In today’s rapidly evolving AI landscape, the remarkable progress we’ve witnessed is largely attributed to open scientific research and fully open models. However, as time progresses, more and more research and development work is becoming increasingly closed off.
We still need to delve deeper into how language models work, improve their capabilities, and make them safer, more efficient, and more reliable. Simultaneously, we need to extend language models’ abilities beyond text into domains like healthcare, science, and even complex decision-making processes. Most importantly, we must bring these models into real-world applications, ensuring they are deployable, interpretable, and effectively mitigate biases and risks.
To achieve these goals, we need:
- Fully open language models: including data, code, and training details
- Transparent research processes: facilitating review and understanding
- Reproducible results: driving robust scientific progress
- Accessible ecosystems: supporting broader researcher participation
At the University of Washington and AI2, this commitment to openness is foundational. Through two major initiatives—OLMo (Open Language Models) and Tulu (an open post-training framework)—they are building a fully open language model ecosystem that spans pretraining, post-training, intermediate training stages, and agent development.
In this post, I’ll introduce three of their key efforts to improve reasoning in language models, each representing a distinct but complementary stage of the development pipeline:
- Pretraining: OLMo, Dolma
- Post-training: Tulu, OpenInstruct
- Test-time inference: S1, Self-RAG, OpenScholar
Overview
OLMo 2
OLMo 2(@olmo2OLMo22025) is available in two sizes: 7B and 13B parameters. Despite being trained on significantly fewer tokens, both versions achieve performance on par with Llama 3 and Qwen 2.5 across standard open-source evaluation benchmarks.
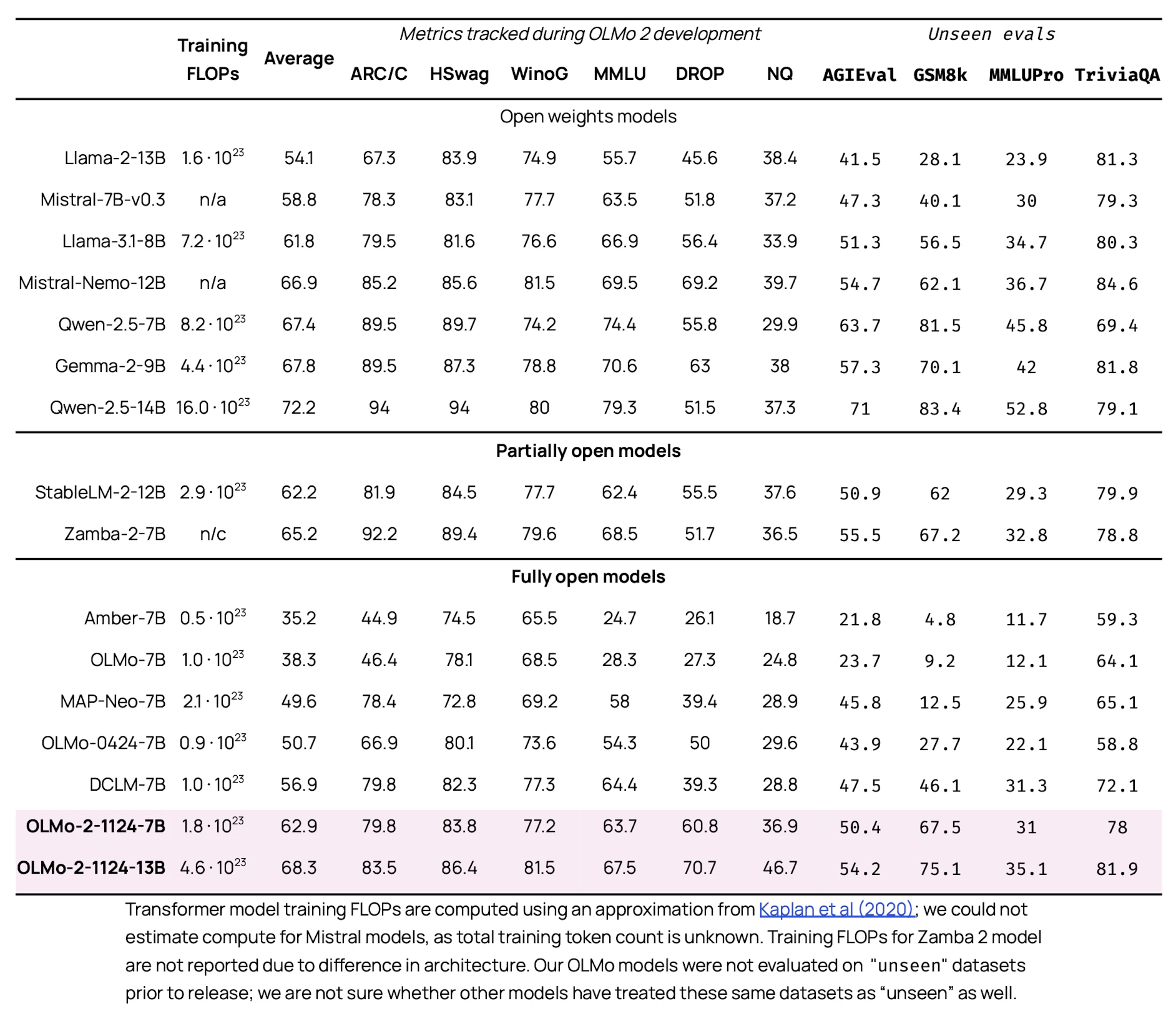
On the “compute vs. model quality” curve, OLMo 2 falls on the so-called Pareto optimal frontier—demonstrating that with careful data curation and training strategies, it is possible to achieve competitive results without relying on massive computational resources.
