本文内容来自 Jason Weston (Meta) 在 UC Berkeley Advanced Large Language Model Agents 课程中的分享,探讨了大语言模型的推理能力提升 。以下为讲座内容:
AI 能力正在快速发展,如 O1、R1 等模型在推理基准测试中取得的突破性进展。本文将聚焦于模型的自我提升能力(self-improvement)。
为了更好地理解AI的推理机制,我们首先需要区分两种基本的思维模式:System 1和 System 2:
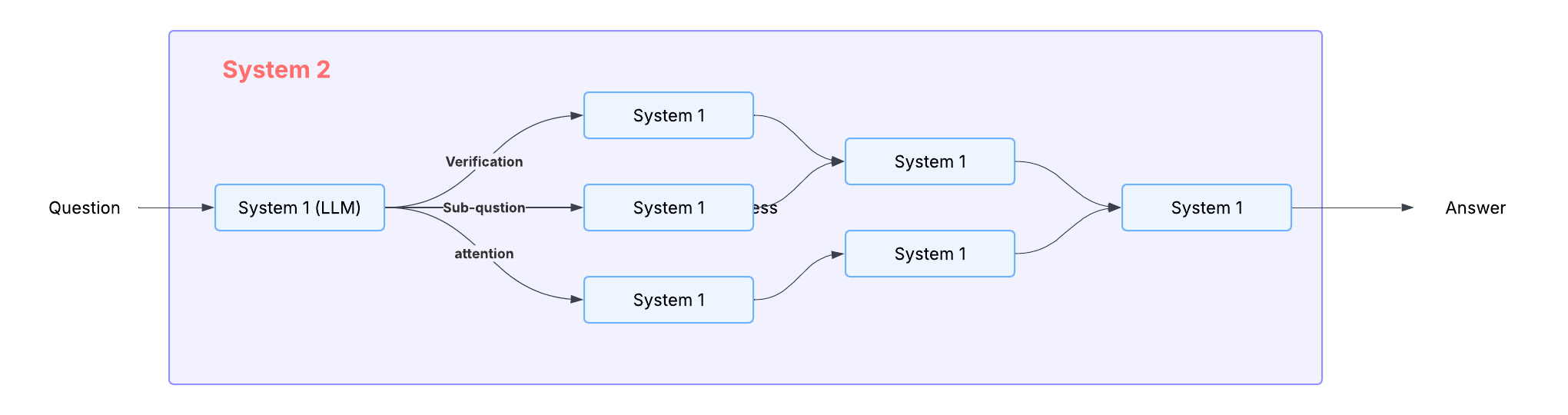
System 1:快速直觉系统
这是一种类似人类直觉反应的快速思维系统,主要依赖关联性思维。在LLM中,这种能力体现在transformer神经网络的基础运作机制上。其主要特征包括:
- 每个token使用固定的计算资源;
- 直接输出答案;
- 局限性:容易学习到虚假关联,产生幻觉、迎合性回答、越界等问题;
System 2: 深度思考系统
这代表了一种更深层次的思维模式,目前主要通过CoT来实现。在生成最终答案之前,System 2会进行系统性的推理分析。它具有以下优势:
- 能够执行规划、搜索和验证等复杂任务;
- 具备动态计算能力,可以通过CoT、ToT等方式实现灵活推理;
我们可以通过优化模型架构或权重来提升System 1的表现,也可以通过改进推理链的生成方式来增强System 2的表现;最终目标是让AI具备自我学习能力,这包括3个关键方面:
- 能够自主设计具有挑战性的训练任务
- 评估任务的完成质量,形成自我奖励机制
- 根据理解和反馈,持续更新优化自身能力
接下来,我们将分两个部分展开讨论:首先回顾语言模型的历史发展历程,然后深入探讨过去一年中的重要研究进展。
LLM Post-training:O1/R1 之前的优化之路
Instrcut GPT
InstructGPT 是在 2022 年提出的一种语言模型优化方法[1],它结合了监督学习和基于人类反馈的强化学习(RLHF),比单纯的监督微调更为先进。这种方法包含三个关键步骤(如图):
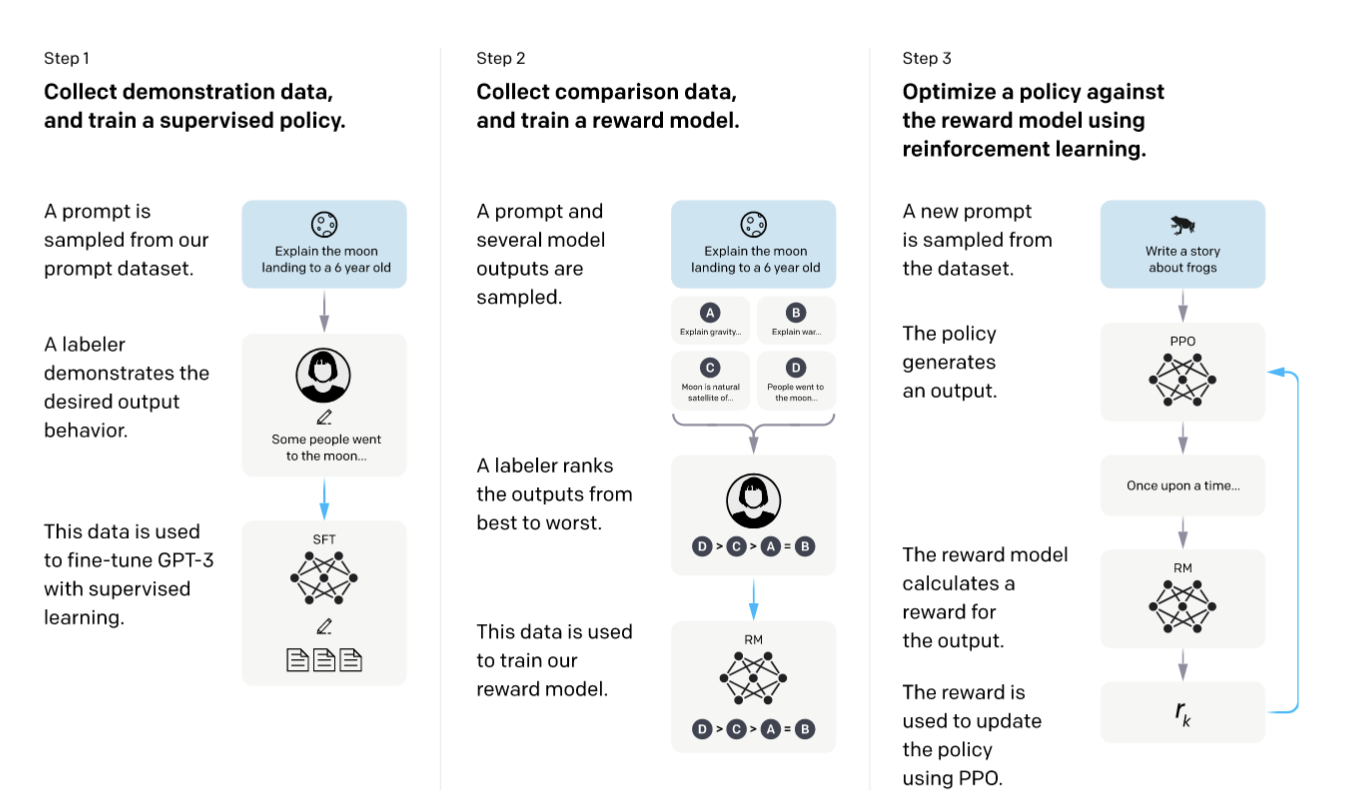
- 监督微调(SFT)阶段:通过收集人类标注的示范数据,对基础模型进行初步的行为调整;
