Introduction
To understand LLM agents, we need to break the term into two foundational components: Large Language Models (LLMs) and Agents. While LLMs have gained widespread recognition, the concept of “agent” in this context requires deeper exploration.
What is an Agent?
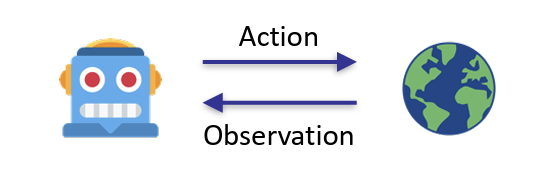
In artificial intelligence, an agent is an “intelligent” system that perceives and interacts with an “environment” to achieve specific goals. The classification of agents varies based on their operational environment:
- Physical environments: robots, autonomous vehicles, etc.
- Digital environments: DQN for Atari games, Siri, AlphaGo
- Humans as environments: Chatbots
Agents typically follow a perception-reasoning-action cycle, where they:
- Observe their environment
- Process information and make decisions
- Take actions that affect the environment
What’s an LLM Agent?
An LLM agent integrates the powerful language capabilities of LLMs with the goal-oriented, interactive nature of agents. These systems represent a significant evolution in AI, with capabilities ranging from basic conversational skills to complex reasoning and planning.
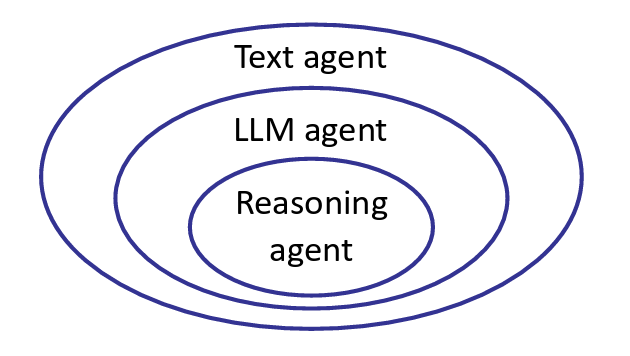
LLM agents can be classified into three progressive levels of sophistication:
Level 1: Text Agent
- Basic agents that process and respond to text input
- Examples: ELIZE, LSTM-DQN
Level 2: LLM Agent
- Advanced agents that leverage LLMs for direct action generation
- Examples: SayCan, Language Planner
Level 3: Reasoning Agent
- Use LLM to reason to act
- Examples: ReAct, AutoGPT
Pre-LLM Language Agents
ELIZA (1966): The Pioneer of Text Agents
The development of text-based agents dates back to the early days of AI. ELIZA, created in 1966, marked a significant milestone as one of the first chatbots.
It’s simple yet effective rule-based approach involved pattern matching and response templates to simulate human conversation. While users found ELIZA remarkably engaging, the system had inherent limitions:
- Limited to specific domains and use cases
- Require a extensive manual rule creation
- Unable to handle complex interactions or understanding
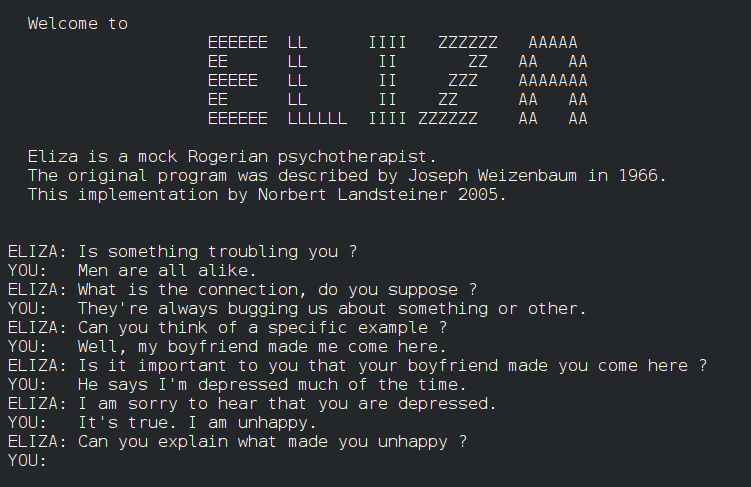
Despite these constraints, ELIZA established the conceptual foundation for future conversational agents and demonstrated the potential of natural language interfaces.
LSTM-DQN (2015): Reinforcement Learning for Text Agents
Prior to the emergence of LLMs, RL was a dominant approach for developing text-based agents. This methodology treated text as both the observation and action space, similar to how traditional RL handles pixels and keyboard inputs in video games. The core idea was that optimizing for reward signals would natually lead emergence of language intelligence[1].
