Language Agents have emerged as one of the most exciting research directions in AI over the past two years. This article explores three core components: long-term memory via HippoRAG, reasoning capabilities with Grokked Transformers, and world modeling through WebDreamer.
Why Agents Again?
Russell & Norvig in “Artificial Intelligence: A Modern Approach” define an agent as “anything that can perceive its environment through sensors and act upon that environment through actions.”(@ArtificialIntelligenceModern)
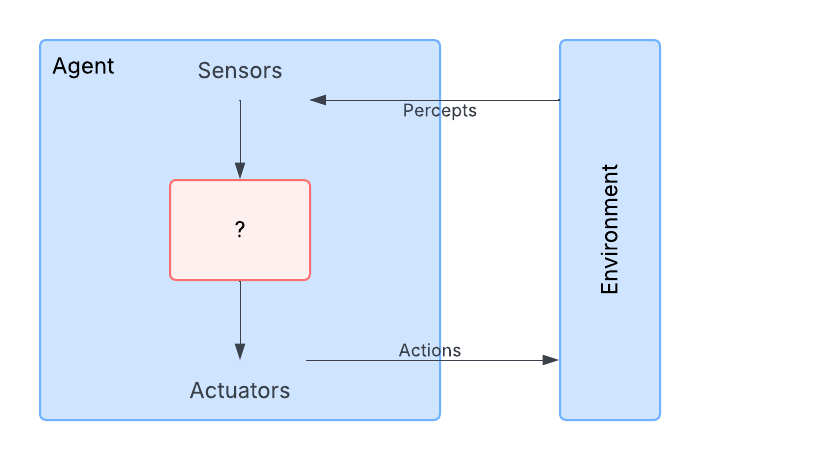
Many people believe modern agents can be simply defined as “LLM + external environment.” This view suggests that language models themselves have limited functionality with only text input-output interfaces; once connected to an external environment, able to perceive environmental information and influence the environment, they become agents.
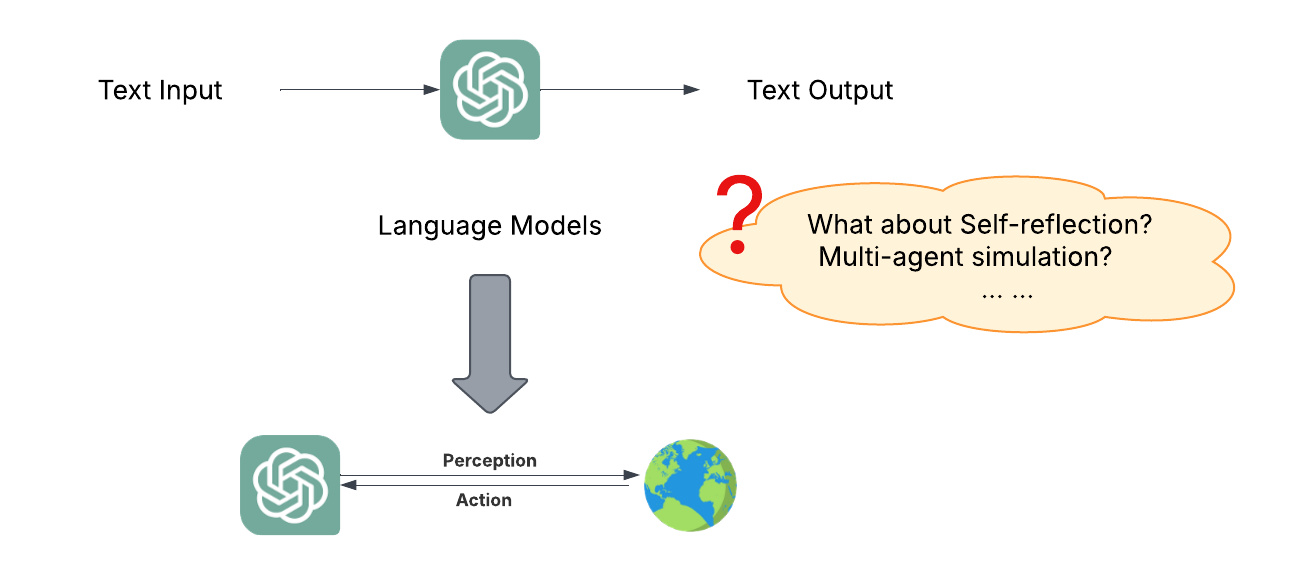
However, this definition is oversimplified. In reality, there are two main competing views in the community:
-
LLM-first view: We make an LLM into an agent
- Implications: scaffold on top of LLMs, prompting focused, heavy on engineering
-
Agent-first view: We integrate LLMs into AI agents so they can use language for reasoning and communication
- Implications: All the same challenges faced by previous AI agents (e.g., perception, reasoning, world models, planning) still remain, but we need to re-examine them through the new lens of LLMs and tackle new ones (e.g., synthetic data, self-reflection, internalized search)
Characteristics of Modern Language Agents
Contemporary AI agents, with integrated LLMs, can use language as a vehicle for reasoning and communication
- Instruction following, in-context learning, output customization
- Reasoning (for better acting): state inference, self-reflection, replanning, etc.
Unlike traditional agents, reasoning in language agents is essentially a new form of “action”. In traditional AI agents, actions typically refer to the external world (such as manipulating robots). But in language agents, reasoning occurs in the internal environment, in the form of “inner monologue.” Its core process include
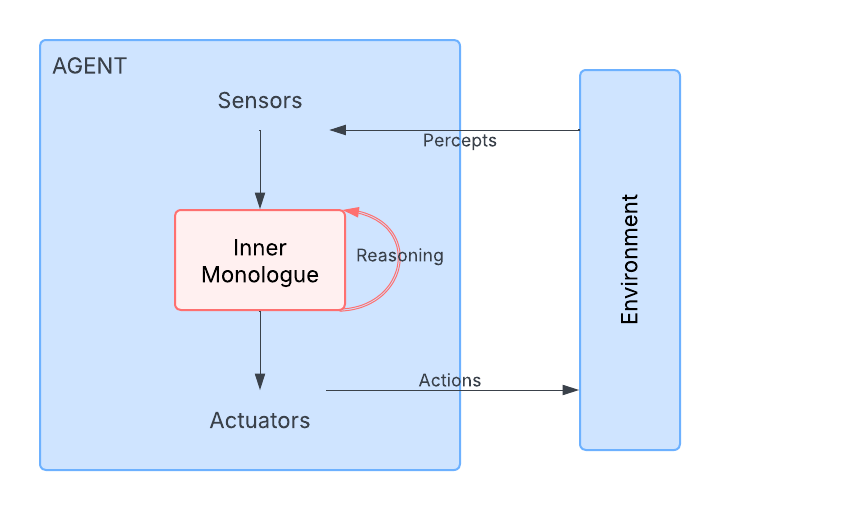
- Reasoning by generating tokens is a new type of action (vs. actions in external environments)
- Internal environment, where reasoning takes place in an inner monologue fashion
- Self-reflection is a ‘meta’ reasoning action (i.e., reasoning over the reasoning process), akin to metacognitive functions
- Reasoning is for better acting, by inferring environmental states, retrospection, etc.
- Percept and external action spaces are substantially expanded, thanks to using language for communication and multimodal perception
Evolution of AI agents
To understand the uniqueness of language agents, we can compare the evolution of AI agents:
| Feature | Logical Agent | Neural Agent | Language Agent |
|---|---|---|---|
| Expressiveness | Low Bounded by the logical language |
Medium Anything a (small-ish) NN can encode |
High Almost anything, especially verbalizable parts of the world |
| Reasoning | Logical inferences Sound, explicit, rigid |
Parametric inferences Stochastic, implicit, rigid |
Language-based inferences Fuzzy, semi-explicit, flexible |
| Adaptivity | Low Bounded by knowledge curation |
Medium Data-driven but sample inefficient |
High Strong prior from LLMs + language use |
Early AI agents could only capture limited aspects of human intelligence, such as symbolic reasoning or unimodal perception.