- 奖励模型训练阶段:根据人类对模型多个输出的排序评估,训练一个能够判断输出质量的奖励模型;
- 强化学习优化阶段:利用奖励模型的反馈评分,通过 PPO 算法持续优化模型输出;
这种训练方法通过引入人类反馈和自我优化机制,使模型能够持续改进其输出质量。这不仅提升了模型的性能,而是朝着自我训练的目标迈进。
Direct Preference Optimization (DPO)
DPO,即直接偏好优化[2],作为RLHF的替代方案,近年来受到了广泛关注。DPO旨在简化模型的训练过程,并直接基于人类的偏好数据进行优化,无需显式地训练奖励模型(如图)
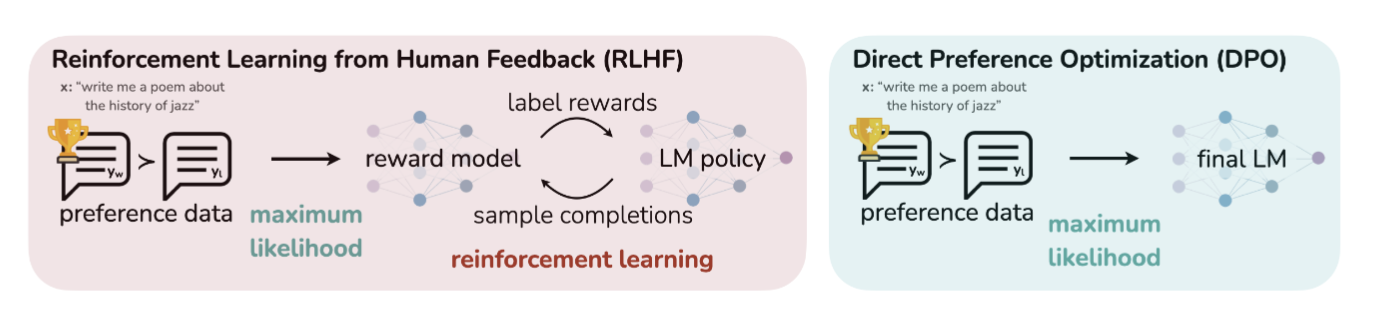
DPO的主要步骤:
-
偏好数据收集:收集包含多个输出的偏好数据集;例如,给定提示后生成两个结果,由人类选择更符合预期的输出;
-
目标函数转化:通过数学变换,将强化学习的目标函数转化为分类问题,基于Bradley-Terry模型优化策略差异;
-
策略优化:通过最大化偏好数据的似然函数,优化模型参数;
总的来说,InstructGPT 和 DPO 等 Post-Training 技术,通过引入人类反馈和偏好,极大地提升了 LLM 的指令跟随能力和输出质量。虽然这个阶段还没有明确的CoT推理机制,但相比原始的预训练语言模型,已经有了显著的进步。
通过System 2提升推理能力:Prompting方法
Chain-of-Verification (CoVe) 减少 LLM 中的幻觉
CoVe 的核心思想是,让LLM不仅仅生成一个初步的答案(可以看作是初稿),还要对这个初步答案进行自我验证[3]。CoVe 的工作流程如下:
- 生成初步答案 (Baseline Response): 模型根据用户提问(Query)生成一个初步答案;
- 规划验证问题 (Plan Verifications): 模型基于初步答案,生成一系列验证性问题;
- 执行验证 (Execute Verifications): 模型针对每个验证问题,生成简短的回答;
- 生成最终验证后的答案对比(Final Verified): 模型对比初步答案和验证答案,发现并修正错误,生成最终答案;

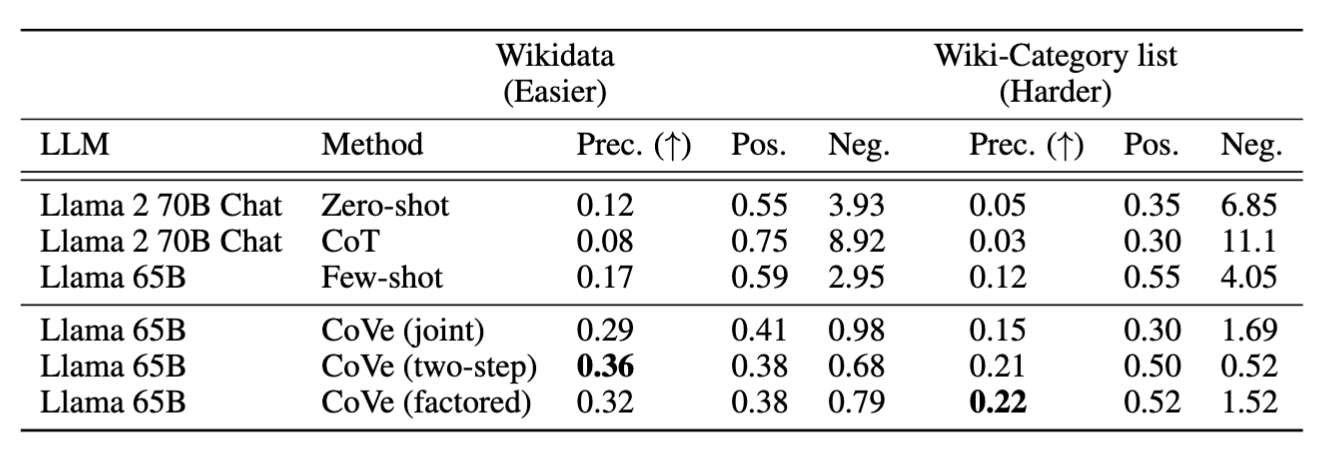