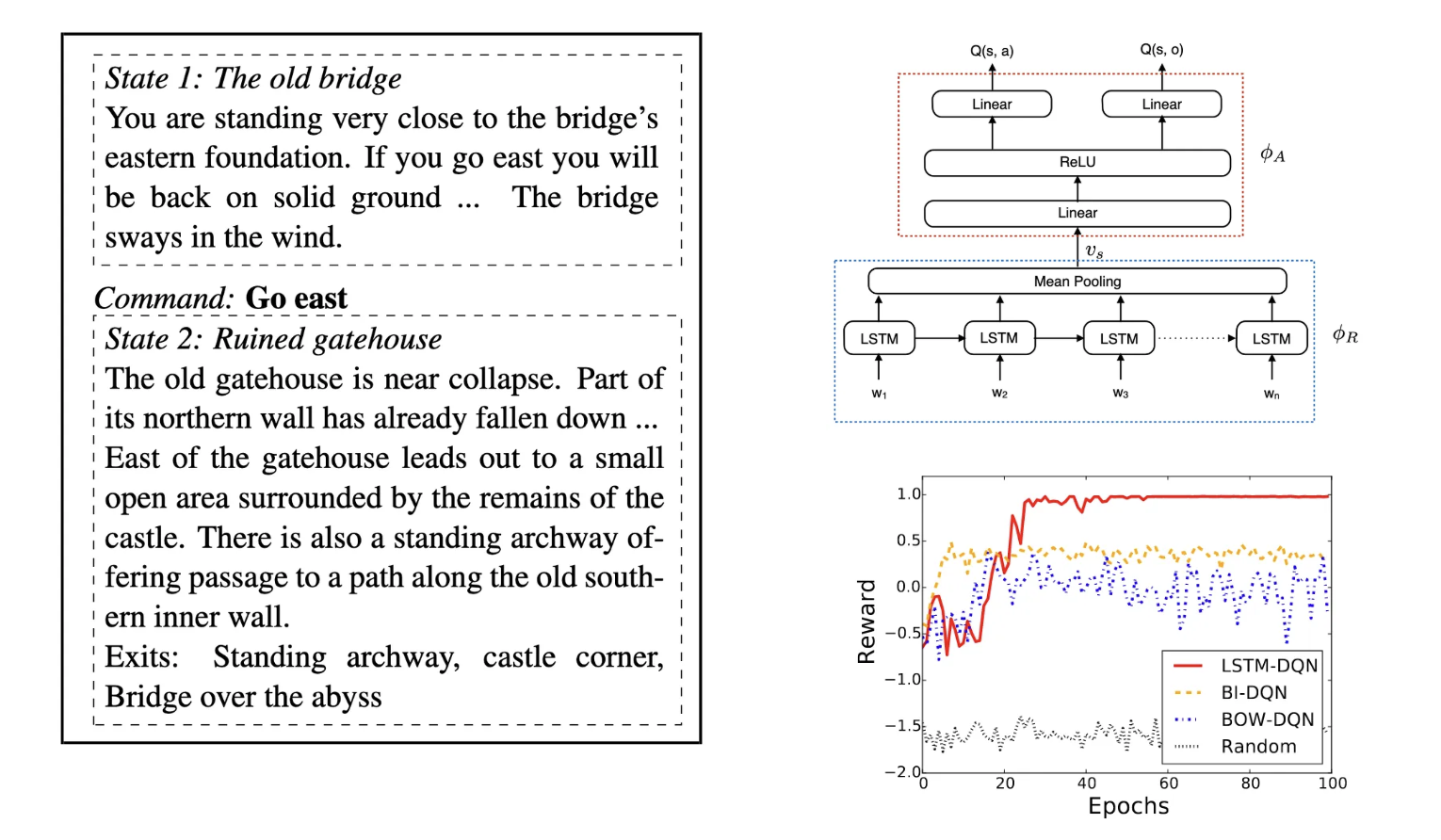
However, this approach faced several significant limitions:
- Domain-specific applications
- Dependence on explicit scalar reward signals
- Requires extensive training
These early approaches highlighted both the promise and challenges of creating intelligent text-based agents, setting the stage for the transformative impact that large language models would later bring to this field.
The Emergence of Large Language Models
LLMs have revolutionized text agents through next-token prediction on massive text corpora. During inference, they solve diverse new tasks through prompting alone[2]. This emergent generality creates exciting possibilities for building more capable agents.
A Brief History of LLM Agents
The rise of LLM agents began with models like GPT-3 in 2020. Initially, researchers explored their potential across diverse tasks, which broadly fell into two categories:
- Reasoning tasks: such as symbolic question answering and logical inference
- Acting tasks: including interactive applications like games and robotics
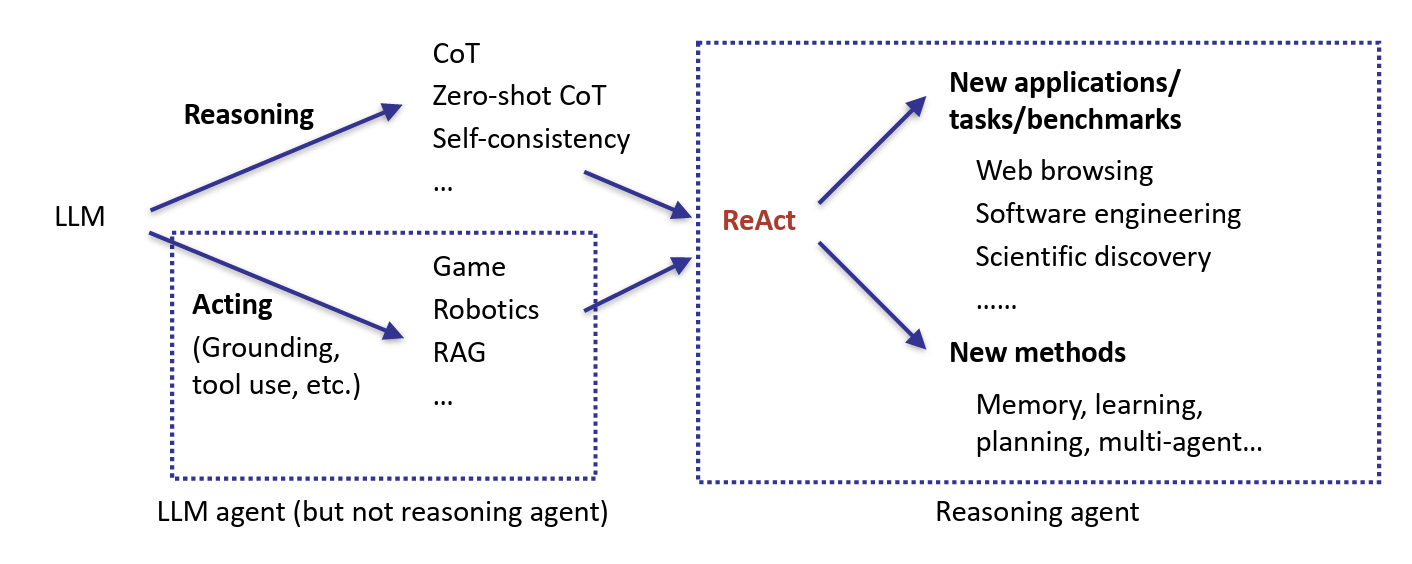
Over time, reasoning and acting converged, giving rise to reasoning agents—models that combine structured thinking with goal-driven actions. This led to two key research directions:
- Applications: Web interaction, software engineering, scientific discovery, and more
- Methods: Memory systems, planning, multi-agent collaboration, and adaptive learning
Enhancing LLMs with External Knowledge and Computation
While LLMs excel at many tasks, some require more than just next-token prediction—they demand reasoning, external knowledge, or computation. To address these limitations, researchers have developed various techniques.
(1) Code-Augmented Computation
For tasks involving calculations or formal reasoning, LLMs can generate code instead of directly predicting an answer. The generated code is then executed to produce the final result[3].
Example: Prime factorization, Fibonacci sequences
(2) Retrieval-Augmented Generation (RAG) for Knowledge
For knowledge-intensive queries, LLMs can retrieve relevant information from external corpora before generating a response[4]. This is typically using:
- Extra corpora
- A retriever (e.g., BM25, DPR, etc.)