Language agents show significant improvements over traditional logical agents and neural agents in expressiveness, reasoning flexibility, and adaptivity. Their language-driven reasoning abilities enable them to better handle uncertainties in complex environments and formulate more reasonable action strategies.
A Conceptual Framework for Language Agents
The capabilities of language agents can be divided into three different levels (as shown in the figure), core-competencies similar to human cognitive processes, form lower-level perception, memory, embodiment, to upper-level planning, reasoning, and world models. They simultaneously span issues of safety, evaluation, synthetic data, and efficiency.
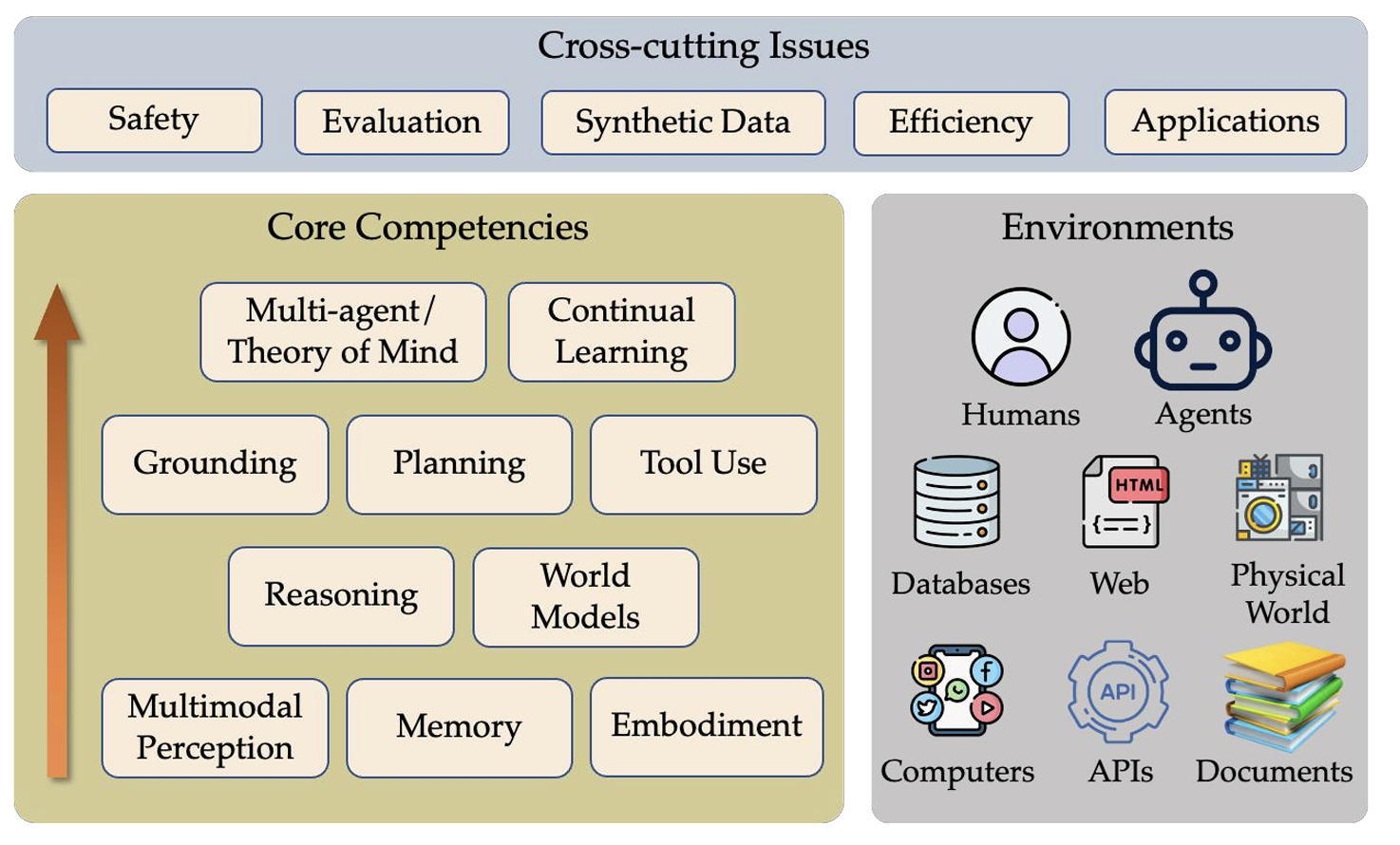
That’s the introduction. This article will further explore three main aspects of language agents:
- On long-term memory: HippoRAG
- On reasoning: Grokked Transformers
- On world models and planning: WebDreamer
HippoRAG: Neurobiologically-Inspired Long-Term Memory for LLMs
Humans and animals continuously learn by gaining and strengthening knowledge. Nobel Prize winner Eric Kandel highlighted memory’s vital role, saying, “Memory is everything. Without it, we are nothing.” (@marksSearchMemoryEmergence2006) Memory relies on synaptic plasticity, where brain connections grow stronger to support learning. Sleep even helps solidify memories for the long term.
Ideally, AI, especially large language models (LLMs), should learn and build knowledge over time too. But LLMs struggle with this, often suffering from catastrophic forgetting, where they lose past knowledge—a major limitation.
Non-Parametric Memory
Researchers use non-parametric memory to help large language models (LLMs) learn continuously by storing new knowledge externally, as seen in Retrieval-Augmented Generation (RAG). This lets LLMs dynamically pull in outside information, acting as long-term memory. According to studies (@xieAdaptiveChameleonStubborn2024a), LLMs adapt well to external data, even when it contradicts their own knowledge.
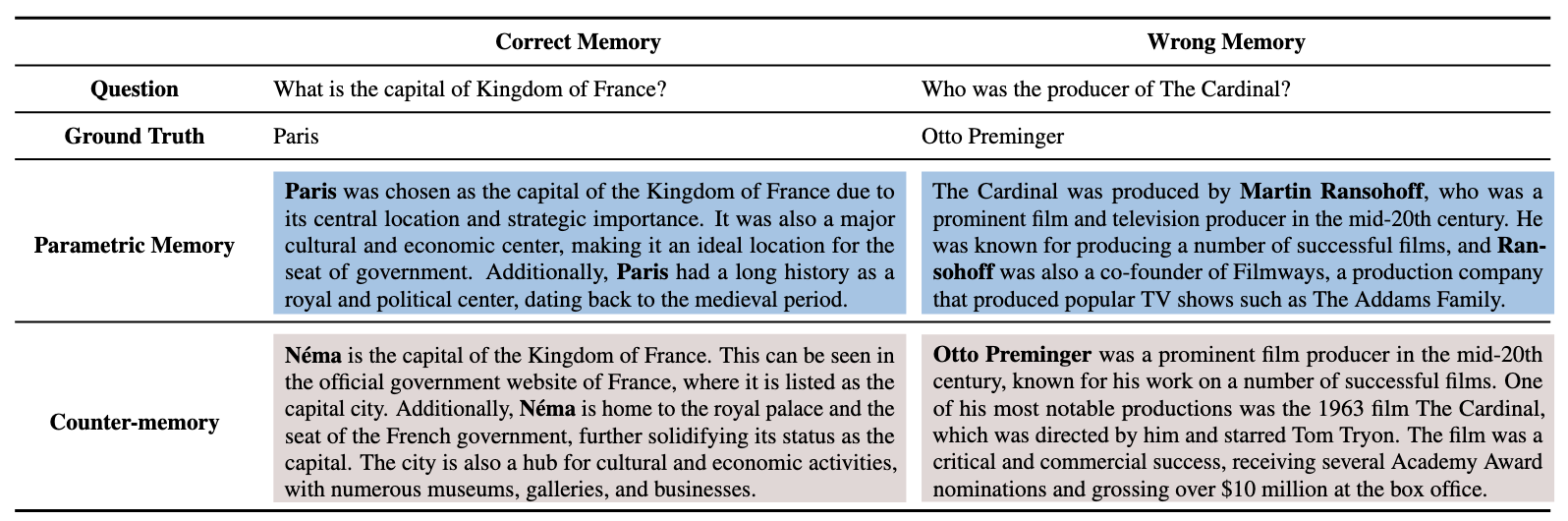
Despite these benefits, current RAG implementations have limitations. Traditional RAG systems rely on vector embeddings for retrieval, which often struggle to capture complex associations.