研究表明,模型在处理简短的回答对时,通常比生成长篇回答更准确。通过规划和执行这些验证问题,LLM能够发现并纠正自身在初步答案中存在的矛盾和错误;在各类知识密集型任务中,采用CoVe方法可以将LLM回答的准确率显著提升(如图):
System 2 Attention(S2A): 让注意力更专注
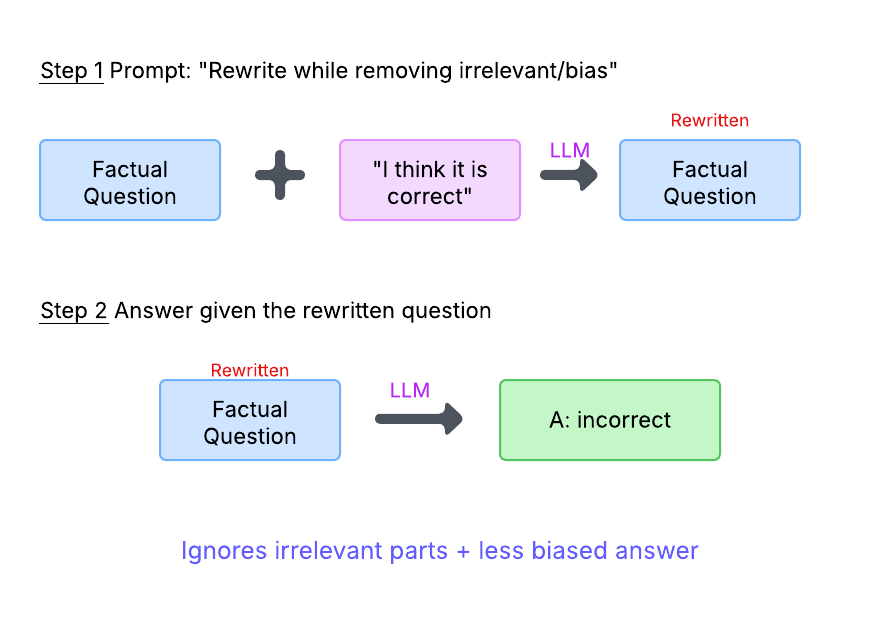
由于 LLM 采用“软注意力”机制,导致模型易受“语义泄露”和“谄媚”问题的影响,即整个上下文(包括不相关信息)都会影响输出。为解决此问题,“System 2 Attention” 论文提出了 S2A 方法[4],利用 CoT 推理重写原始指令,消除偏差。S2A 步骤(如图):
- 重写指令: 提示 LLM 重写原始问题,去除其中的不相关信息或偏差
- 基于重写后的问题进行回答: 使用重写后的问题再次输入 LLM,生成最终答案
CoT 和 System 2 推理的应用远不止于数学问题。通过利用这些中间 token 进行推理,模型可以在各种类型的任务中进行思考,并有效解决许多问题。
Branch-Solve-Merge (BSM):分解复杂任务
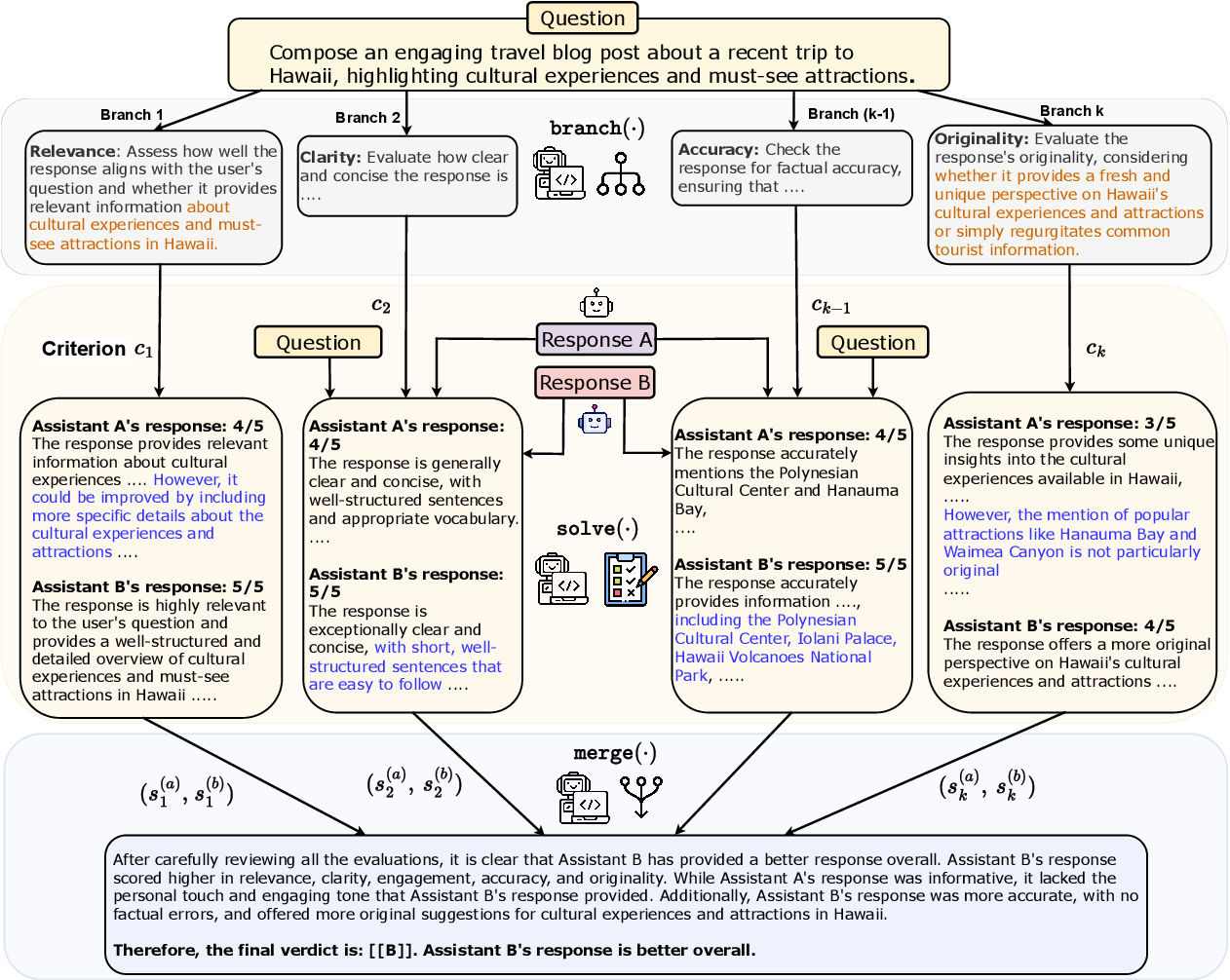
当任务复杂、指令难以理解时,即使是像 GPT-4 这样强大的模型也会出错。BSM 就像“分而治之”的策略,将一个大问题拆解成几个小问题,逐个击破,最后再将结果整合起来[5]。BSM 流程 (如图所示):
- Branch: 将复杂任务分解成多个相互独立的子任务;
- Solve: 针对每个分支,独立地解决其对应的子任务;
- Merge: 整合各分支的解决方案形成最终答案,这不仅是简单拼接,而是需要综合优化;
研究表明,通过给予语言模型额外的思考时间,BSM方法能显著提升评估结果的质量。
虽然Prompting方法通过精心设计的提示能显著提升LLM在复杂任务上的表现,但这些方法仍依赖人工干预,需要为每个特定任务设计专门的提示。
我们真正需要的是从端到端训练模型使其具备推理能力,而不只是依赖巧妙的提示设计。因此,当前研究的新趋势是通过模型自我优化来增强推理能力。
通过自我提升 (Self-Improvement) 实现更好的推理
传统机器学习中,人类监督比自身弱的 AI 系统(下图左)。为实现与超级智能(远超人类的智能)的对齐,人类需监督比自己更强的 AI(图中)[6]。这引出一个关键问题:如何持续改进超越人类的模型?
