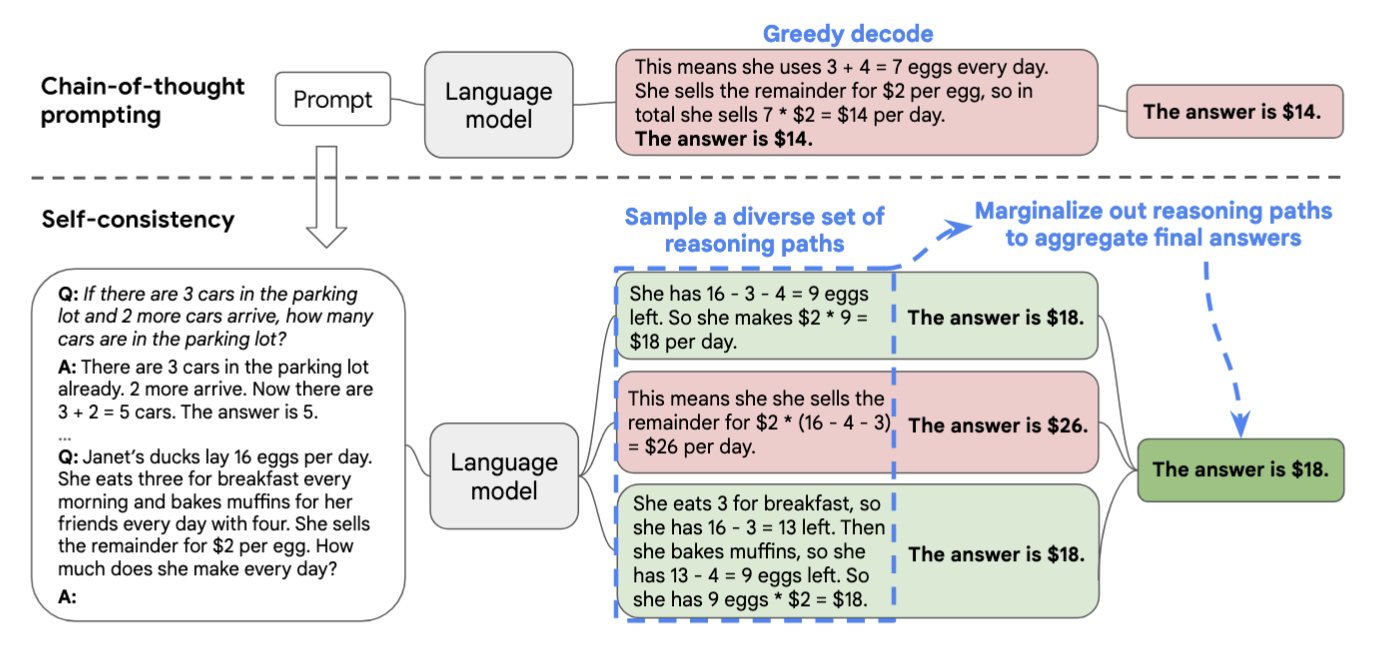
- 多路径生成:让模型对同一个问题生成多个不同推理路径
- 答案聚合:基于最终答案的一致性来选择最优解
Note: 答案的选择仅基于最终结果,不需要不同推理路径之间完全一致
这一看似简单的策略,却能显著提升模型的表现(Fig.17):
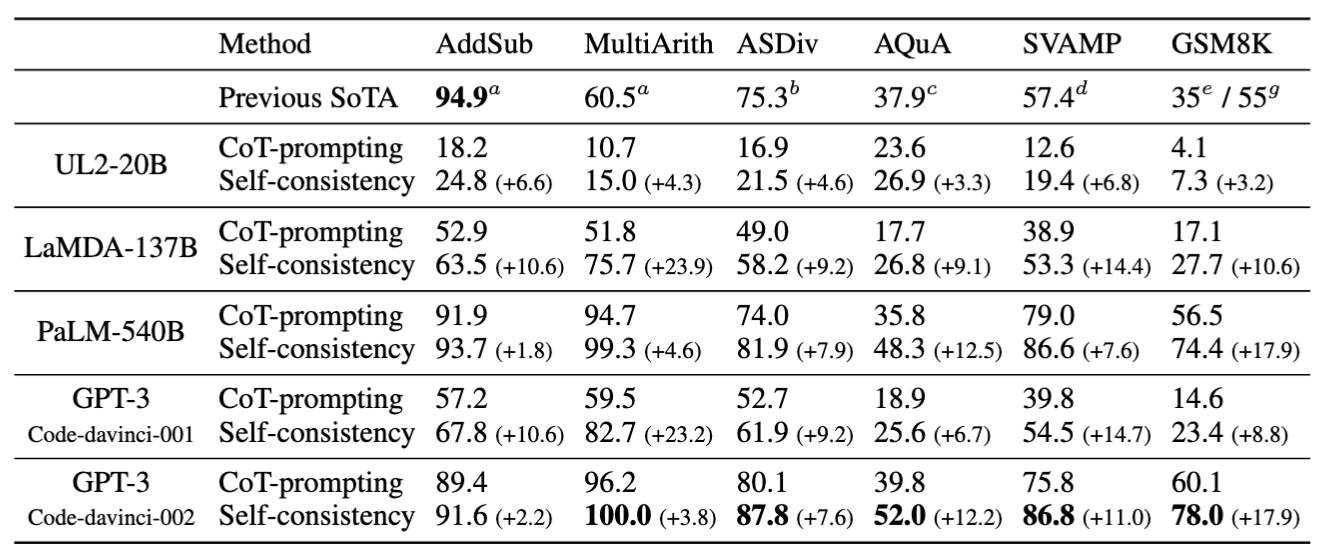
- 准确率随样本量提升:实验数据显示,随着推理路径数量的增加,模型的准确率显著提升(Fig.18)。
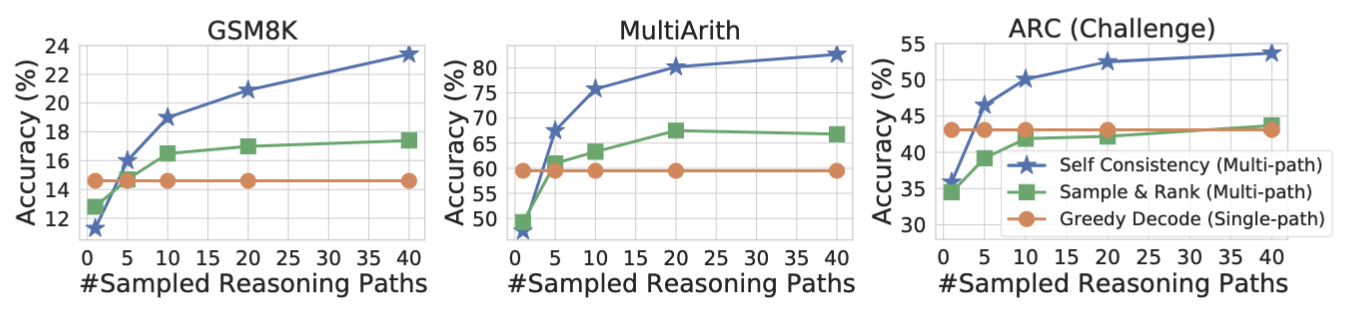
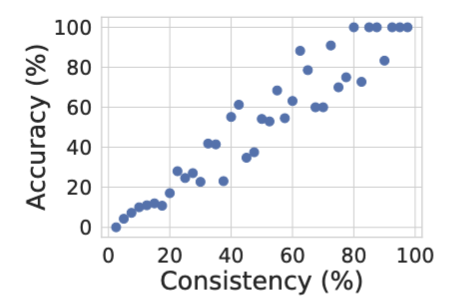
- 该方法揭示了准确率与一致性之间的关联。当多个推理路径指向相同答案时,LLM对其预测结论的信心更高,聚合后答案的正确性往往也更高(Fig.19)。