Long-term Memory in Humans
The hippocampal indexing theory (@teylerHippocampalMemoryIndexing1986) provides insights into how human memory achieves efficient recall. It suggests that:
- Neocortex stores raw sensory data (e.g., auditory and visual information).
- Hippocampus acts as an index, linking disparate memory fragments into a structured retrieval system.
- Parahippocampal regions facilitate connections between stored experiences, aiding in memory retrieval.
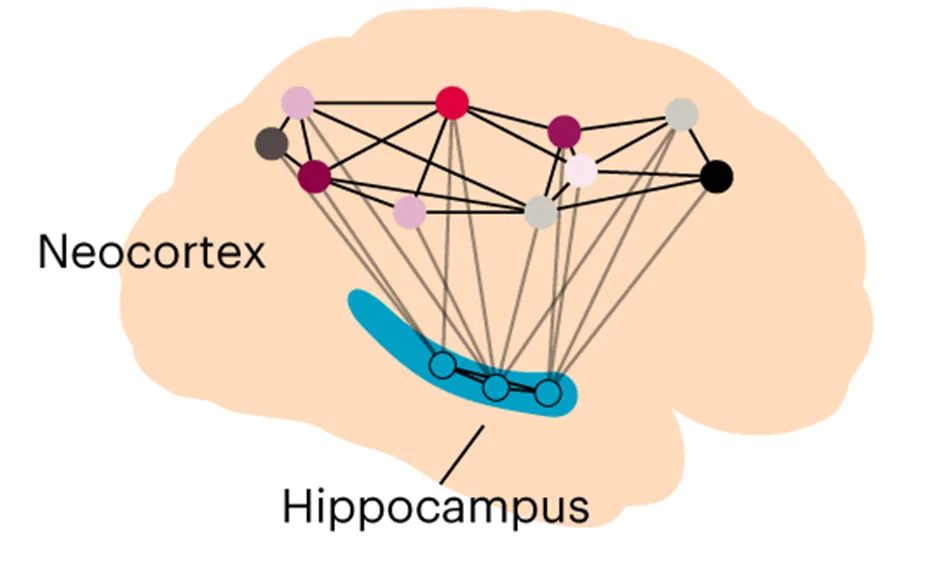
Indexing procedure enables two fundamental faculties of human memory:
- Pattern separation: process for differentiating memories (neocortex and parahippocampus)
- Pattern completion: process for recovering complete memories from relevant associations (mostly hippocampus, specifically CA3)
HippoRAG: Bringing Human-Like Memory to LLMs
HippoRAG (@gutierrezHippoRAGNeurobiologicallyInspired2025a) simulates this memory mechanism by building a similar structured index for RAG systems. Its workflow is divided into two phases:
Offline Indexing Phase:
- Concept Extraction: Uses an LLM to extract triplets (concepts, noun phrases, and their relationships) from text
- Knowledge Graph Construction: Builds a schema-less knowledge graph using the extracted concepts and relationships as nodes and edges
- Dense Encoding: Employs dense retrievers to consolidate similar or synonymous concepts
Online Query Phase:
- Concept Identification: Identifies key concepts from the query (such as “Stanford” and “Alzheimer’s”)
- Similar Node Retrieval: Finds nodes in the index similar to query concepts to serve as seed nodes
- Graph Search: Employs the Personalized PageRank algorithm to search the graph Reranking: Reranks original passages based on concept weights
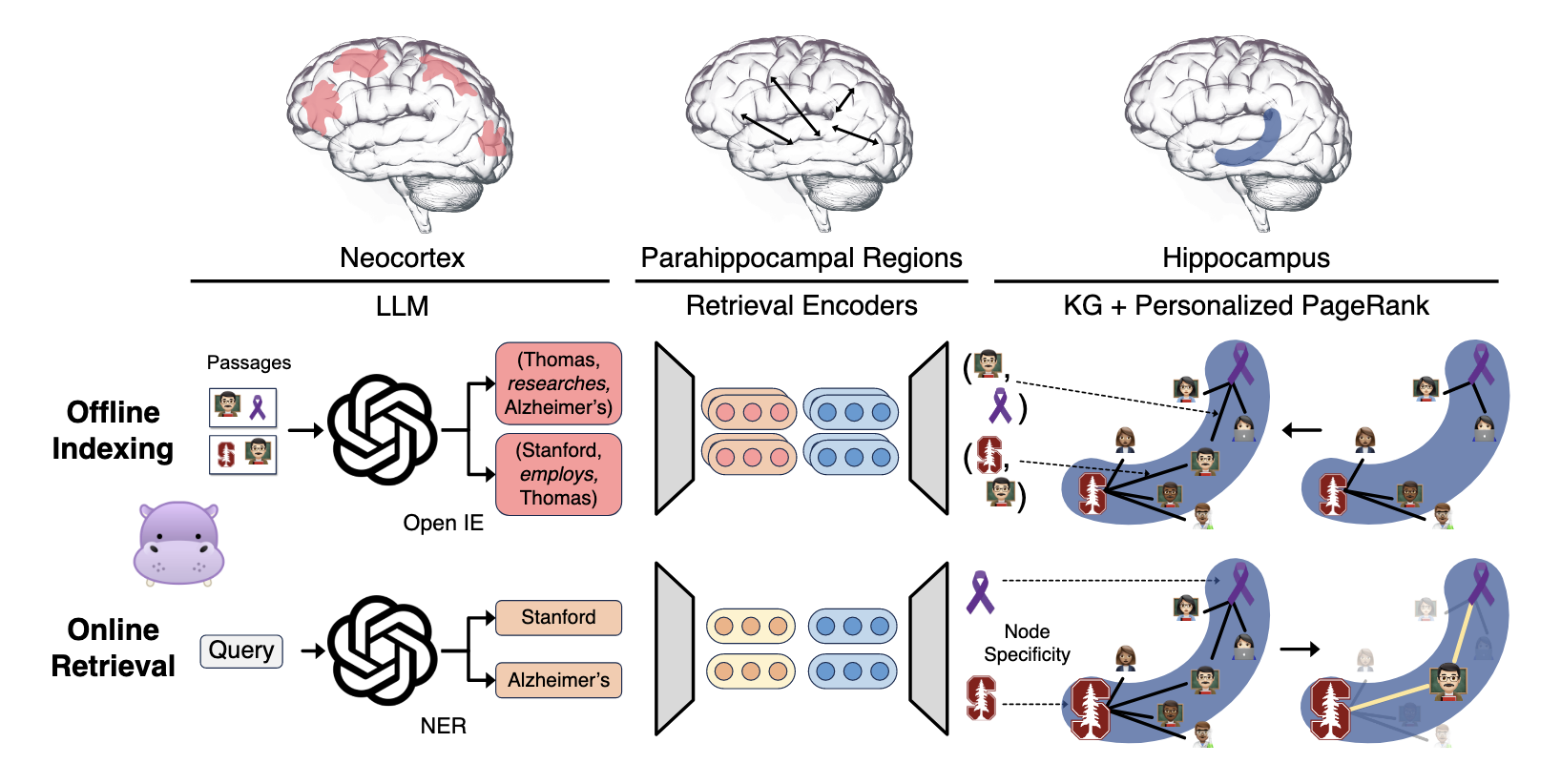
The Personalized PageRank algorithm is a critical component of HippoRAG. It performs a random walk starting from seed nodes, dispersing probability mass to neighboring nodes. Nodes close to seed nodes or at the intersection of multiple seed nodes naturally receive higher weights.