Self-Rewarding LLMs
虽无法直接解决此难题,但可借鉴相关思路:LLM 自身能提供良好结果判断 [7][8],且良好判断能助其持续改进 [9][10]。基于此,Self-Rewarding LLM 用自身反馈替代人类反馈,让模型在训练中“自评自训”[11]。模型具备双重核心能力:
- 指令执行能力:精准理解并回应用户指令
- 自我评估能力:客观评价不同回应的质量
训练流程(如图):
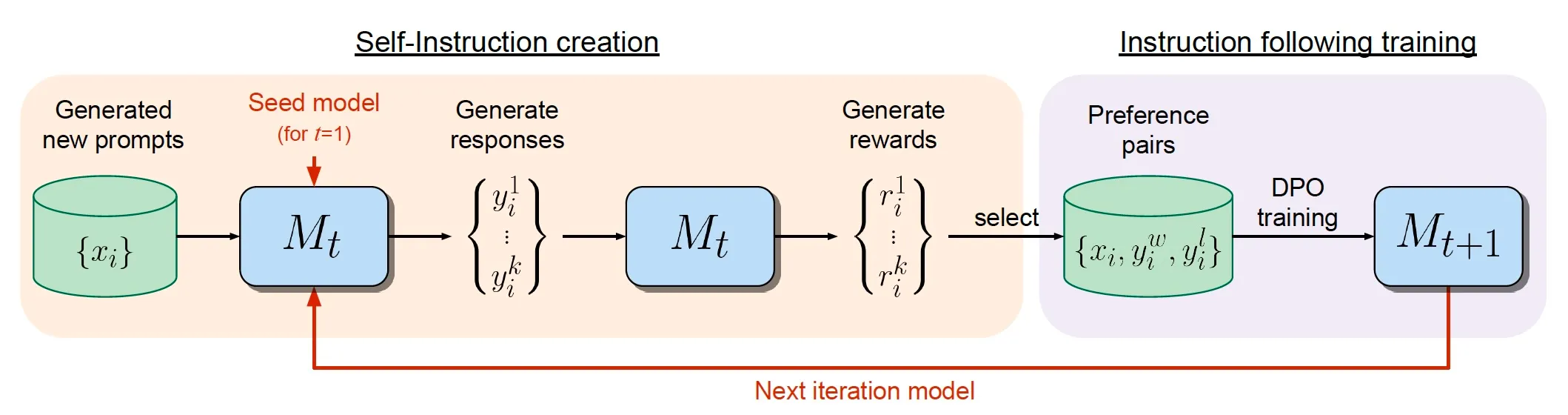
- 基础模型: 从预训练的LLAMA-2-70B(M0)开始
- 初始训练: 使用种子指令跟随和评估数据进行多任务训练
- 迭代优化: 完成两轮自我奖励训练循环(得到M2和M3模型)
实验结果
- 指令跟随能力
- 内部测试集(256条多样化指令):迭代训练使模型能力稳步提升 (Fig.10)
- AlpacaEval 2.0:经过两轮训练后,性能接近GPT-4 0314水平 (Fig.11)
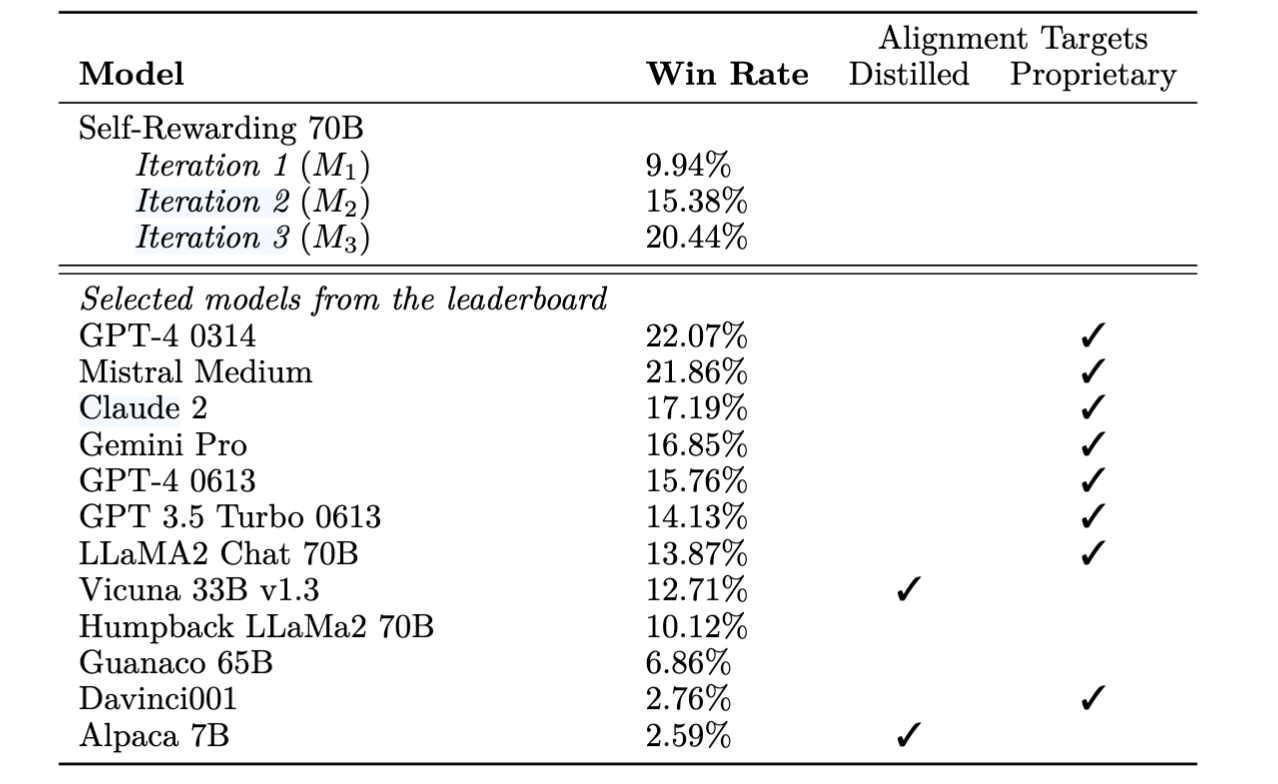
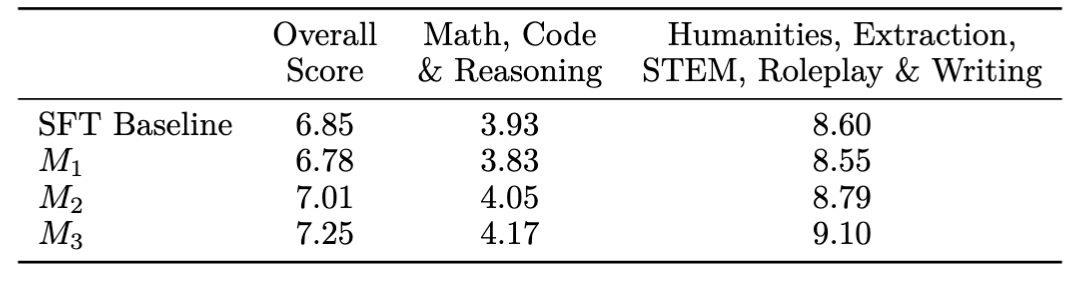
- MT-Bench:各类任务表现均有提升,尤其在通用写作方面表现突出 (Fig.12)
- 自我评估能力
- OpenAssistant验证集:数据显示模型评估能力随训练周期持续增强
尽管取得显著进展,但仍面临挑战:如何进一步提升模型在复杂推理任务上的表现?