基于Self-consistency的应用:AlphaCode
在代码生成领域,基于Self-consistency的方法展现出了强大的效果。Google DeepMind的AlphaCode项目就是采用了这一方法(Fig.20),其核心是通过"Flitering & Clustering"来优化代码生成的结果【10】。具体步骤如下
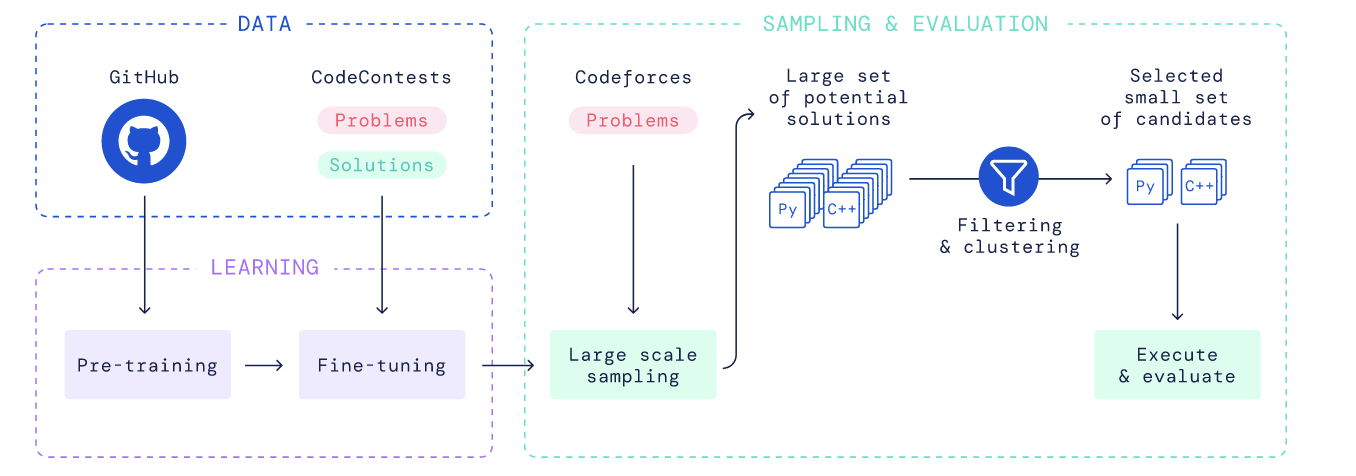
- 对LLM生成的代码(仅限通过测试用例代码),作为输入进行测试
- 将所有输出相同的程序聚类在一起
- 从最大的10个聚类中,各选择1个程序作为代表
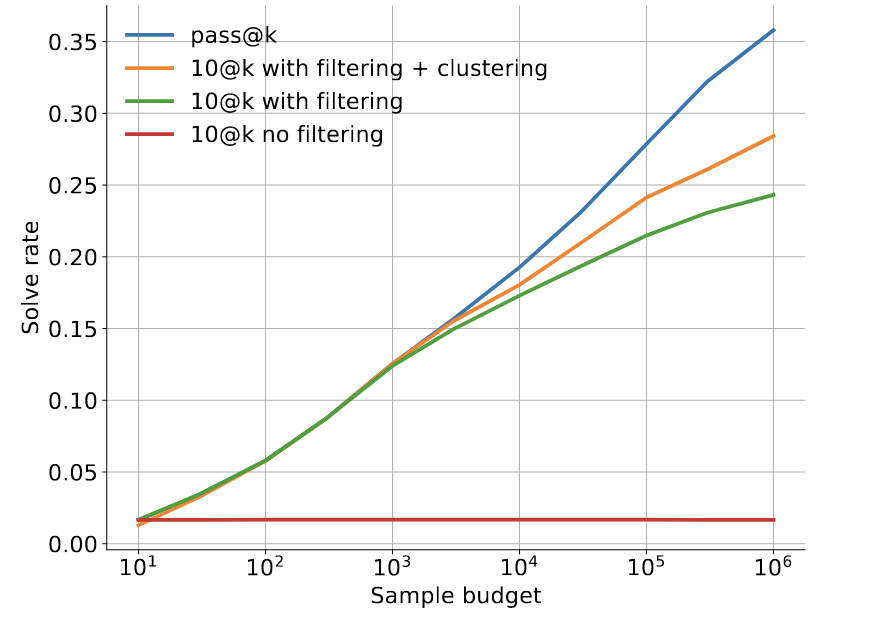