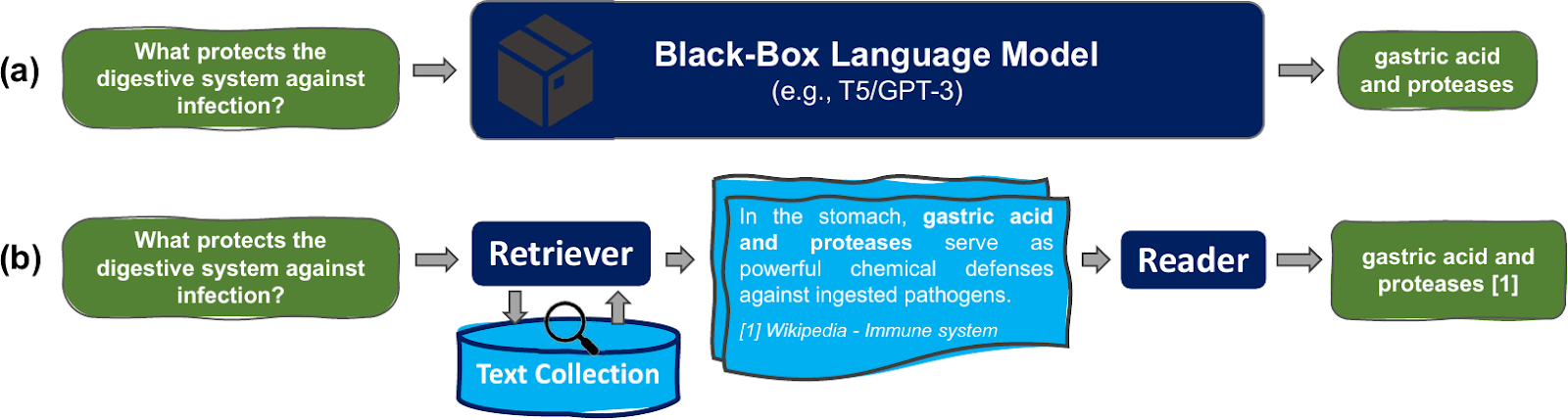
Limitation: RAG depends on the availability of a relevant corpus. If the needed information is missing (e.g., “Who is the latest Prime Minister?”), retrieval alone is insufficient.
(3) Tool-Use for Dynamic Information
When static corpora fall short, LLMs can invoke external tools in real time. This is achieved by introducing special tokens that trigger API calls[5][6]. Common tools include:
- Search engine, calculator, etc.
- Task-specific models (translation)
- APIs
This approach significantly expands capabilities but introduces new challenges in tool selection and interaction management.

What if both knowledge and reasoning are needed?
Many tasks require both reasoning and external knowledge, pushing researchers to develop hybrid approaches. For example, one can interleave retrieval with chain-of-thought reasoning[7] or generate follow-up queries to refine responses[8].
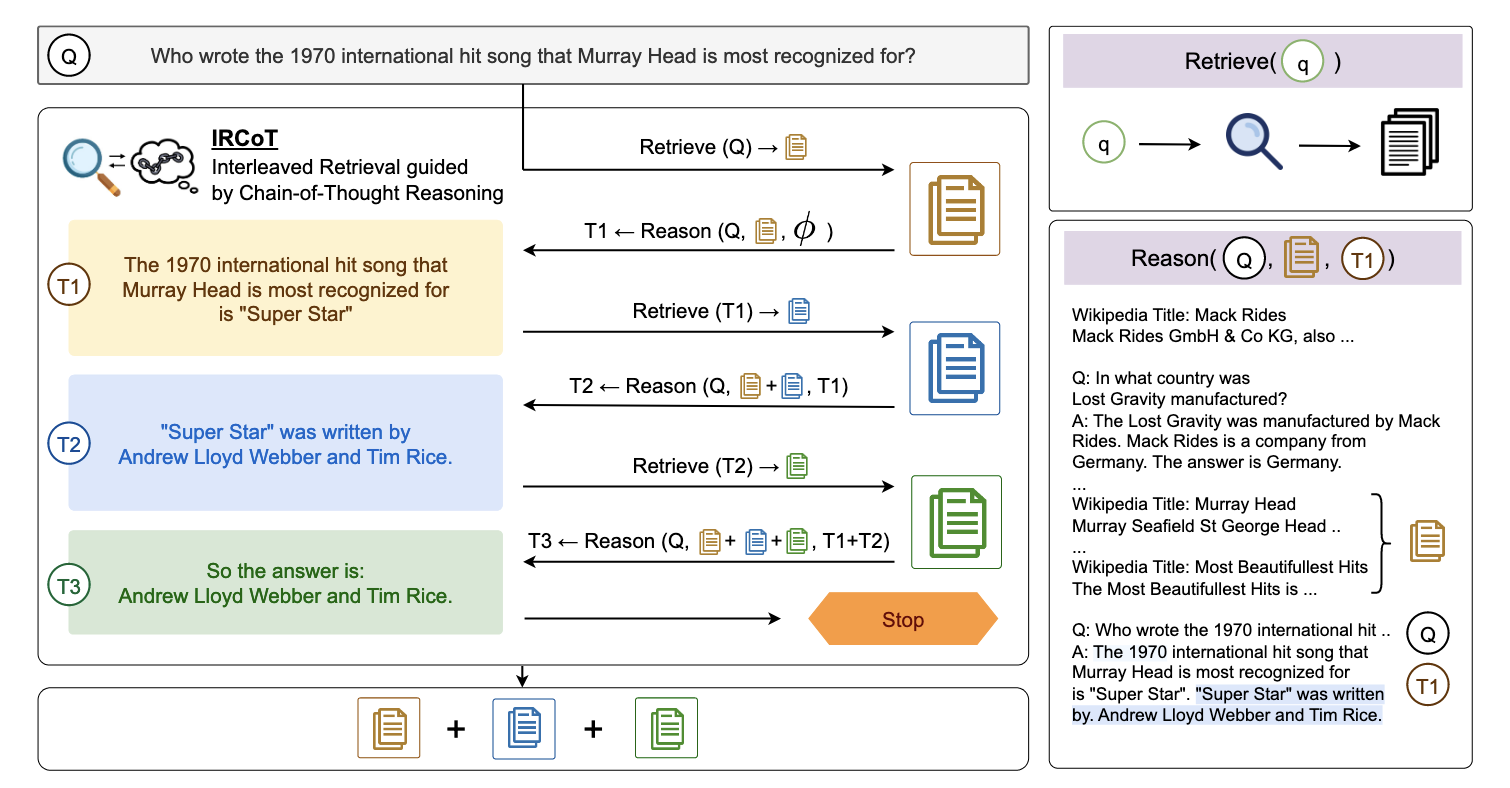
However, early solutions were fragmented. Even within a single task like QA, different benchmarks posed distinct challenges, leading to a proliferation of task-specific techniques.