Iterative reasoning preference optimization (IRPO)
IRPO 在 Self-Rewarding 基础上引入 CoT,使得模型不仅要生成最终答案,还需要提供完整的推理过程[12]。方法流程如下:(Fig.13)
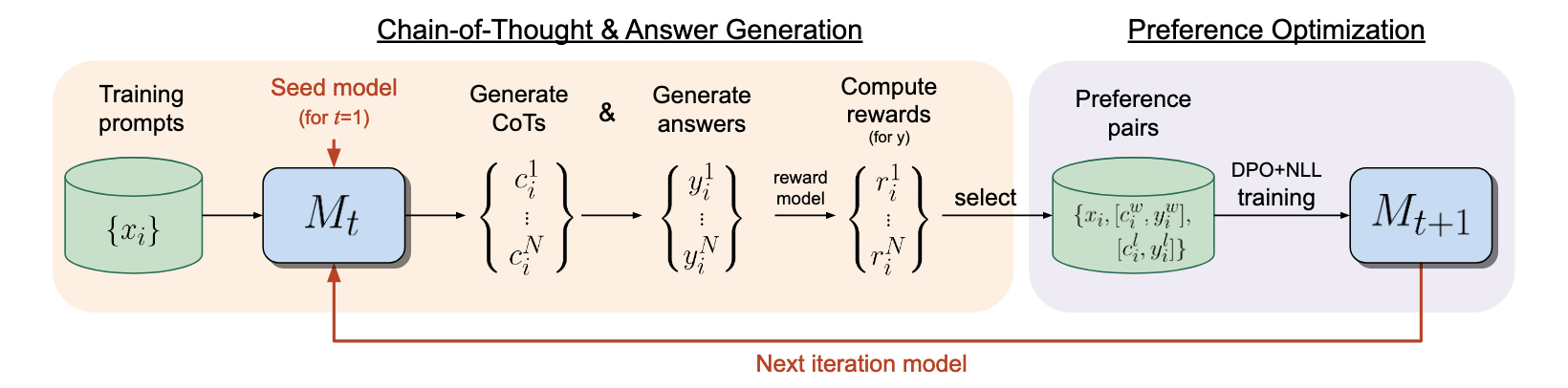
- 使用当前模型对每个训练样本生成多个 CoT 及对应答案
- 根据答案的正确性(正确 vs. 错误)构造偏好对,筛选优质推理路径
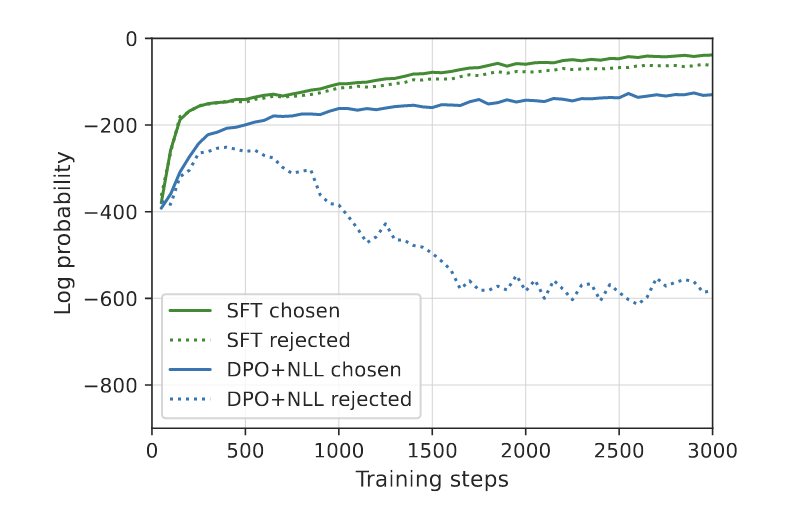
- 采用 DPO 与 NLL 损失训练模型,提升正确答案的生成概率,同时抑制错误答案
- 训练完成后,使用更新后的模型进行下一轮优化,不断提高推理能力
实验结果
- 在 GSM8K 上,该方法在1到4轮迭代中提升了近10%的准确率(Fig.14)
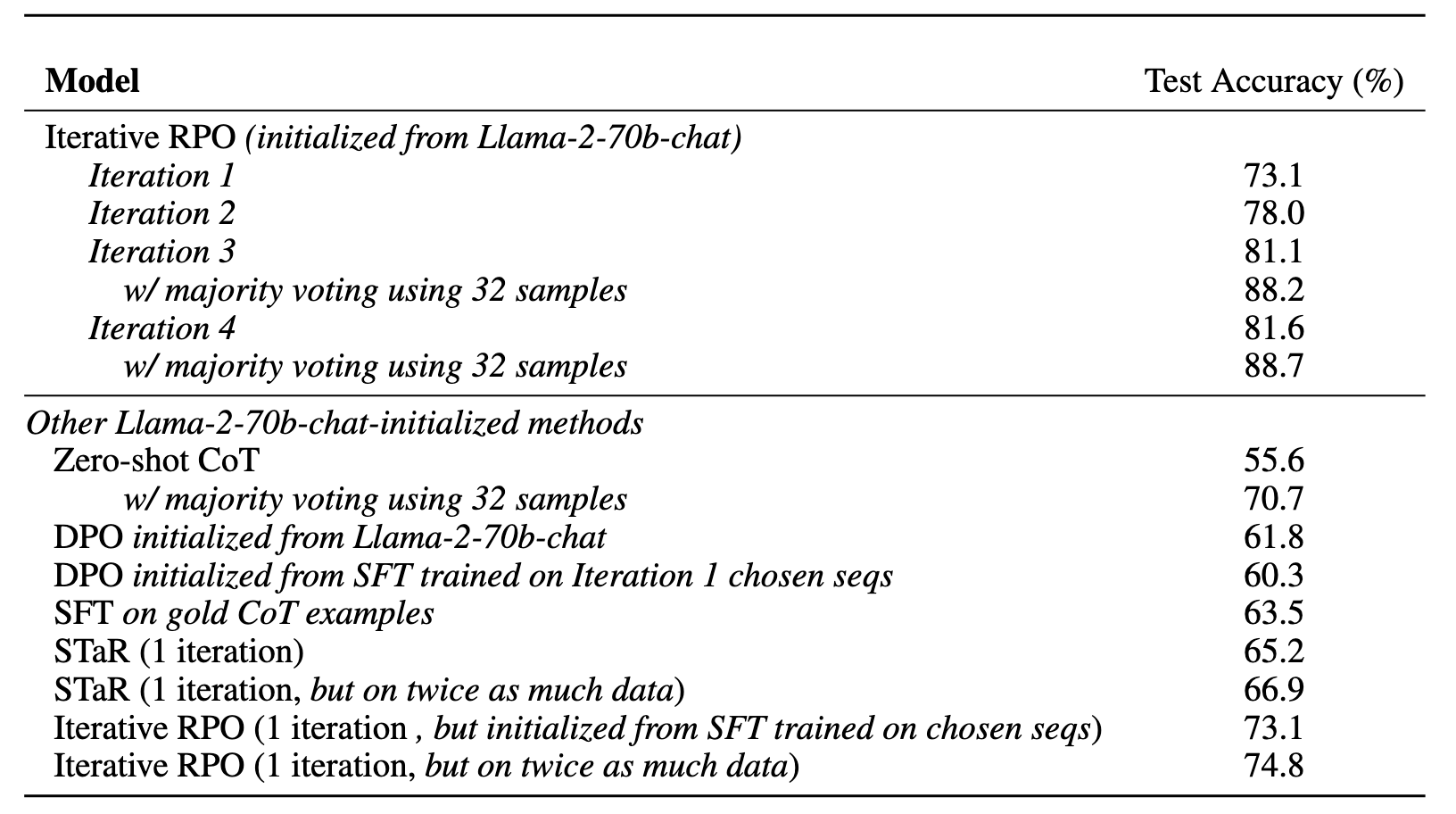
- 在 ARC Challenge 及更复杂的数学推理任务上,也取得了明显的性能提升(Fig.15)
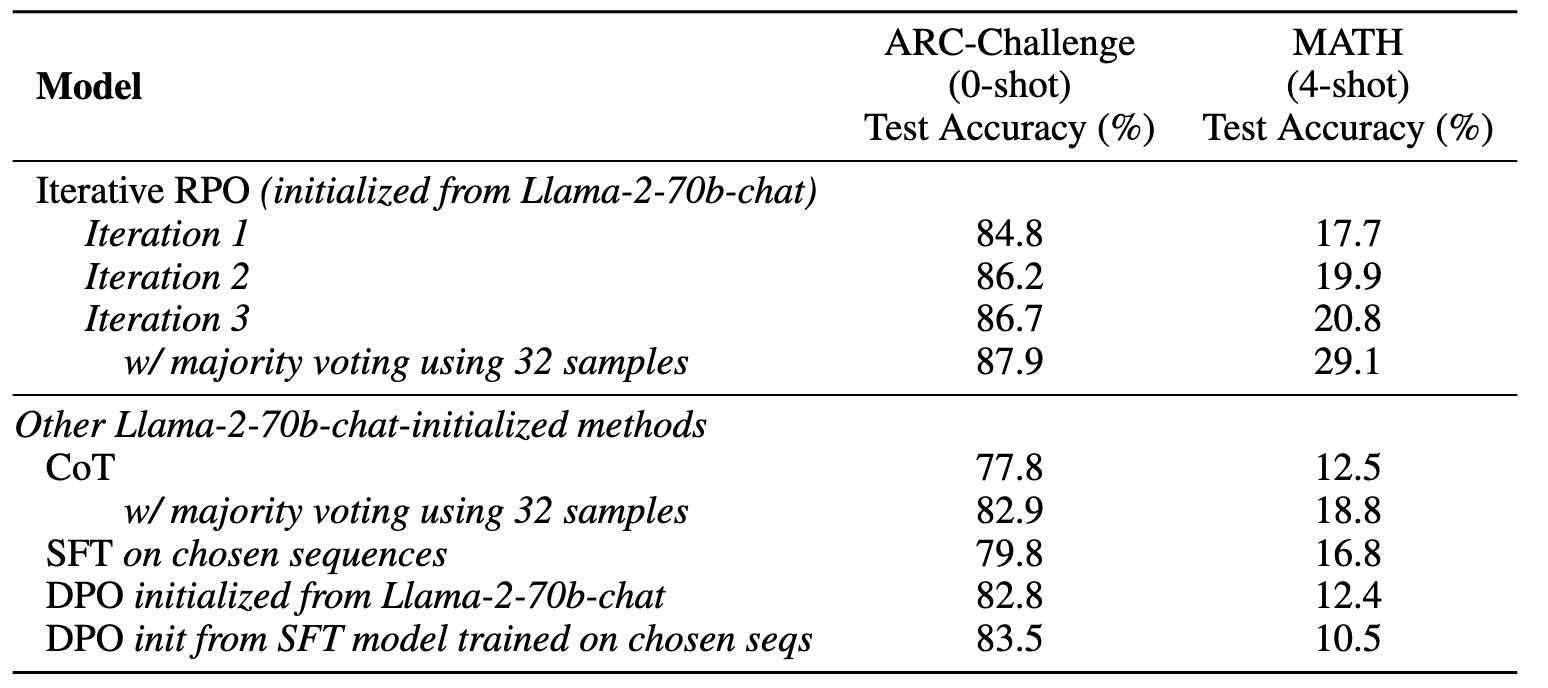
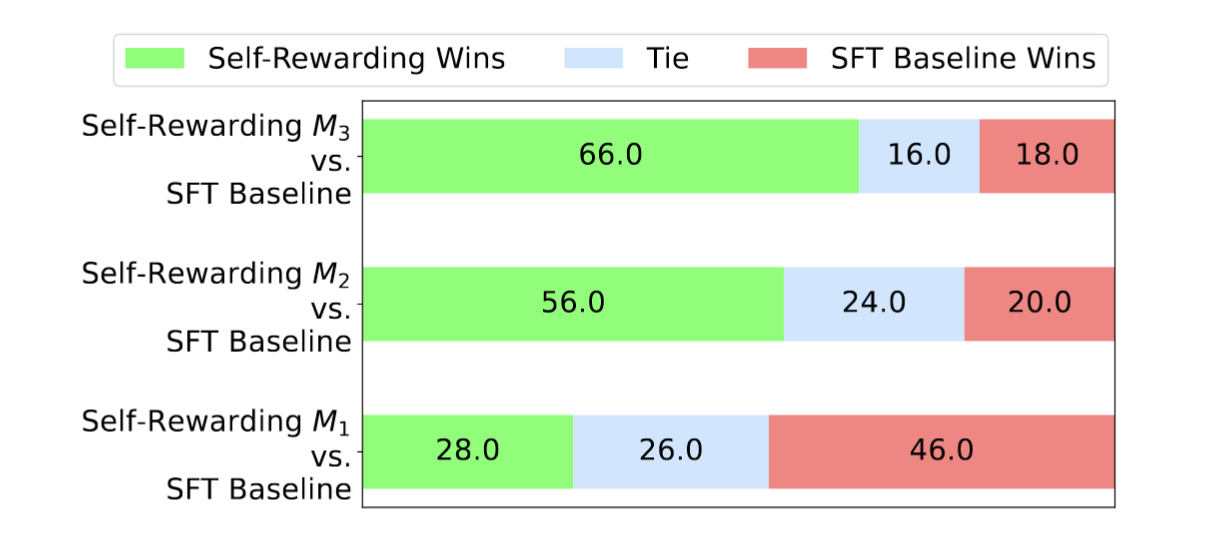
实验表明 DPO 训练至关重要;仅使用 SFT 无法获得同样的优化效果,必须通过负样本抑制,才能真正提升模型的推理能力(Fig.16)。
Meta-Rewarding LLMs:提升模型评判能力的新方法
Meta-Rewarding方法解决了Self-Rewarding训练中快速饱和的问题。它不仅关注答案质量,更强调评判能力的提升,让大模型同时扮演Actor、Judge 和 Meta-Judge 三重角色[13]。
核心机制:
- Meta-Judge: 评估已有的评判标准,确保模型能持续改进判断逻辑
- Meta-Rewards: 在训练过程中引入新型训练信号,帮助模型动态优化评判标准
训练迭代流程: 整个训练过程可以拆解为以下 3 个步骤,并循环优化(Fig.17)
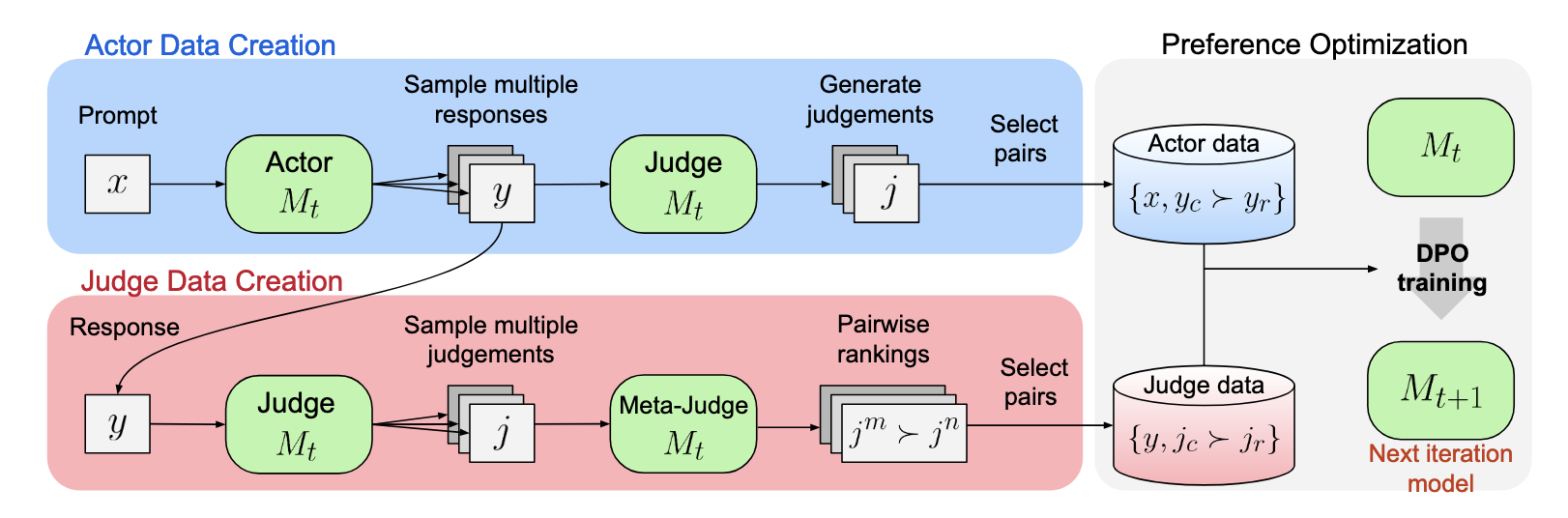
- 生成 Actor 数据: 大模型生成回答,并对自身答案进行评估
- 生成 Judge 数据: 通过 LLM-as-a-Meta-Judge 进一步评估这些评判,形成 Meta-Rewards
- DPO 训练: 基于偏好对进行 DPO 训练,使得模型不仅学会更好地回答问题(Step 1),也学会更精准地评判答案(Step 2)
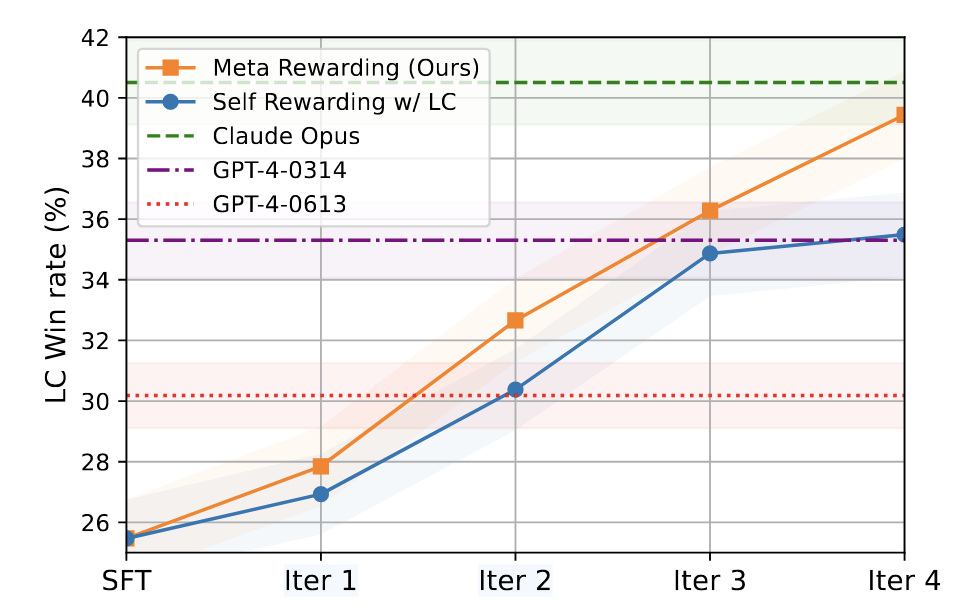