在 Codeforces 上的实验结果表明,聚类方法相比单纯的过滤带来了显著的提升。然而与Oracle selection相比,仍然存在一定的差距。(Fig.21,蓝色为Oracle selection)
局限性:Self-consistency在自由生成任务中的效果,不如代码生成中理想。因为自由生成任务没有明确的答案,解码过程复杂且结果不稳定,模型可能难以保持稳定的输出质量。
Universal Self-consistency (USC) : 让模型自主进行一致性选择
USC的核心思想是:取代传统的答案提取过程,直接让LLM执行基于一致性的选择【11】。具体来说:我们向模型发出指令,要求其基于多数共识来选择最一致的回答,并对所有候选回答进行审视(Fig.22)。

这种方法在实践中展现出了显著优势(Fig.23)
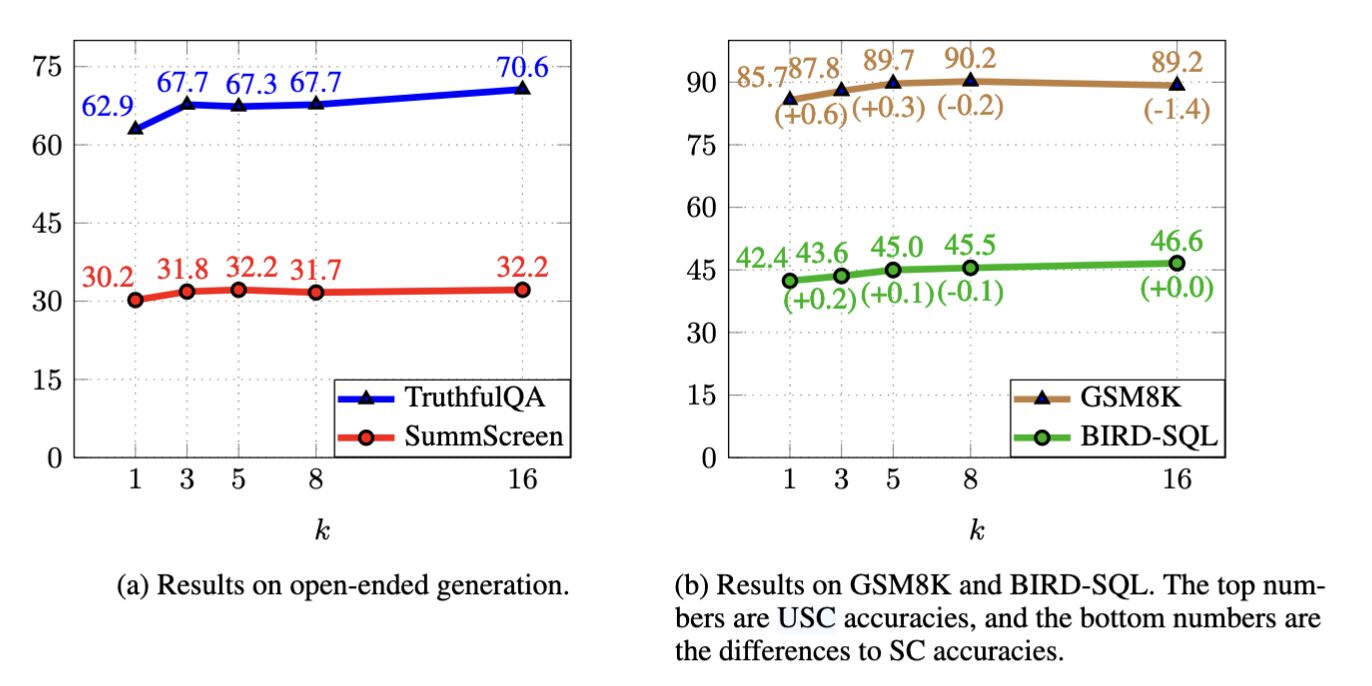
- 在摘要生成和问答等开放式生成任务中,USC取得了显著的性能提升。
- 在数学推理和编程等任务中,USC能够达到与Self-Consistency方法相当的表现,同时无需进行答案提取和代码执行。
需要注意的是,USC的性能受限于模型处理长文本的能力。
Tree-of-thoughts (ToT) : 让LLM进行深度思考
到目前为止,我们所讨论的方法只在最终解决方案层面进行选择,而ToT方法则更进一步。
通过引入逐步评分机制,ToT能够在解决过程中进行树搜索。这意味着我们不用等到完整解决方案后才做出判断,而是可以在搜索过程中优先探索更有希望的步骤【12】。
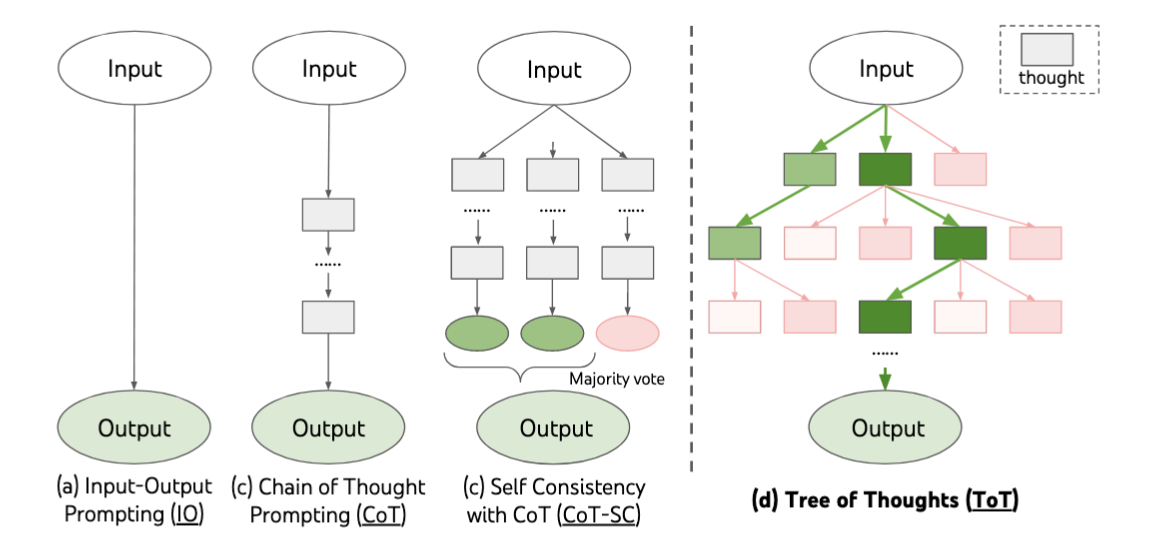
Example: 24点游戏