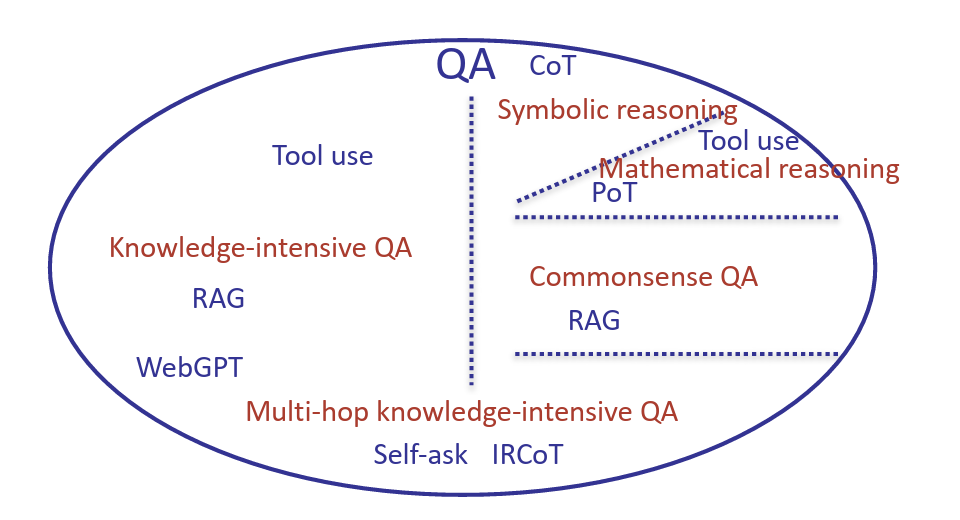
To achieve generality, we need a framework that integrates knowledge retrieval with structured reasoning.
ReAct: A Unified Framework for Reasoning and Action
Prior approaches to LLM agents faced a fundamental divide: reasoning-focused methods lacked external information, while action-focused methods lacked structured thinking[9].
The Core Idea of ReAct
ReAct integrates reasoning and action paradigms into a unified framework, allowing language models to generate both simultaneously rather than in isolation. Key advantages include:
- Synergy of reasoning and acting
- Simple and intuitive to use
- General across domains
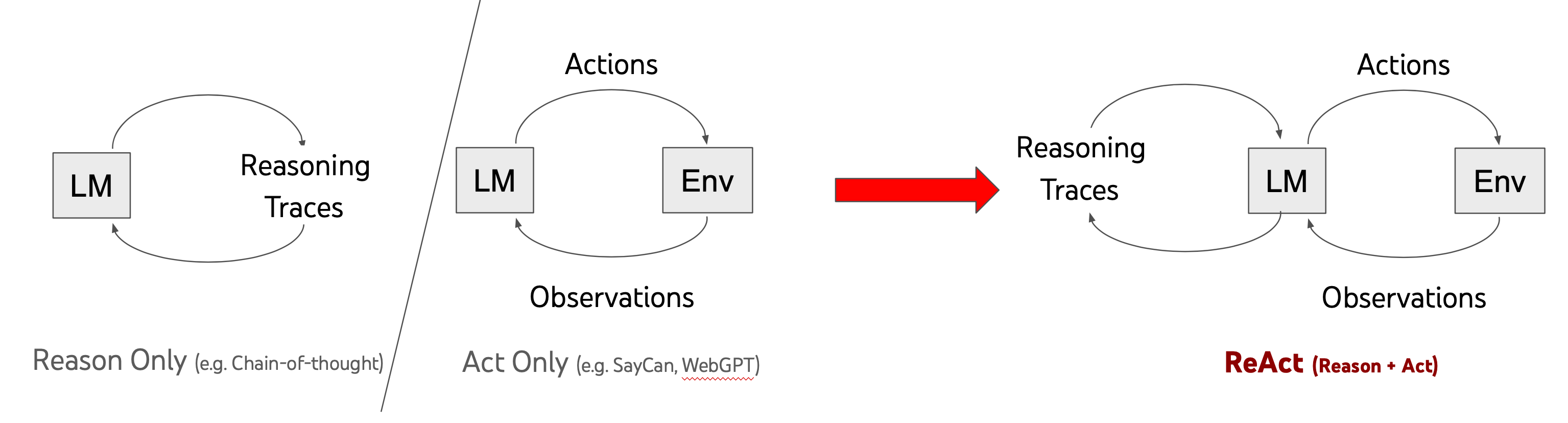
How ReAct Works
A ReAct agent follows an iterative reasoning-action loop until reaching a final conclusion:
- Generate Thought: break down the problem and decide on the next step.
- Take Action: query a retrieval system, execute code, or call an external API.
- Observe Outcome: analyze the retrieved data or computed result.
- Repeat: use the new information to generate the next thought and action.