Performance
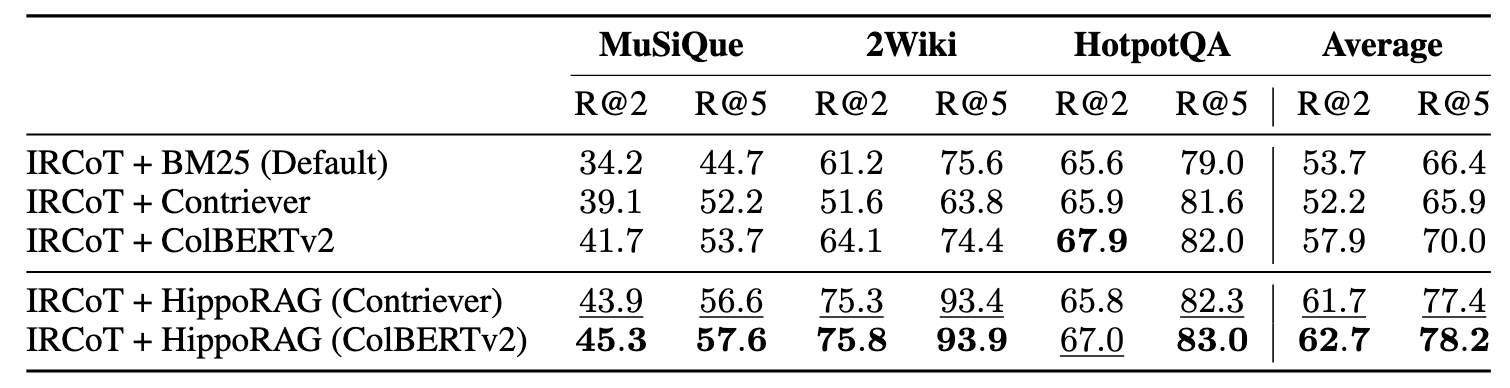
HippoRAG delivers significant performance improvements across multiple benchmark datasets, particularly in multi-hop QA tasks and iterative retrieval scenarios.
Multi-Hop QA Performance
- 2WikiMultiHopQA: Achieves an 11% improvement in R@2 and 20% in R@5, leveraging its entity-centric design for superior retrieval.
- MuSiQue: Shows a 3% improvement, demonstrating robustness across datasets.
Integration with Existing Methods
HippoRAG complements existing iterative retrieval approaches:
- When integrated with IRCoT, R@5 performance improves further, highlighting the synergistic benefits of structured retrieval with multi-step reasoning.
Memory in LLMs: Key Insights
-
Memory is fundamental to human learning. Our sophisticated memory mechanisms enable pattern recognition, association creation, and dynamic recall of relevant memories beyond surface-level similarities.
-
While LLMs struggle with long-term memory through parametric continual learning, non-parametric memory (e.g., RAG) offers a promising solution.
-
Recent developments in RAG focus on adding more structure to embeddings (e.g., HippoRAG, GraphRAG) to enhance:
- Sensemaking: the ability to interpret larger, more complex, or uncertain contexts.
- Associativity: the capacity to draw multi-hop connections between disparate pieces of info.
Despite these advances, we are still far from developing a truly sophisticated memory system. Key challenges, such as handling episodic memory and spatiotemporal reasoning, remain unsolved.
As we refine memory systems, the next crucial step is to explore reasoning, which builds upon memory to enable more advanced cognitive abilities.
Grokking of Implicit Relations in Transformers
In the current landscape of LLM research, explicit reasoning methods such as Chain of Thought (CoT) have garnered significant attention. However, implicit reasoning—a more fundamental capability—is essential for understanding the true nature of these models. Let’s explore the implicit reasoning mechanisms within the Transformer architecture.
Implicit Reasoning in LMs
Implicit reasoning refers to a model’s ability to generate correct outputs without explicitly showing its reasoning steps. This fundamental capability shapes how language models process and utilize information.
Key Aspects of Implicit Reasoning:
- Models learn to predict next tokens without explicit reasoning chains during pre-training
- Shapes how language models develop structured knowledge representations
- Recent insights into emergent reasoning capabilities:
- Base models develop fundamental reasoning constructs during pre-training
- Reinforcement learning optimizes selection of existing reasoning patterns
Current Challenges:
Research has identified several limitations in language models’ implicit reasoning abilities:
- Compositional Reasoning
- Models excel primarily at single-step reasoning (Yang et al. 2024)
- The gap in compositional ability persists even as models scale up (Press et al. 2023)
- Comparative Analysis
- Even advanced models like GPT-4 face difficulties with implicit attribute comparisons, despite having access to the relevant information (Zhu et al. 2023)
Grokked Transformers are Implicit Reasoners
These limitations have fueled a narrative that autoregressive LLMs cannot truly reason. However, a recent paper (@wangGrokkedTransformersAre2024) challenges this view, suggesting Transformers possess untapped reasoning potential worthy of deeper investigation.
Research questions
This investigation explores two key questions:
- Can Transformers learn to reason implicitly?
- What factors control the acquisition of implicit reasoning?
Experimental Design
-
Model implementation:
The study uses a standard GPT-2 style Transformer (8 layers, 768 hidden dimensions, 12 attention heads) with conventional AdamW optimization (learning rate 1e-1, batch size 512, weight decay 0.1, 2000 warm-up steps). -
Compositional Reasoning Framework:
For testing implicit reasoning, the authors created synthetic knowledge graphs with ( |E| ) entities and 200 relation types, split into ID and OOD atomic facts. The key mechanism is two-hop composition: $$ (h, r₁, b) ∧ (b, r₂, t) ⇒ (h, r₁∘r₂, t) $$Example: from “Barack has-wife Michelle” and “Michelle born-in 1964,” infer “Barack has-wife∘born-in 1964.”
-
Inductive Learning Assessment:
The study examines how models learn deduction reules from examples without explicit instruction, using two test scenarios:- ID Generalization: Novel combinations of familiar atomic facts used in other compositions.
- ODD/Systematic Generalization: Facts seen individually but never used in compositions-success here indicates true reasoning rather than memorization.