ToT方法的工作流程如下(Fig.25):
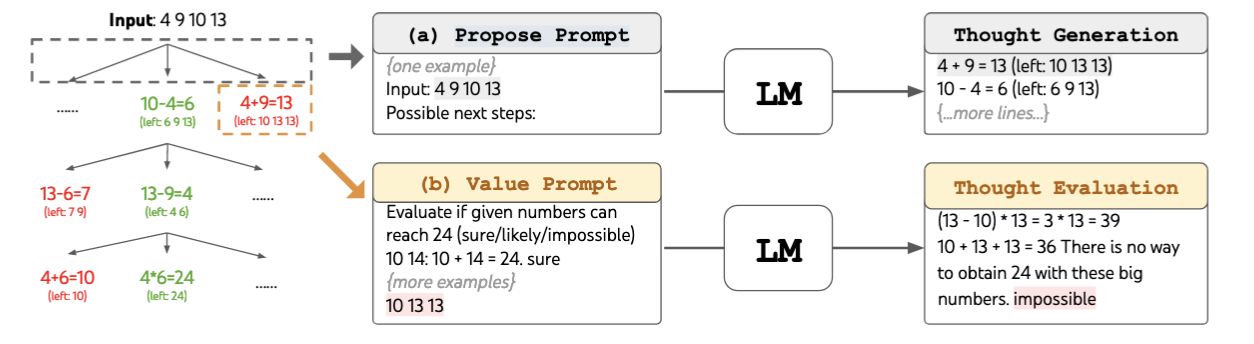
- 思维生成:让模型提出可能的下一步思考方向
- 思维评估:让模型评估当前状态的潜力/可行性
LLM会通过多次投票来选择最佳方案,最终采用得票结果最多的选项(Fig.26)。

研究结果表明:在token预算方面,采用广度优先搜索(BFS)的方法比Standard prompting 和 CoT Prompting方法表现更好。
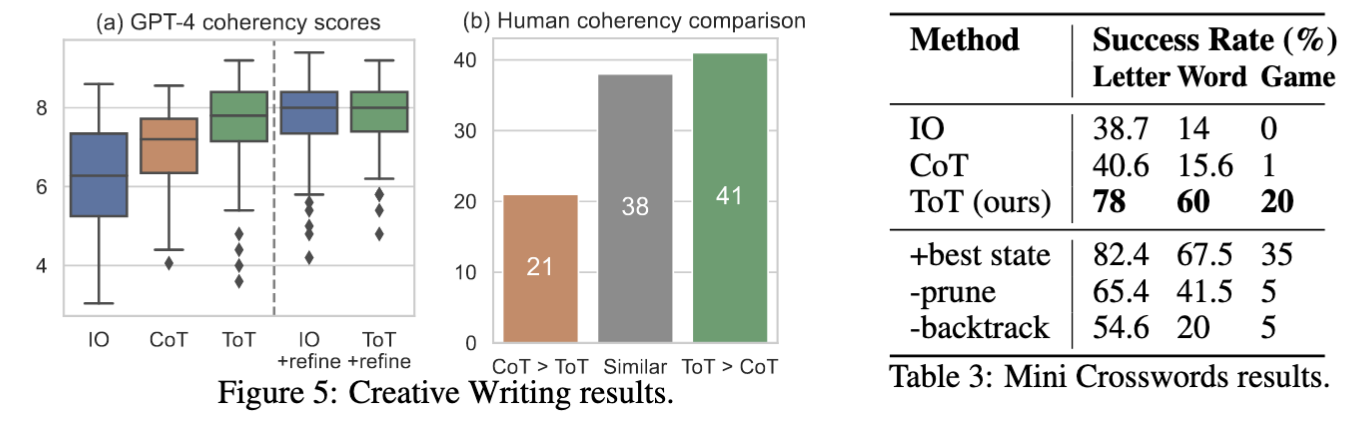
模型迭代自我改进,迈向最优解
在前文中,我们探讨了通过生成多个解来帮助减少单次预测的错误。但这其实是一种相对次优的错误修正方式。因为所有的响应都是同时生成的,模型无法从之前的错误中吸取经验教训。