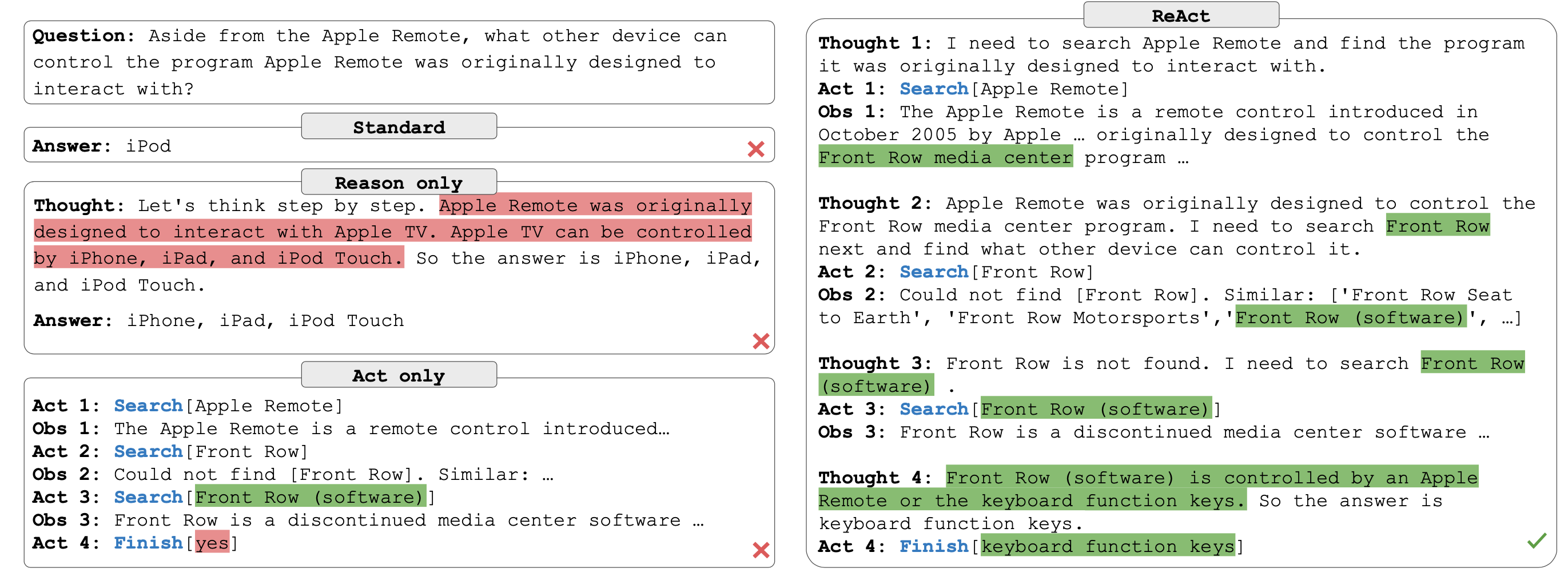
Implementation approaches:
- One-shot prompting
- Few-shot prompting
- Fine-tuning
ReAct Enables Systematic Exploation
At the heart of this approach is the concept of treating reasoning as an action, which expands the action space of AI agents. This enables them to explore complex tasks in a more systematic way.
ReAct outperforms standard prompting methods with just a few examples, approaching or even exceeding the performance of supervised learning across multiple tasks:
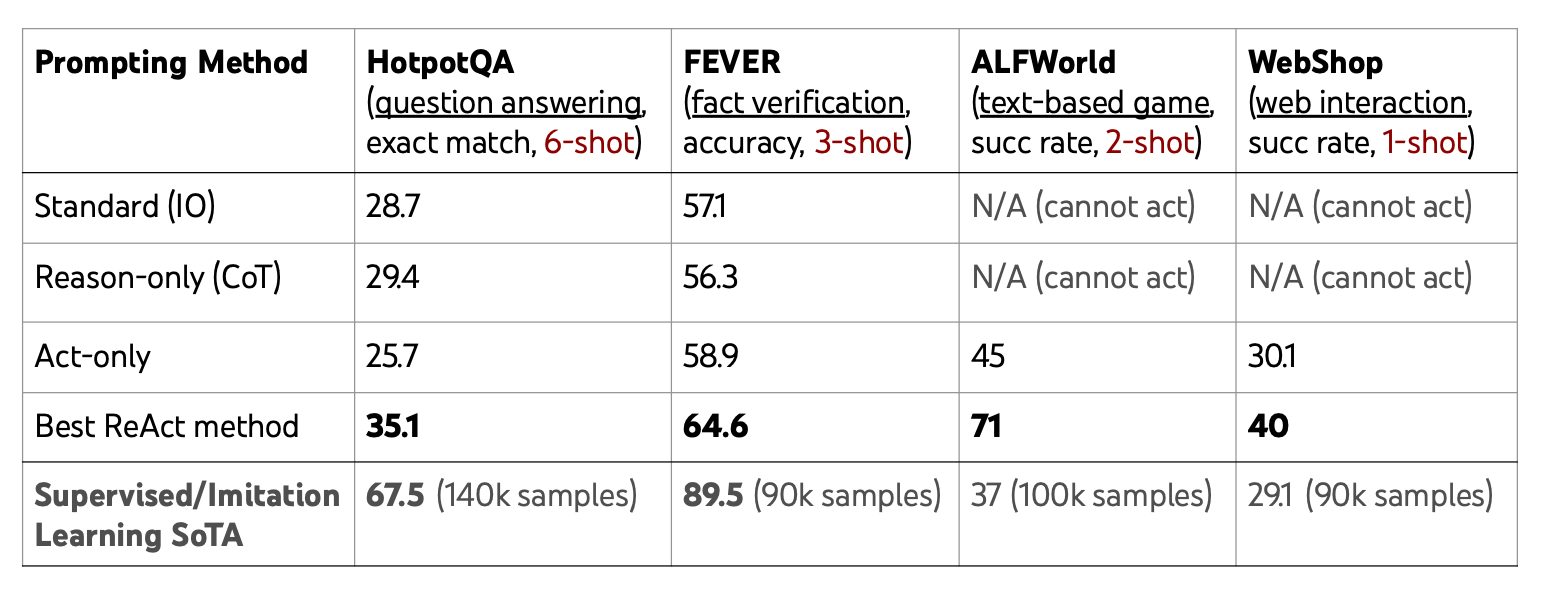
Unlike traditional AI agents constrained by the environment, ReAct agents can not only perform external actions but also reason actively, breaking free from fixed action sets. This allows for unlimited expressiveness, influencing decision-making without altering the external world.
Long-term Memory: Expanding Agent Capabilities Beyond the Context Window
Building upon the ReAct framework’s integration of reasoning and action, we now explore how agents can overcome the fundamental limitations of their working memory through effective long-term memory systems.
Short-term Memory vs. Long-term Memory
An agent’s short-term memory is limited to the language model’s context window. While this allows it to dynamically add thoughts, actions, and observations, it comes with significant constraints:
| Short-term Memory | Long-term Memory |
|---|---|
|
- Append-only - Limited context - Limited attention - No persistence across tasks |
- Read and write - Stores experience, knowledge, skills - Persists over new experiences |
Short-term memory is like a goldfish with its legendary three-second memory - an agent might solve remarkable problems but must start from scratch the next time. This limitation motivates the need for long-term memory systems.