Tulu 3
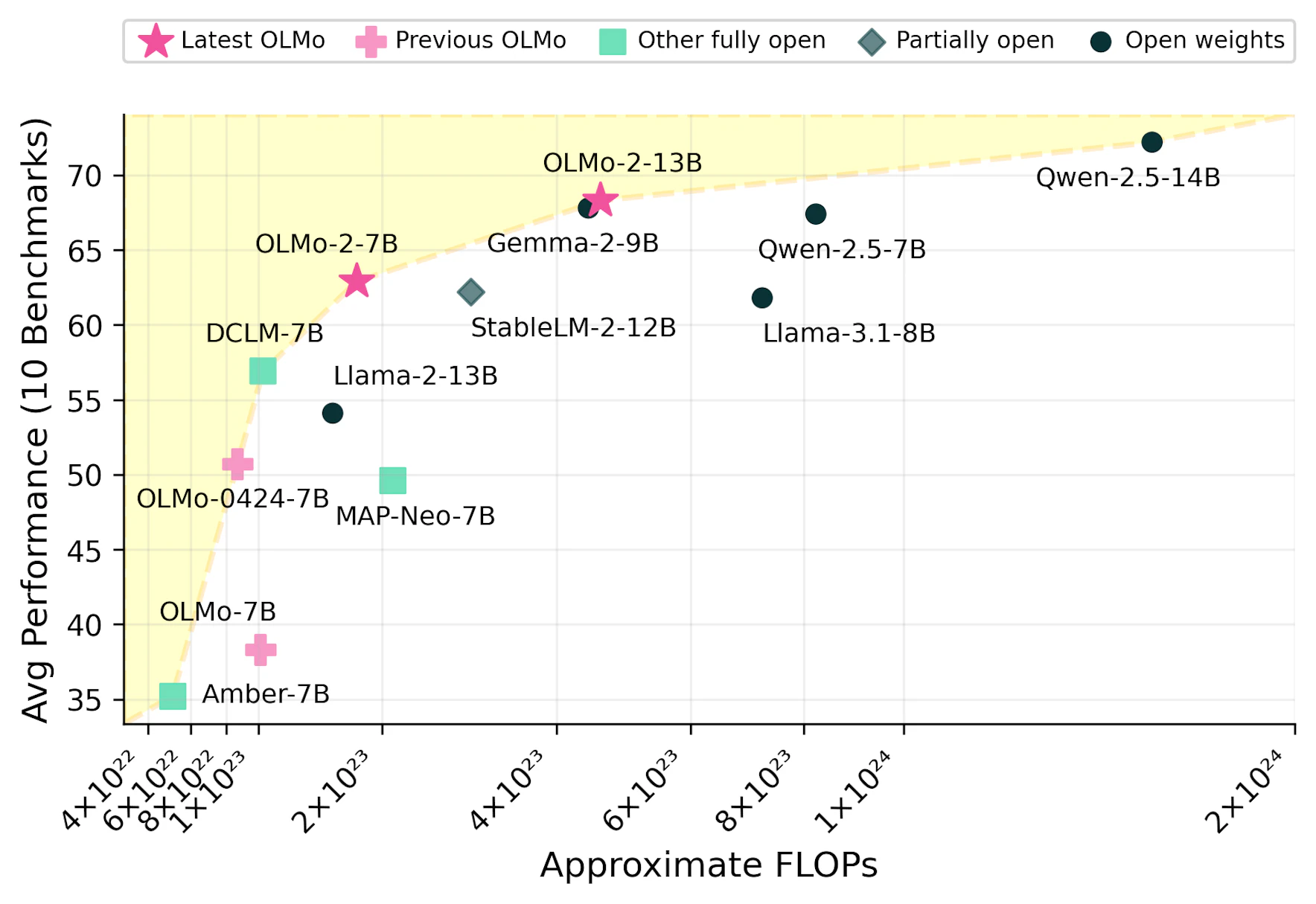
Tulu 3(@lambertTulu3Pushing2025) is AI2’s latest instruction-tuned model, built on top of Llama 3-405B. Through multi-stage instruction tuning, safety alignment, and tool-augmented reasoning, Tulu 3 now surpasses DeepSeek V3 and comes close to GPT-4o on reasoning-intensive tasks.