因此,在这一部分中,我们将重点介绍如何让LLM在推理过程中不断学习和改进,通过迭代优化来提升最终输出的质量。
反思与自我改进:利用内外部反馈提升LLM性能
Reflexion and Self-Refine 是一种让LLM持续优化输出的方法【13】【14】。在生成解决方案后,模型会经历2个关键步骤(Fig.28):
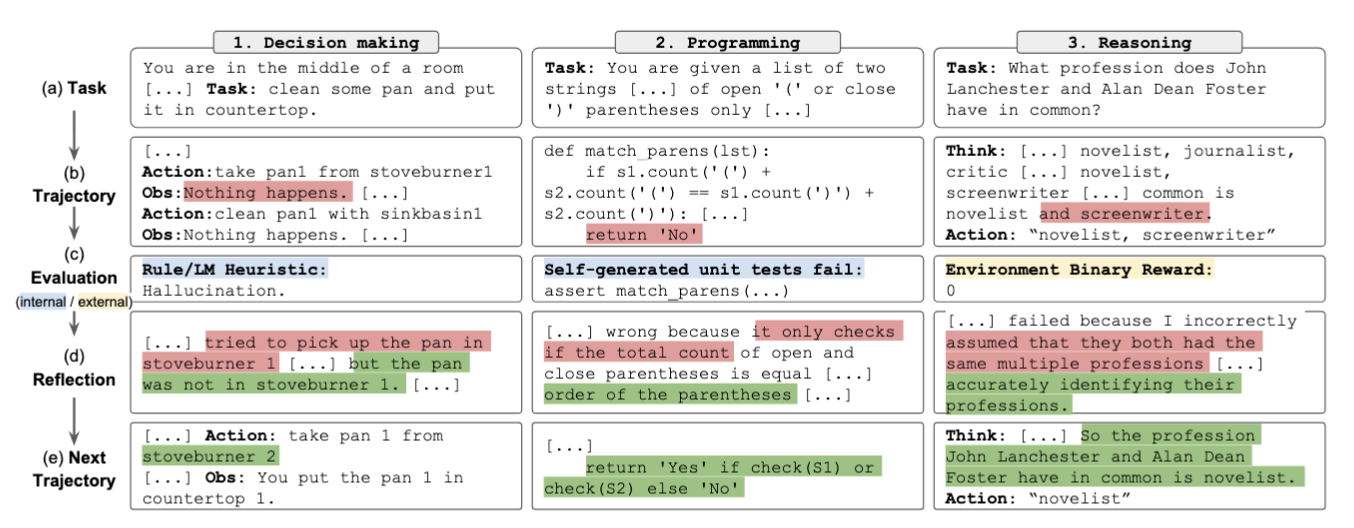
- LLM根据观察结果生成反馈(这个过程可以引入外部评估提供更客观的参考)
- 在Reflexion论文【13】中模型充当代理(agent),向环境提出行动请求,环境根据模型的输入反馈观察结果。这些外部信号帮助模型判断当前步骤的有效性
- LLM结合内部反思和外部反馈优化输出,为下一步预测提供更好的基础
该方法在多个任务中表现出色,尤其是在能够获得高质量外部评估信号的任务中:
- 在ALFWorld任务中,通过有效的评估启发式方法,反思显著提高了模型性能 (Fig.29)
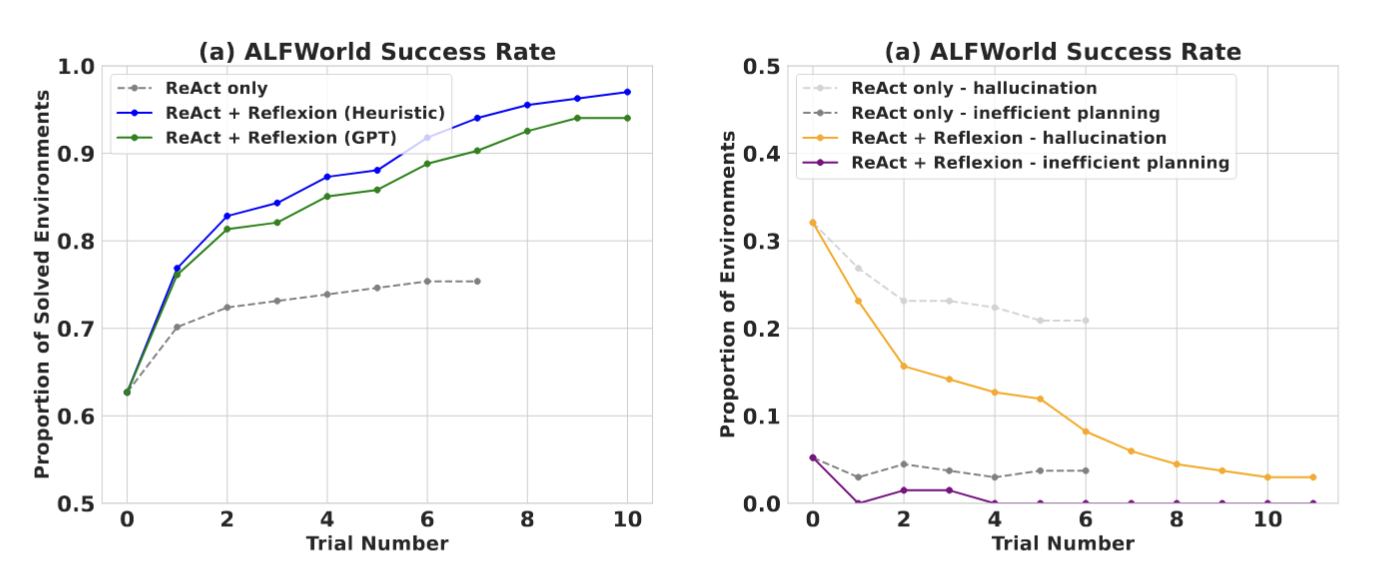
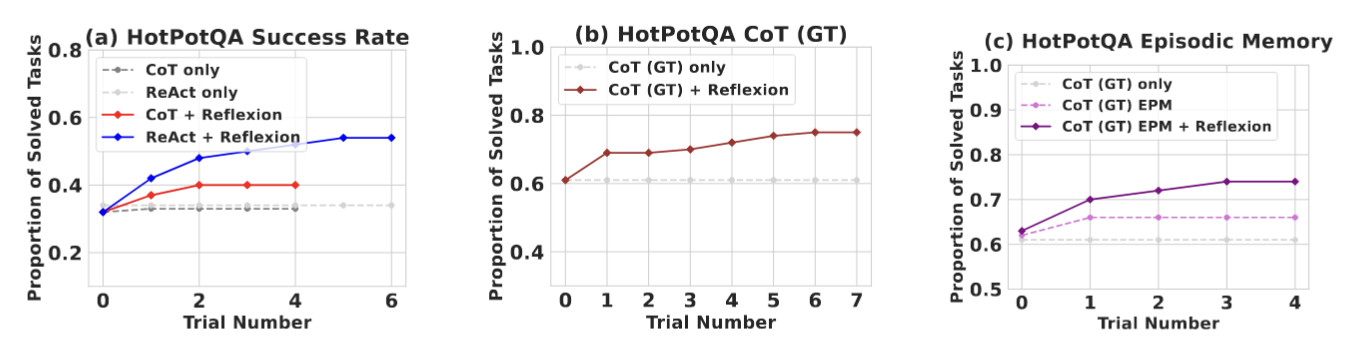
- 在HotPotQA任务中,外部评估为每次反思提供了答案的准确性,从而帮助模型在每次反思后做出更好的改进 (Fig.30)
LLMs 自我纠错能力任有局限
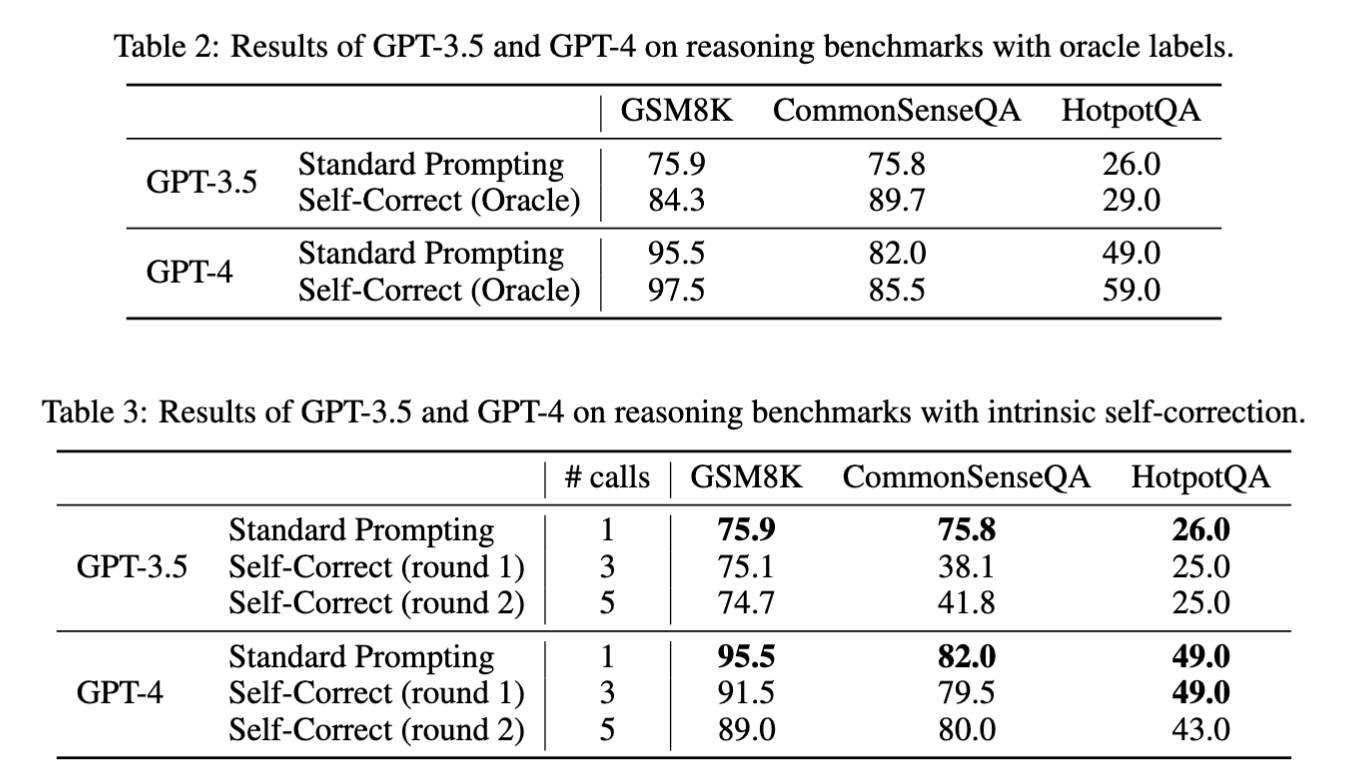
Self-correction方法被证明能可以提升模型性能,但这些研究大多依赖于oracle verifier。然而在实际应用中,我们通常无法获得这样的外部验证机制。那么在没有外部反馈的情况下,LLM的表现如何呢?