Reflexion: A Simple Form of Long-term Memory
Reflexion builds directly upon ReAct by adding a memory layer that enables agents to learn from past experiences[10]. The process works as follows:
- Task: The agent attempts to solve a problem
- Trajectory: The agent follows a reasoning-action path toward a solution
- Evaluation: The solution is tested against success criteria
- Reflection: The agent analyzes its performance, identifying strengths and weaknesses
- Next Trajectory: The agent incorporates these reflections into future attempts
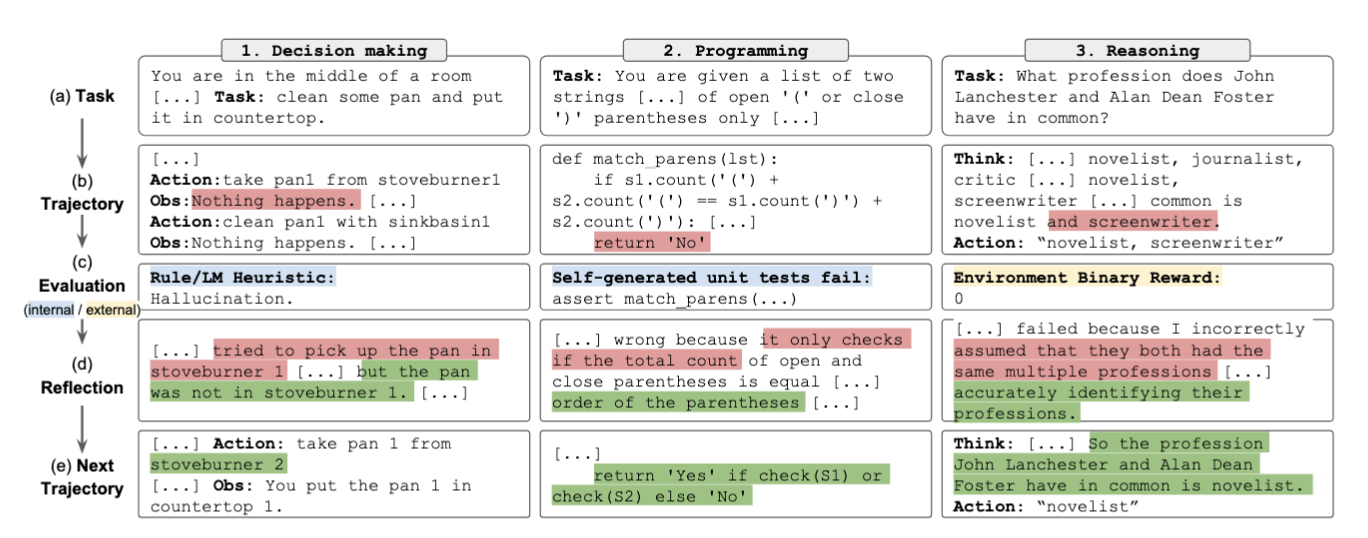
This approach proves particularly effective for coding tasks, where clear feedback from unit tests creates ideal learning conditions.

Traditional RL vs. Reflexion
Another way to understand Reflexion is through its contrast with traditional reinforcement learning approaches. RL relies on sparse scalar rewards and weight updates for learning. In contrast, Reflexion introduces a more direct, language-driven learning process:
| Traditional RL | Reflexion: “Verbal” RL |
|---|---|
| - Learns via scalar rewards (sparse feedback) - Learns by updating weights (credit assignment) |
- Learns via text feedback - Learns by updating language (a long-term memory of task knowledge) |
By leveraging explicit textual feedback, Reflexion allows agents to iteratively refine their reasoning and decision-making, creating interpretable knowledge that persists as long-term memory for future tasks without requiring weight adjustments.
Agent Architecture
Unified Perspective on Agents
The final step in understanding agent architecture is recognizing that language itself functions as a form of long-term memory. Agents can improve their capabilities through two complementary mechanisms:
- Neural Adaptation: Updating the parameters of the language model through fine-tuning.
- External Memory: Storing and retrieving knowledge in structured textual or symbolic formats.
By viewing both neural networks and external text repositories as forms of long-term memory, we arrive at unified abstraction of learning. This perspective emphasizesthe agent’s ability to reason over short-term memory while maintaining persistent long-term memory that extends beyond the current task. As demonstrated in CoALA[11], any agent can be expressed through three fundamental components:
- Memory: Where information is stored
- Action Space: What the agent can do
- Decision-making procedure: How the agent selects actions based on memory and capabilities
This framework provides a sufficient and comprehensive way to conceptualize agent system of any complexity.
A Brief History of Agents
Looking beyond LLM agents specifically, we can place agents in the borader historical context of AI development. While simplified, this timeline illustrates shifts in agent architectures:
| Era | Agent Paradigm | Representation | Characteristics |
|---|---|---|---|
| Early AI | Symbolic AI | Rule-based logical expressions | • Programmed rules for environment interaction • Expert systems • Intensive design effort • Task-specific |
| Post-AI Winter | Deep RL | Neural embeddings/vectors | • Data-driven learning • Breakthroughs like Atari, AlphaGo • Millions of training steps • Limited generalization |
| Recent | LLM Agents | Natural language | • Language as intermediate representation • Rich priors from pre-training • Inference-time scalability • General and generalizable |
The fundamental difference between these paradigms lies in how they transform observations into actions:
- Symbolic AI agents map observations to symbolic states, then apply logical rules to determine actions
- Deep RL agents convert observations into neural embeddings, processed through networks to produce actions
- LLM agents use a natural language as the intermediate representation, mimicking human thought processes
This language-based approach offers several distinct advantages:
- Leverages rich priors from pre-trained LLMs
- Provides inference-time scalability
- Facilitates generalization across diverse tasks
This fundamental shift enables an entriely new class of apllications that were previously impossible. Let’s explore these next.
Digital Automation
LLM Agents enable a new class of digital automation applications. This advancement stands in stark contrast to previous digital assistants like Siri, which had fundamentally limited capabilities. The breakthrough with LLM agents comes from:
- Reasoning over real-world language (and other modalities)
- Making decisions across open-ended actions and long horizons
Earlier sequence-to-sequence systems couldn’t handle complex tasks requiring contextual understanding and extended planning.
The evolution of LLM agents represents parallel advancement in both mathematical models and practical applications - a dual progression critical to unlocking digital automation’s potential.