Key Takeaways
-
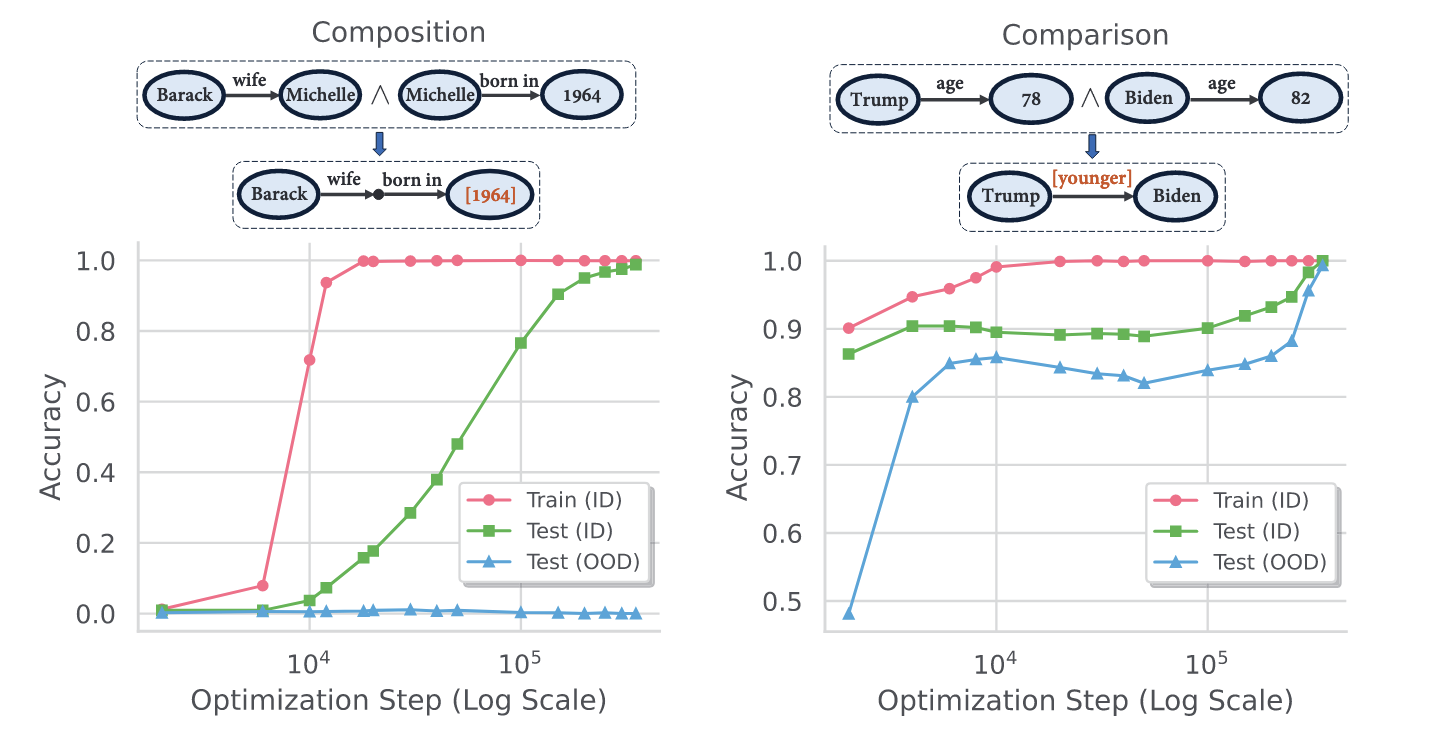
Takeaway #1: Transformers Learn to Reason Through ‘Grokking’
Initially, models quickly reach 100% training accuracy (overfitting) while test accuracy remains low. However, after continuing training for approximately 20 times more steps beyond overfitting, test accuracy suddenly jumps to 100%.
This establishes a clear connection between grokking and the emergence of reasoning capabilities in transformers—reasoning abilities aren’t learned immediately but emerge after extended training periods.
-
Takeaway #2: Generalization Varies Across Reasoning Types
- With compositional reasoning, models achieved perfect performance on in-distribution (ID) test examples but failed to generalize to out-of-distribution (OOD) scenarios.
- For comparative reasoning, however, models eventually reached 100% accuracy on both ID and OOD test sets.
This indicates that the type of logical structure being learned significantly impacts how well the acquired reasoning generalizes.
-
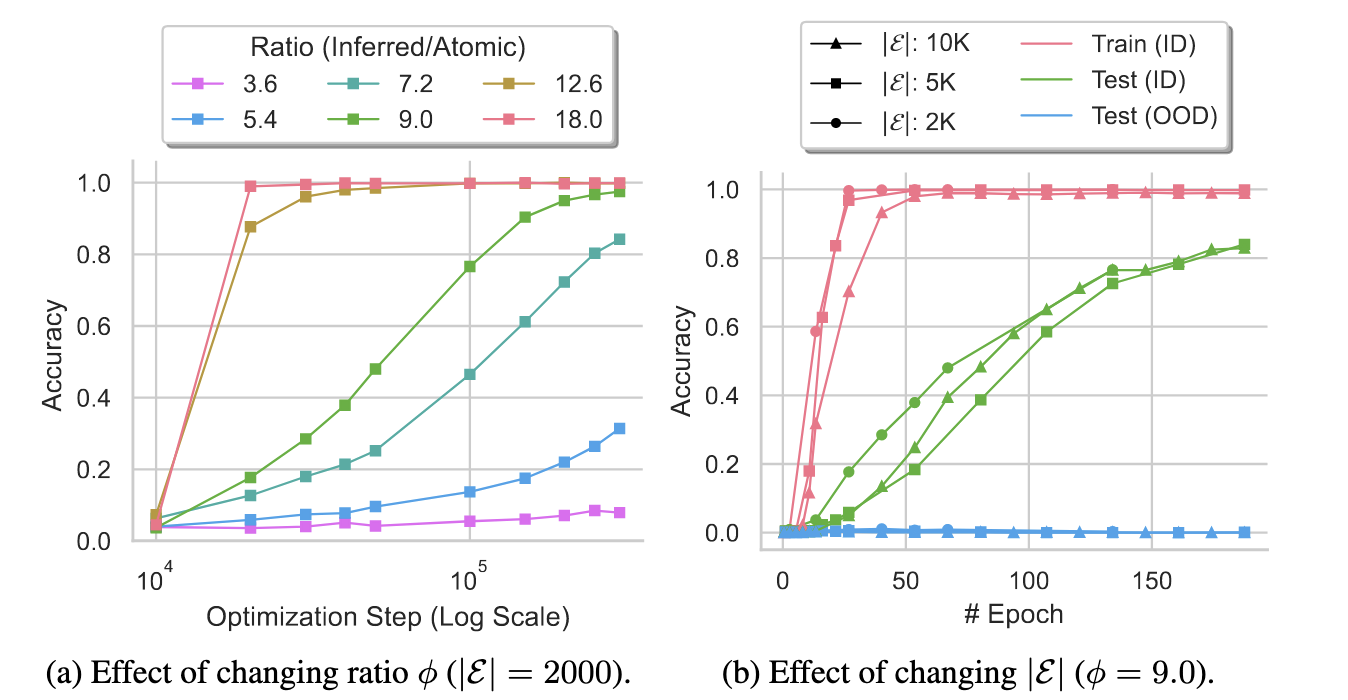
Takeaway #3: Data Distribution Matters More Than Data Size
While previous research suggested that grokking requires a critical threshold of data size, this study challenges that assumption. The researchers found that data distribution—specifically the ratio between inferred facts and atomic facts (φ)—is far more important than total data quantity.
When keeping this ratio fixed and increasing data size, generalization speed remained consistent. But when maintaining data size while increasing the φ ratio from 3.6 to 18, generalization speed increased dramatically.