在论文“Large Language Models Cannot Self-Correct Reasoning Yet”中,展示了这一问题的负面结果【15】:
-
在没有oracle verifier的情况下,LLM需要自行判断其响应的正确性
-
LLM可能错误地判断自己的预测正确性,从而导致自我修正后性能反而下降
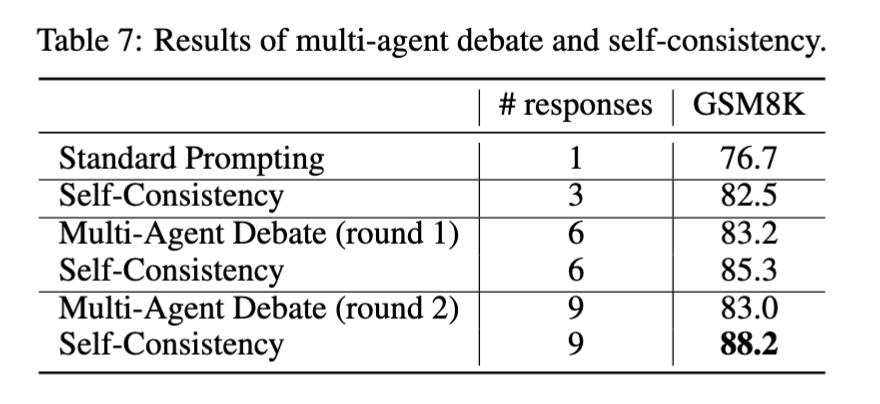
多智能体辩论 vs Self-consistency
多智能体辩论的核心思想是:让模型并行生成多个响应,然后提示LLM评估这些响应并给出更新后的答案。
虽然在 “Multiagent Debate” 论文中表明多智能体辩论优于Self-consistency方法【16】,但深入发现这种方法存在明显的token使用效率问题【15】:如果我们控制相同的回答数量和预算限制,Self-consistency的表现实际上更好。
如何设计有效的推理技术?
在探索了各种技术后,我们可以总结出几个关键原则:
-
通用性和可扩展性优先【17】:
- 最强大方法往往是那些能随着计算能力增长而持续扩展的通用方法。
- 搜索和学习是2种展现出优异扩展性的基础方法。
-
理解模型的能力边界:
- 不同任务可能需要不同的推理策略。
- 选择的技术应该与模型的实际能力相匹配。
-
注重发现机制【17】:
- 我们的目标是打造能够自主发现的AI系统,而不是简单地将人类的发现嵌入其中。
- 过度依赖预设的解决方案可能会阻碍我们理解真正的发现过程。
参考文献:
- “OpenAI O3 Breakthrough High Score on ARC-AGI-Pub.” ARC Prize. Accessed February 15, 2025.
- Wei, Jason, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, et al. “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models.” Preprint, arXiv, January 10, 2023.
- Nye, Maxwell, Anders Johan Andreassen, Guy Gur-Ari, Henryk Michalewski, Jacob Austin, et al. “Show Your Work: Scratchpads for Intermediate Computation with Language Models.” Preprint, arXiv, November 30, 2021.
- Kojima, Takeshi, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. “Large Language Models are Zero-Shot Reasoners.” Preprint, arXiv, January 29, 2023.
- Yasunaga, Michihiro, Xinyun Chen, Yujia Li, Panupong Pasupat, Jure Leskovec, et al. “Large Language Models as Analogical Reasoners.” Preprint, arXiv, March 9, 2024.
- Yang, Chengrun, Xuezhi Wang, Yifeng Lu, Hanxiao Liu, Quoc V. Le, Denny Zhou, and Xinyun Chen. “Large Language Models as Optimizers.” Preprint, arXiv, April 15, 2024.
- Zhou, Denny, Nathanael Schärli, Le Hou, Jason Wei, Nathan Scales, et al. “Least-to-Most Prompting Enables Complex Reasoning in Large Language Models.” Preprint, arXiv, April 16, 2023.
- Zhou, Pei, Jay Pujara, Xiang Ren, Xinyun Chen, Heng-Tze Cheng, et al. “Self-Discover: Large Language Models Self-Compose Reasoning Structures.” Preprint, arXiv, February 6, 2024.
- Wang, Xuezhi, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, and others. “Self-Consistency Improves Chain of Thought Reasoning in Language Models.” Preprint, arXiv, March 7, 2023.
- Li, Yujia, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, and others. “Competition-Level Code Generation with AlphaCode.” Science, Decemeber 9, 2022.
- Chen, Xinyun, Renat Aksitov, Uri Alon, Jie Ren, Kefan Xiao, and others. “Universal Self-Consistency for Large Language Model Generation.” Preprint, arXiv, November 29, 2023.
- Yao, Shunyu, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. “Tree of Thoughts: Deliberate Problem Solving with Large Language Models.” Preprint, arXiv, December 3, 2023.
- Shinn, Noah, Federico Cassa, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. “Reflexion: Language Agents with Verbal Reinforcement Learning.” Preprint, arXiv, October 10, 2023.
- Madaan, Aman, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, and others. “Self-Refine: Iterative Refinement with Self-Feedback.” Preprint, arXiv, May 25, 2023.
- Huang, Jie, Xinyun Chen, Swaroop Mishra, Huaixiu Steven Zheng, Adams Wei Yu, Xinying Song, and Denny Zhou. “Large Language Models Cannot Self-Correct Reasoning Yet.” Preprint, arXiv, March 14, 2024.
- Du, Yilun, Shuang Li, Antonio Torralba, Joshua B. Tenenbaum, and Igor Mordatch. “Improving Factuality and Reasoning in Language Models through Multiagent Debate.” Preprint, arXiv, May 23, 2023.
- Sutton, Richard. The Bitter Lesson.