Applications
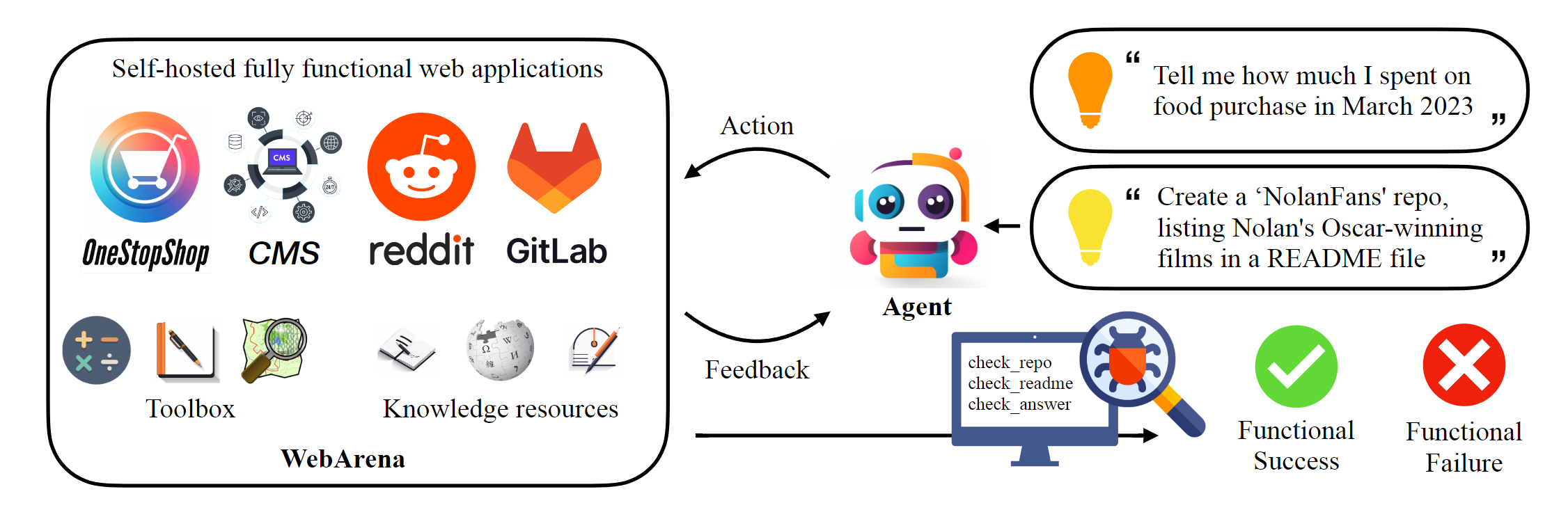
WebArena: General Web Interaction
WebArena[12] extends AI applications in web environments beyond online shopping, enabling a broader range of web-based interactions such as information retrieval, form filling, web navigation, and content generation. This highlights AI’s potential for diverse real-world applications.
SWE-Bench: AI for Software Engineering
SWE-Bench[13] is a benchmark designed for evaluate LLMs on real world software issues collected from GitHub. Given a codebase and an issue report, the AI must generate a file diff that resolves the issue. In this task:
- Input: GitHub repository + issue report
- Output: File diff to fix the issue
- Evaluation: Passing unit tests from a pull request
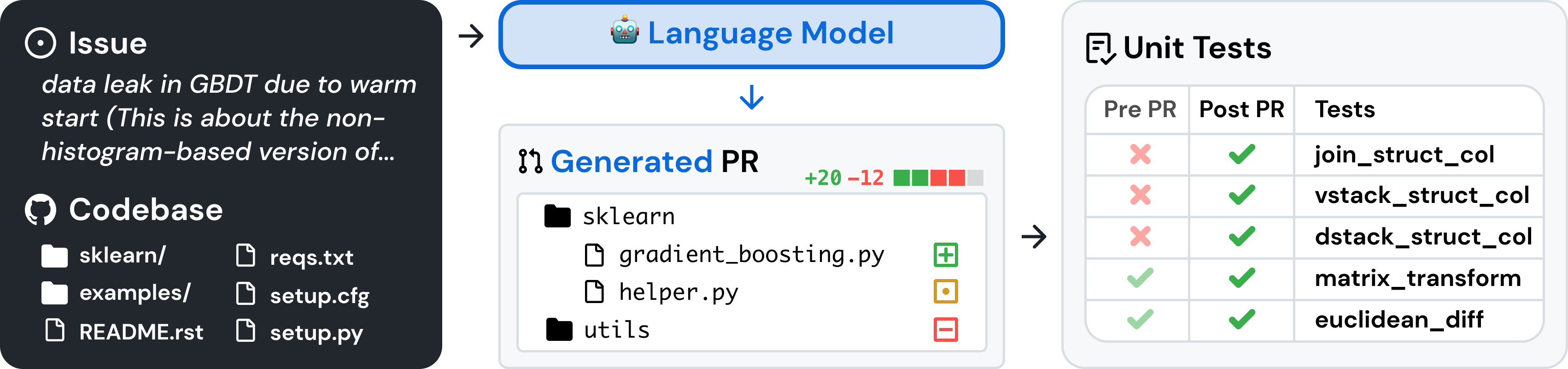
The task definition is straightforward, but solving it requires complex repository interaction, creating unit tests, executing code, and iterative debugging-mirroring the workflow of human software engineers.
ChemCrow: AI-Driven Scientific Discovery
ChemCrow[14] leverages ReAct to enable LLM agents in chemical discovery. Given chemical data and access to tools like Python and online databases, the AI can analyze information, reason through potential compounds, and take actions to propose novel chemical structures.