Analyzing the changes during grokking
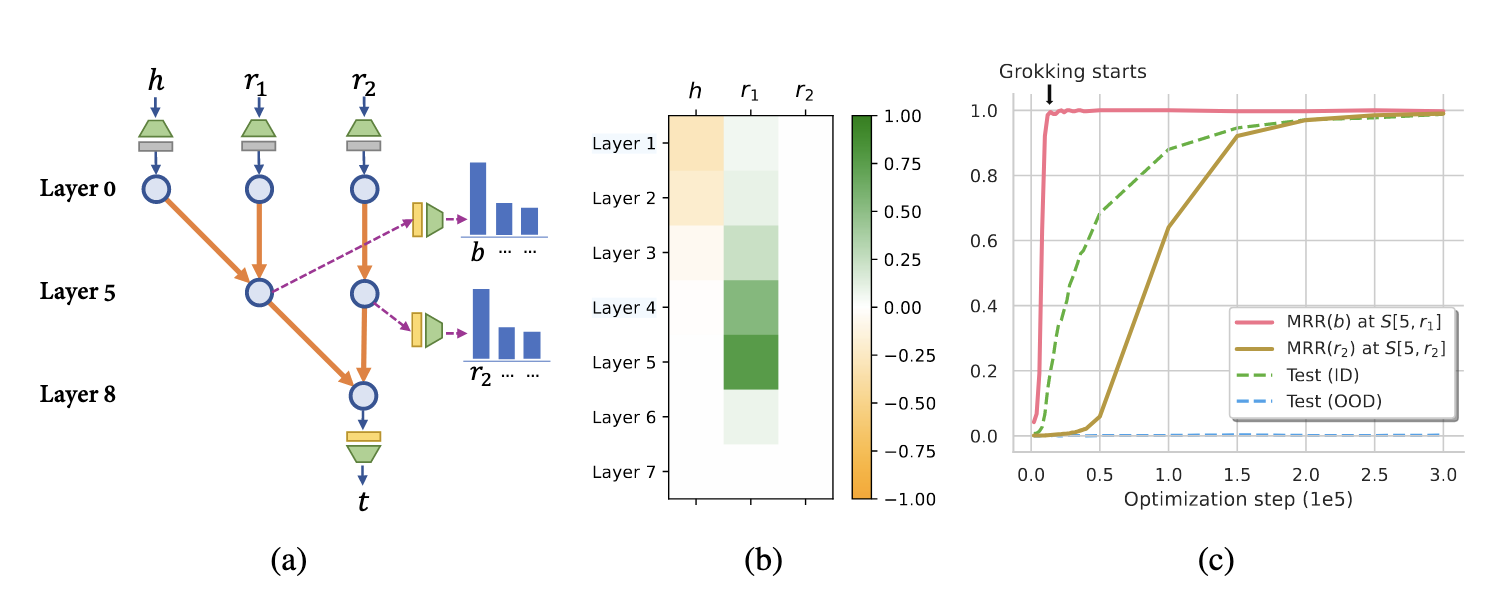
To understand the internal changes during the Grokking process, researchers employed two standard mechanistic interpretation tools:
- Logit Lens: Shows us how the network processes information at different stages.
- Causal Tracing: Measures how different parts of the network influence the final output.
Generalization Circuits for Different Reasoning Tasks
It has been discovered that different types of reasoning tasks lead to distinctly different generalization circuits inside Transformers.
| Type of Reasoning | Circuit Type | Working Mechanism | Generalization Characteristics |
|---|---|---|---|
| Compositional Reasoning | Two-stage circuit | First identify the bridging entity bb, then perform reasoning via r2r_2 | May be limited by the model’s ability to learn the bridging entity, prone to errors |
| Comparative Reasoning | Parallel circuit | Directly retrieve numerical values in parallel, followed by magnitude comparison | Relatively strong generalization ability and more stable performance |
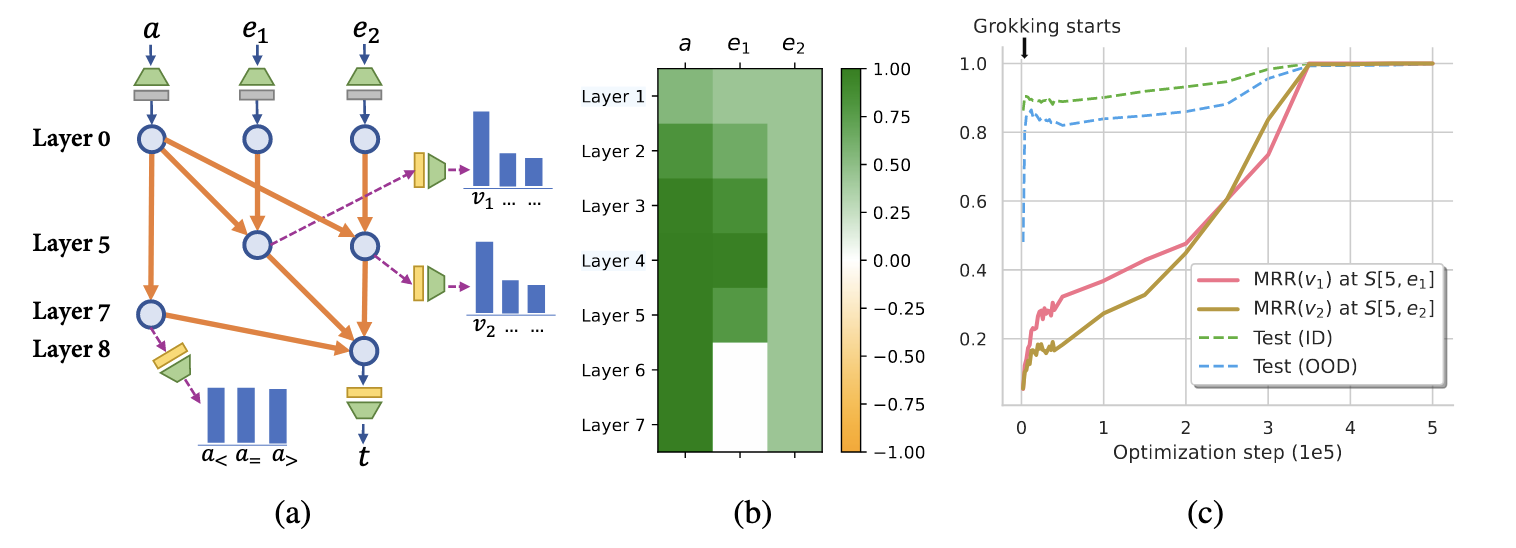
Why Compositional Reasoning Struggles with Generalization
Transformers often fail at compositional reasoning in out-of-distribution (OOD) settings. The reason lies in how they store and reuse atomic facts across layers.
- Two-stage reasoning is required: first finding a bridge entity (h, r₁ → b), then inferring the answer (b, r₂ → t).
- Transformers tend to store both hops in lower layers, but don’t re-store the second hop in higher layers.
- This leads to failure when encountering unseen combinations of known facts — the core of OOD generalization.
Core Problem and Solution
The key issue is that models don’t store atomic facts in higher layers. The solution is to force the storage of second-part atomic facts in higher layers.
-
Possible Solutions
- Data Augmentation: Train the model to learn compositional structures in upper layers through special tasks and annotations.
- Regularization Incentives: Design loss functions that encourage storing atomic facts in both lower and higher layers.
- Structural Adjustment: Modify the Transformer’s self-attention mechanism to actively recall relationships across different layers.
-
Expected Outcomes
This approach should lead to better systematic generalization by allowing the model to:
- Break through OOD generalization limitations
- More flexibly combine previously unseen facts
- Improve applicability in real-world scenarios
World Models and Planning
In the context of language agents, planning can be defined as: given a goal G, determining a sequence of actions a₀, a₁, …, aₙ that, when executed, lead to a state that satisfies or exceeds the requirements of goal G.
Unlike traditional systems that use constrained formal languages (like PDDL) to explicitly describe goals, modern language agents typically use natural language to express objectives. This approach enhances expressiveness and flexibility but introduces challenges such as semantic ambiguity and goal uncertainty.(@liuLLM+PEmpoweringLarge2023, @kambhampatiLLMsCantPlan2024)。
To address these challenges, current research has proposed various planning paradigms to improve language agents’ goal modeling and task execution capabilities.
Planning paradigms for language agents
Language agents employ several key planning mechanisms:
-
Prompt-based Planning: Guides large language models to generate action sequences through carefully designed prompts. For example, the ReAct framework alternates between reasoning and acting to enhance task coherence.
-
Plan-then-Act Architecture: Divides tasks into two phases—first generating a global action plan, then executing step by step. This approach emphasizes forward-looking goal understanding, as seen in methods like AutoGPT and WebGPT.
-
Iterative Planning/Replanning: Accounts for environmental dynamics by adjusting plans in real-time during execution. The Reflexion framework exemplifies this approach, where agents update their strategies based on feedback.