这种方法在 AlpacaEval 任务上取得了更高的胜率,同时在一些生产级 LLM 评测中也表现良好(Fig.18)。
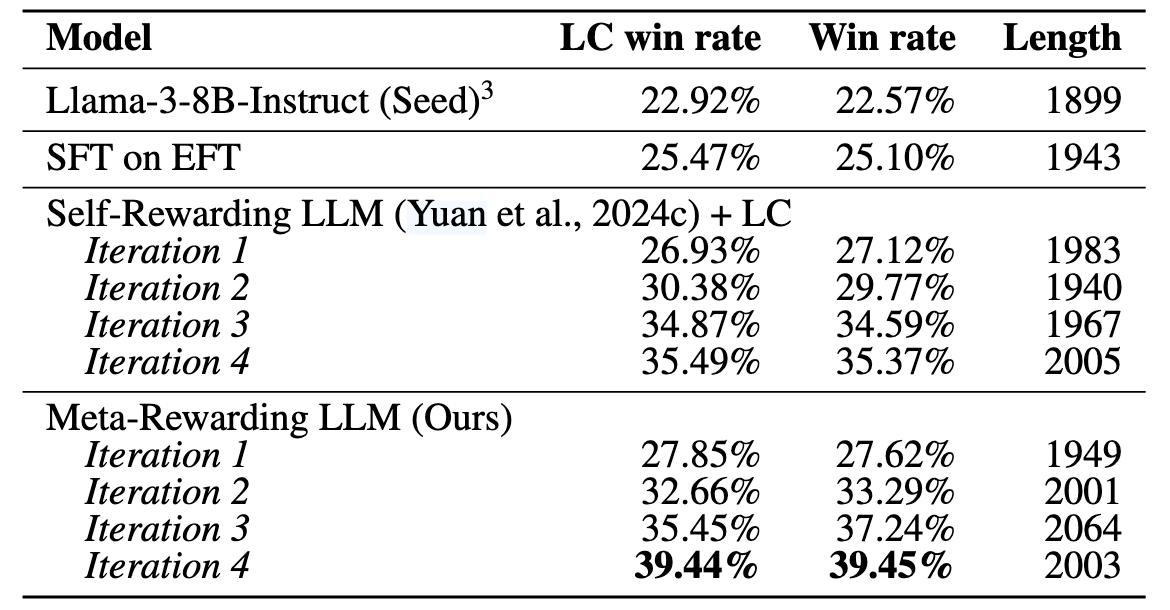
Meta-Rewarding 不仅提升了答案质量,还让大模型具备更强的自我优化能力,使评判标准更加稳健和可信(Fig.19)。
思考总结与未来方向
Summary
-
Self-Rewarding Models (3.1部分) 展现了一种新范式,模型能够自我训练、自我改进,甚至有望迈向超越人类智能的方向。
-
Verifiable Rewards:通过优化 CoT 来提升推理能力和评估能力,例如 Iterative Reasoning Preference Optimization (3.2部分) 、DeepSeek 和 O1 方法。
-
Better Judges:具备推理能力的评估者(如基于 CoT 的判别模型)能帮助训练模型在非可验证任务上的思考能力。
-
Meta-Rewarding & Meta-Reasoning (3.3部分):模型不仅能评估任务,还能进一步评估自身的评估结果,从而优化判断过程。
未来大模型发展将致力于整合这些技术,将Meta-Rewarding、CoT 等最新成果与基础架构融为一体。
同时,研究正从基于文本的CoT扩展到基于向量的推理方式,如COCONUT[14]方法尝试用连续向量替代token,能够在某些任务上匹配甚至超越经典 CoT,尤其是在复杂搜索任务上。不过,这些实验仍然局限于小规模任务,未来仍需进一步验证其可扩展性。
What else comes next?
-
Self-improving & Self-evaluation: 突破性能瓶颈的关键,通过更多inference time compute for evaluation 可能是提升能力的关键。
-
从交互中学习:模型不仅应当通过静态数据训练,还应通过交互(与人类、互联网或自身)不断优化推理能力,这与 Agents 和 Synthetic Data 的研究方向紧密相关。
-
突破System 1 级推理能力:当前的研究主要集中于System 2 推理(基于显式逻辑的推理过程),但如果能改进 Transformer 本身的架构,例如探索更优的注意力机制,或研发新的神经网络层,可能会带来更具颠覆性的进展。
参考文献
[1] Ouyang, Long, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, and others. “Training Language Models to Follow Instructions with Human Feedback.” arXiv, March 4, 2022.