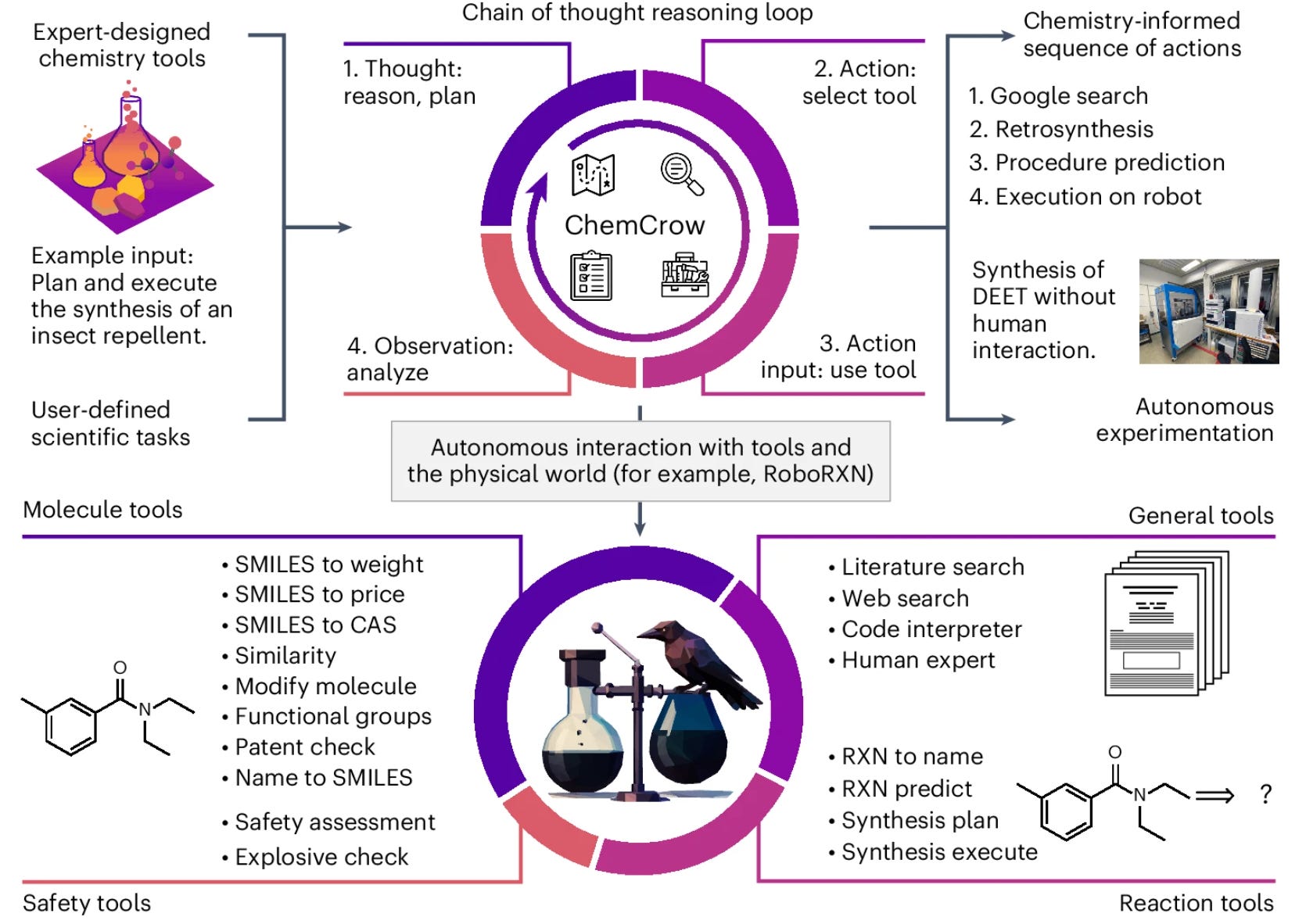
A key breakthrough is the integration of AI with physical experiments-suggested compounds are synthesized in a lab, providing real-world feedback that refines the AI’s predictions. This demonstrates how AI agents can operate byond digital tasks, extending into scientific research and real world experimentation.
Summary
Lessons for Research
Some of the most impactful research is remarkably simple-think of CoT and ReAct. Simplicity is powerful because it often leads to generality. However, achieving simplicity is challenging. It requires both:
-
Abstract Thinking: Looking beyond specific tasks or datasets to identify broader principles.
-
Task Familiarity (but not over-reliance on task-specific methods): Understanding problems deeply without getting stuck in incremental improvements.
Studying history and diverse disciplines can aid in developing abstraction skills, helping researchers identify more generalizable soultions.
What’s Next?
The future of AI research is multi-dimensional, with several promising directions. Here are five key areas worth exploring:
- Training: How can we effectively train models for AI agents? Where does the data come from?
- Interface: How do we design environments for AI agents?
- Robustness: How do we ensure AI solutions work reliably in real-world scenarios?
- Human interaction: How do AI systems perform when interacting with people?
- Benchmarking: How do we create meaningful benchmarks to measure progress?
References
[1] Narasimhan, Karthik, Tejas Kulkarni, and Regina Barzilay. “Language Understanding for Text-Based Games Using Deep Reinforcement Learning.” arXiv preprint, September 11, 2015.
[2] Brown, Tom B., Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, and others. “Language Models Are Few-Shot Learners.” arXiv preprint, July 22, 2020.
[3] Chen, Wenhu, Xueguang Ma, Xinyi Wang, and William W. Cohen. “Program of Thoughts Prompting: Disentangling Computation from Reasoning for Numerical Reasoning Tasks.” arXiv. November 22, 2022.
[4] SAIL Blog. “Building Scalable, Explainable, and Adaptive NLP Models with Retrieval.” October 5, 2021.
[5] Parisi, Aaron, Yao Zhao, and Noah Fiedel. “TALM: Tool Augmented Language Models.” arXiv, May 24, 2022.
[6] Schick, Timo, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, and others. “Toolformer: Language Models Can Teach Themselves to Use Tools.” arXiv, February 9, 2023.
[7] Trivedi, Harsh, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. “Interleaving Retrieval with Chain-of-Thought Reasoning for Knowledge-Intensive Multi-Step Questions.” arXiv, June 23, 2023.
[8] Press, Ofir, Muru Zhang, Sewon Min, Ludwig Schmidt, Noah A. Smith, and Mike Lewis. “Measuring and Narrowing the Compositionality Gap in Language Models.” arXiv, October 17, 2023.
[9] Yao, Shunyu, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. “ReAct: Synergizing Reasoning and Acting in Language Models.” arXiv, March 10, 2023.
[10] Shinn, Noah, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. “Reflexion: Language Agents with Verbal Reinforcement Learning.” arXiv, October 10, 2023.
[11] Sumers, T. R., Yao, S., Narasimhan, K., and Griffiths, T. L. “Cognitive Architectures for Language Agents.” arXiv.org, September 05, 2023.
[12] Zhou, Shuyan, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, and others. “WebArena: A Realistic Web Environment for Building Autonomous Agents.” arXiv, April 16, 2024.
[13] Jimenez, Carlos E., John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. “SWE-bench: Can Language Models Resolve Real-World GitHub Issues?” arXiv, November 11, 2024.
[14] Bran, Andres M., Sam Cox, Oliver Schilter, Carlo Baldassari, Andrew D. White, and Philippe Schwaller. “ChemCrow: Augmenting large-language models with chemistry tools.” arXiv, October 2, 2023.