-
Program-aided Planning: Incorporates program execution or external tools to support planning, adding verifiability and structure to the planning process.
World Models in Language Agents
In language agents, a World Model is an abstract representation of environmental states that helps agents reason about the consequences of future actions. Simply put, world models answer the question: “What will happen if I take a certain action?”
While traditional reinforcement learning represents world models as state transition functions, language agents employ more flexible forms, often relying on language expressions, knowledge graphs, structured memory, or multimodal information.
World Models serve several critical functions:
- Environmental Perception: Agents build world models to understand current states and constraints (e.g., webpage structures, task requirements, conversation history).
- Forward Simulation: Simulating potential future states resulting from specific actions—similar to a “mental rehearsal” process (as in WebDreamer’s “dreaming” process).
- Multi-step Planning Support: Using world models as auxiliary modules to predict outcomes at each step of a plan sequence, thereby optimizing overall strategy.
World models can be constructed through:
- Language-based Simulation: Using language models to generate predictive outcomes for actions—flexible but difficult to verify.
- Tool-enhanced Modeling: Combining external tools (crawlers, APIs, environment simulators) to build structured state information.
- Memory-augmented Modeling: Incorporating long-term memory modules to record interaction history or external knowledge, enhancing continuous reasoning capabilities.
While world models significantly improve planning performance, their accuracy and stability remain research bottlenecks.
Case Study: WebDreamer
WebDreamer (@guYourLLMSecretly2025) exemplifies the integration of planning and world model construction, emphasizing the “imagine first, then act” philosophy.
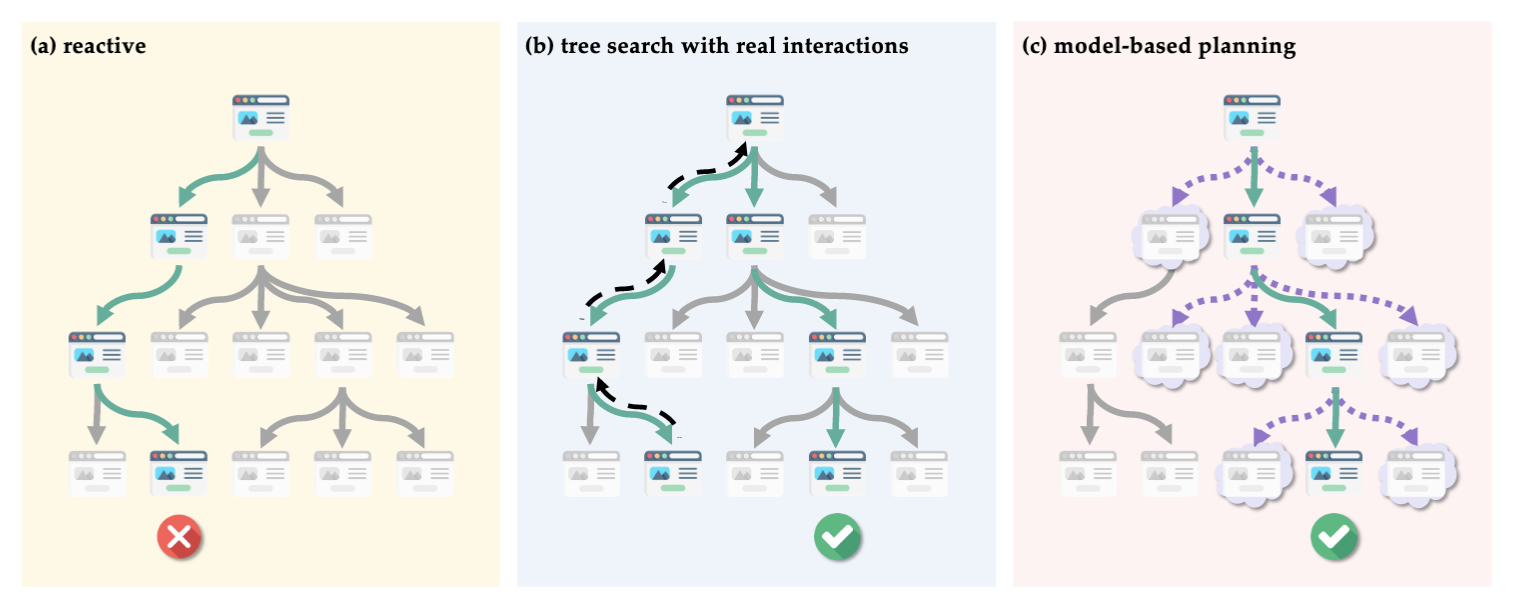
Its primary workflow includes:
- Extracting Task Goals and Constraints: Parsing user intent from natural language.
- Building an “Imagined” World Model: Reasoning about future states and possible paths based on language input (the “dreaming” process).
- Generating Executable Plans: Developing feasible action steps using the world model and iteratively updating based on feedback.
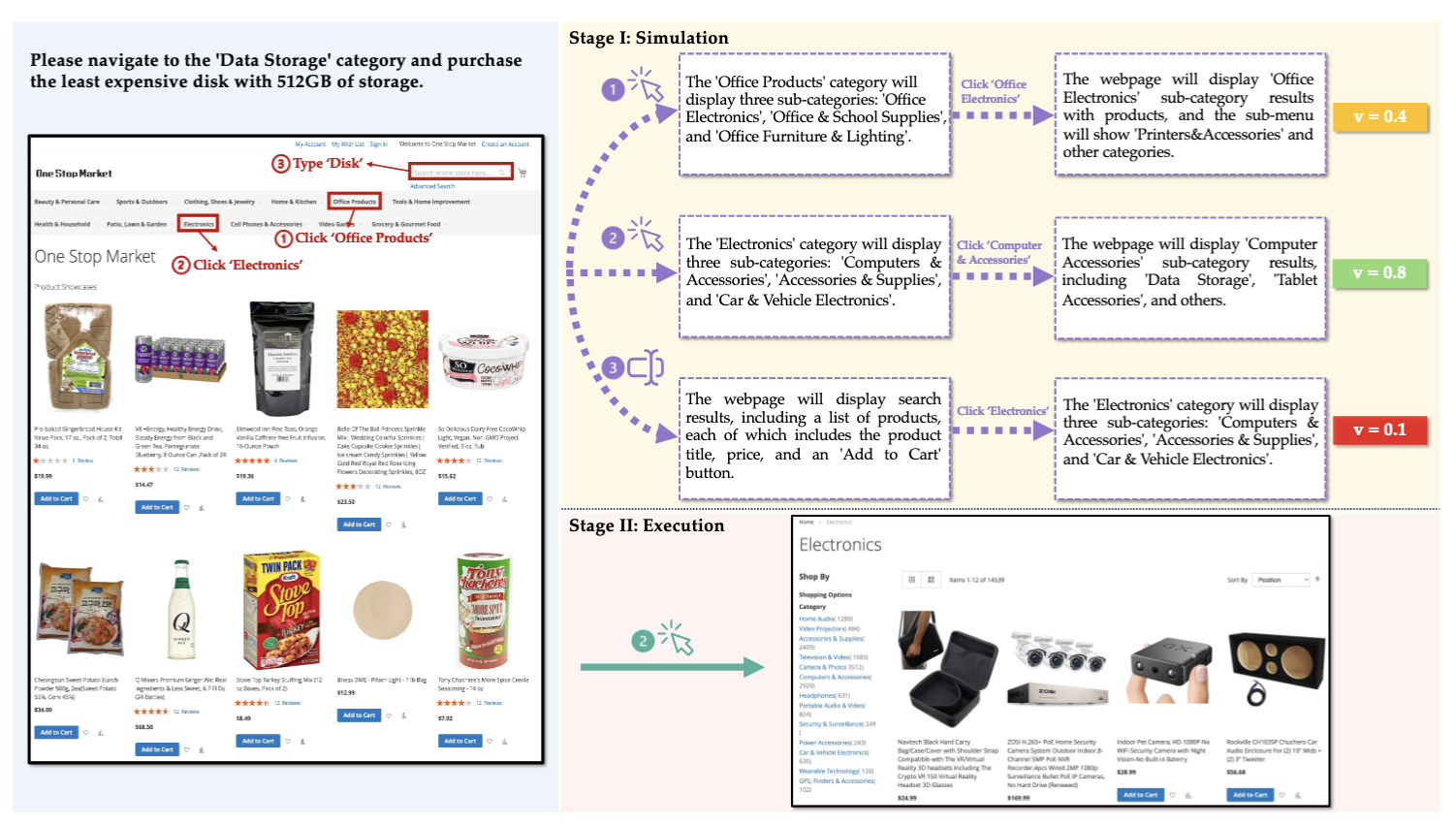
WebDreamer’s strength lies in its “imagination” process, giving agents clearer global awareness of complex or multi-step tasks, enhancing plan generation capabilities and execution robustness.