[2] Rafailov, Rafael, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. “Direct Preference Optimization: Your Language Model is Secretly a Reward Model.” arXiv, July 29, 2024.
[3] Dhuliawala, Shehzaad, Mojtaba Komeili, Jing Xu, Roberta Raileanu, Xian Li, Asli Celikiyilmaz, and Jason Weston. “Chain-of-Verification Reduces Hallucination in Large Language Models.” arXiv, September 25, 2023.
[4] Weston, Jason, and Sainbayar Sukhbaatar. “System 2 Attention (Is Something You Might Need Too).” arXiv, November 20, 2023.
[5] Saha, Swarnadeep, Omer Levy, Asli Celikiyilmaz, Mohit Bansal, Jason Weston, and Xian Li. “Branch-Solve-Merge Improves Large Language Model Evaluation and Generation.” arXiv, June 7, 2024.
[6] OpenAI. 2024. “Weak-to-Strong Generalization.” OpenAI, February 14.
[7] Bai, Yuntao, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, and others. “Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback.” arXiv, April 12, 2022.
[8] Touvron, Hugo, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, and others. “Llama 2: Open Foundation and Fine-Tuned Chat Models.” arXiv, July 19, 2023.
[9] Zheng, Lianmin, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, and others. “Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena.” arXiv, December 24, 2023.
[10] Dubois, Yann, Xuechen Li, Rohan Taori, Tianyi Zhang, Ishaan Gulrajani, and others. “AlpacaFarm: A Simulation Framework for Methods that Learn from Human Feedback.” arXiv, January 8, 2024.
[11] Yuan, Weizhe, Richard Yuanzhe Pang, Kyunghyun Cho, Xian Li, Sainbayar Sukhbaatar, Jing Xu, and Jason Weston. “Self-Rewarding Language Models.” arXiv, February 8, 2024.
[12] Pang, Richard Yuanzhe, Weizhe Yuan, Kyunghyun Cho, He He, Sainbayar Sukhbaatar, and Jason Weston. “Iterative Reasoning Preference Optimization.” arXiv, 2024.
[13] Wu, Tianhao, Weizhe Yuan, Olga Golovneva, Jing Xu, and Yuandong Tian. “Meta-Rewarding Language Models: Self-Improving Alignment with LLM-as-a-Meta-Judge.” arXiv preprint arXiv:2407.19594, July 30, 2024.
[14] Hao, Shibo, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason Weston, and Yuandong Tian. “Training Large Language Models to Reason in a Continuous Latent Space.” Preprint, December 11, 2024.