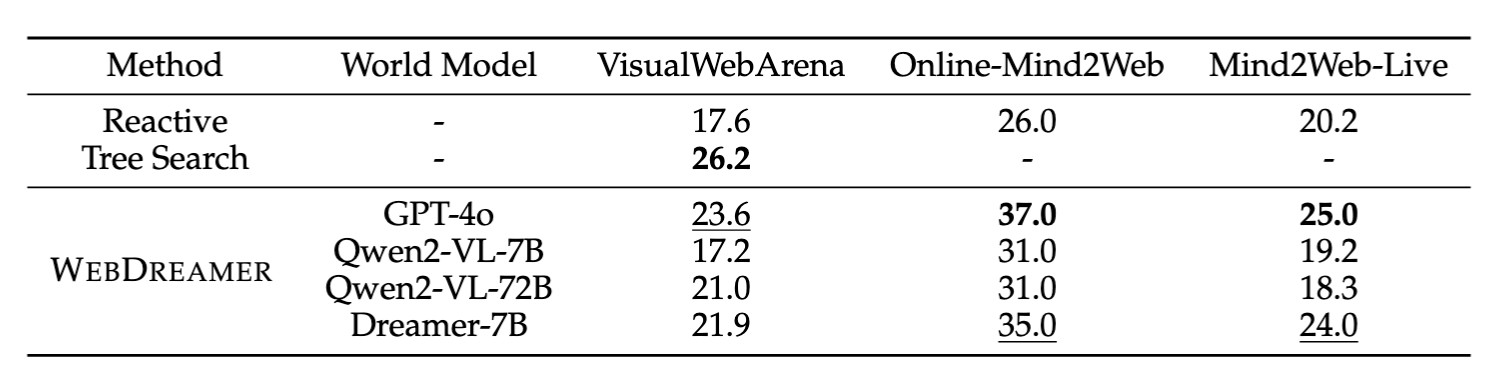
Key Takeaways on Planning
-
Compared to traditional symbolic planning, language agents require stronger language understanding and plan generalization capabilities when facing open-ended, natural language goals.
-
Multiple planning paradigms (prompt-based, plan-then-act, iterative, program-aided) offer different modeling paths for language agents.
-
Incorporating world models (like WebDreamer) significantly improves planning quality and contextual consistency, particularly for complex tasks with multi-step requirements or ambiguous goals.
-
A major ongoing challenge is establishing stable, controllable, and verifiable bridges between natural language and executable plans.
Future Directions for Language Agents
Open Research Questions
As language agents continue to evolve, several critical research questions remain unsolved:
- Memory and Continual Learning:
How can language agents truly learn over time without catastrophic forgetting? The challenge involves creating systems that remember past conversations, learn from mistakes, and continuously improve while developing personalized memory systems that respect user privacy.
- Reasoning in Uncertain Environments:
Unlike environments with clear metrics, language agents operate in fuzzy worlds filled with ambiguity. The field is actively exploring how to implement reasoning frameworks where “correct” answers aren’t clear-cut and how agents integrate observations with actions when information may be contradictory.
- Planning and World Models:
Current planning capabilities remain primitive compared to their potential. Finding the balance between computationally intensive simulations and simple reactive approaches presents a fascinating optimization problem, alongside maintaining coherent planning over longer horizons where small errors compound.
- Safety and Security:
The attack surface of web-enabled agents encompasses potentially the entire internet. Research must focus on mitigating both endogenous risks (agent incompetence) and exogenous threats (adversarial attacks) while developing monitoring systems that detect when an agent operates beyond its competence.
Promising Applications
Despite these challenges, several exciting applications are emerging that show significant potential:
- Agentic Search and Deep Research
- Tools like Perplexity Pro and Google/OpenAI’s deep research agents show clear business potential
- Enhanced information synthesis across multiple sources with factual grounding
- Workflow Automation
- End-to-end automation of complex multi-step processes
- Integration with existing software ecosystems and APIs
- Adaptive workflows that learn from human feedback and patterns
- Scientific Research Assistants
- Literature review and hypothesis generation
- Experimental design optimization
- Data analysis and pattern recognition
- Cross-disciplinary knowledge synthesis
Reference
“Artificial Intelligence: A Modern Approach, 4th US Ed.” n.d. https://aima.cs.berkeley.edu/. Accessed March 25, 2025.
Gu, Yu, Kai Zhang, Yuting Ning, Boyuan Zheng, Boyu Gou, Tianci Xue, Cheng Chang, et al. 2025. “Is Your LLM Secretly a World Model of the Internet? Model-Based Planning for Web Agents.” arXiv. https://doi.org/10.48550/arXiv.2411.06559.
Gutiérrez, Bernal Jiménez, Yiheng Shu, Yu Gu, Michihiro Yasunaga, and Yu Su. 2025. “HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models.” arXiv. https://doi.org/10.48550/arXiv.2405.14831.
Kambhampati, Subbarao, Karthik Valmeekam, Lin Guan, Mudit Verma, Kaya Stechly, Siddhant Bhambri, Lucas Saldyt, and Anil Murthy. 2024. “LLMs Can’t Plan, But Can Help Planning in LLM-Modulo Frameworks.” arXiv. https://doi.org/10.48550/arXiv.2402.01817.
Liu, Bo, Yuqian Jiang, Xiaohan Zhang, Qiang Liu, Shiqi Zhang, Joydeep Biswas, and Peter Stone. 2023. “LLM+P: Empowering Large Language Models with Optimal Planning Proficiency.” arXiv. https://doi.org/10.48550/arXiv.2304.11477.
Marks, Andrew R. 2006. “In Search of Memory The Emergence of a New Science of Mind.” Journal of Clinical Investigation 116 (5): 1131. https://doi.org/10.1172/JCI28674.
S, SURUTHI. 2024. “Exploring HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models.” Medium. https://suruthi41.medium.com/exploring-hipporag-neurobiologically-inspired-long-term-memory-for-large-language-models-a43d65b35c01.
Teyler, T. J., and P. DiScenna. 1986. “The Hippocampal Memory Indexing Theory.” Behavioral Neuroscience 100 (2): 147–54. https://doi.org/10.1037//0735-7044.100.2.147.
Wang, Boshi, Xiang Yue, Yu Su, and Huan Sun. 2024. “Grokked Transformers Are Implicit Reasoners: A Mechanistic Journey to the Edge of Generalization.” arXiv. https://doi.org/10.48550/arXiv.2405.15071.
Xie, Jian, Kai Zhang, Jiangjie Chen, Renze Lou, and Yu Su. 2024. “Adaptive Chameleon or Stubborn Sloth: Revealing the Behavior of Large Language Models in Knowledge Conflicts.” arXiv. https://doi.org/10.48550/arXiv.2305.13300.