In the following sections, I will walk through this post-training pipeline step by step and explain how each component contributes to the final performance gains.
Post Training: Tulu
We start with post-training because most of the “reasoning capabilities” in modern large language models are developed and strengthened during this stage. Building modern LLMs typically involves two main phases:
-
Pretraining: Models learn to predict the next token through large-scale data (primarily from the internet). This stage produces base models with certain general capabilities, but they are not yet safe and lack instruction-following and strong reasoning abilities.
-
Post-training: Fine-tuning the base models to enable them to understand human intentions, use tools, perform reasoning, and comply with safey and regulatory requirements.

Tulu: Open Instruction Tuning Recipe
Tulu is an open, reproducible, and leading-performance post-training methodology. The post-training pipeline consists of 3 key steps, with iterative adjustments and refinements based on model feedback between these steps.

-
Instruction Tuning: Fine-tuning base models using large amounts of “instruction + response” data (which can be human-annotated or synthetically generated by models) to make them better at executing instruction tasks.
-
Preference Tuning: Collecting human preference feedback (e.g., “which response do you prefer?”) to train models to generate answers that better align with human expectations. Tulu 3 systemically compares DPO (Direct Preference Optimization) and PPO (Proximal Policy Optimization) methods.
-
Reinforcement Learning with Verfiable Reward: Building upon RLHF with further innovation, fine-tuning models through controllable and verifiable rewards signals to enhance their robustness in complex scenarios.
In addition, the following four steps are also crucial for successful model adaptation:
-
Establish clear eval criteria for each target capability, such as mathematics, programming, safety, etc.
-
Design representative task prompts for these capabilities
-
Ensure data compliance and legality, avoiding copyright issues
-
Decontaminate data to ensure no overlap between eval and training sets
Step 1: Supervised Finetuning
The first step in the Tulu training pipline is Supervised Finetuning (SFT), aimed at giving pre-training language models basic task execution capabilities. SFT involves fine-tuning models using large amounts of “Prompt + Completion” samples to teach them how to respond to human input.
To construct high-quality instruction data, the Tulu team proposed a “dual-track data construction strategy” that can be executed in parallel:
- Data Curation: Design and collect high-quality samples around core tasks, such as dialogue, programmming, reasoning, etc.
- Data Mixing: Combine human-annotated data with model-generated data to cover broad capabilities and improve generalization
In model evaluation, the team systematically tested performance across multiple capability dimensions (dialogue, knoeledge, reasoning, code, multilingual, safety). To further improve training effectiveness, they adopted the following stragegies to optimize data configuration:
- Select datasets that perform expectionally well on specific tasks
- Mix human and synthetic data to ensure diversity and scale
- Adjust data proportions by task capability dimensions to achieve training balance

Data Challenges and Solutions for Reasoning Capabilities
Compared to tasks that output single answers, reasoning problems are often more complex, requiring models to have multi-step thinking capabilities. Research shows that CoT data is exetermly effective for such tasks. However, high-quality CoT data often requires expert step-by-step annotation, which is expensive, inefficient, difficult to scale, and lacks diversity in style.
To address these challenges, the Tulu team proposed a “Persona-Driven data generation” method based on the paper “Scaling Synthetic Data Creation with 1,000,000,000 Personas”(@geScalingSyntheticData2025):
-
Design specific personas (such as chemists, children, programmers) for particular skills (like mathematics, coding)
-
Models generate tasks and problem-solving processes based on personan settings, improving content diversity and scalability

The Tulu team designed approximately 250,000 personas and guided models to generate three-types of core task data, combined with GPT-4o and Claude Sonnet to complete step-by-step solutions, forming complete CoT samples.
Experimental results show:
After adding persona data, models significantly improved on mathematical tasks, especially on complex problems. Improvement on simple problems like GSM8K was relatively limited.
To further improve quality, Tulu introduced a GPT-4 self-consistency voting mechanism, retaining optimal solution paths and filtering out nearly 40% of noisy samples. Ultimately, retaining only 60% of the data still achieved higher accuracy.
Other approaches to generate COT data
- Manual Human Annotation (e.g., GSM8K dataset): Annotators write step by step solutions
- High-quality reasoning traces
- Limited scale (only 7K)
- Lack of diversity in reasoning styles
- Program-Aided Language Models (PAL): Convert math problems into Python code execution traces
- Guarantee correctness through execution
- Less natural language reasoning, less intuitive
- Limited to problems that can be coded
- Self-generated COT (self-ask): using LLMs to generate their reasoning paths
- Scalable to many problems
- Quality highly dependent on base model
Capability-driven Data Mixing
- Data mixing for SFT
- Training on real user interactions with strong models is helpful almost across the board.
- Safety training is largely orthogonal to the other skills.
- Persona-based data synthesis is very useful for targeting new skills.

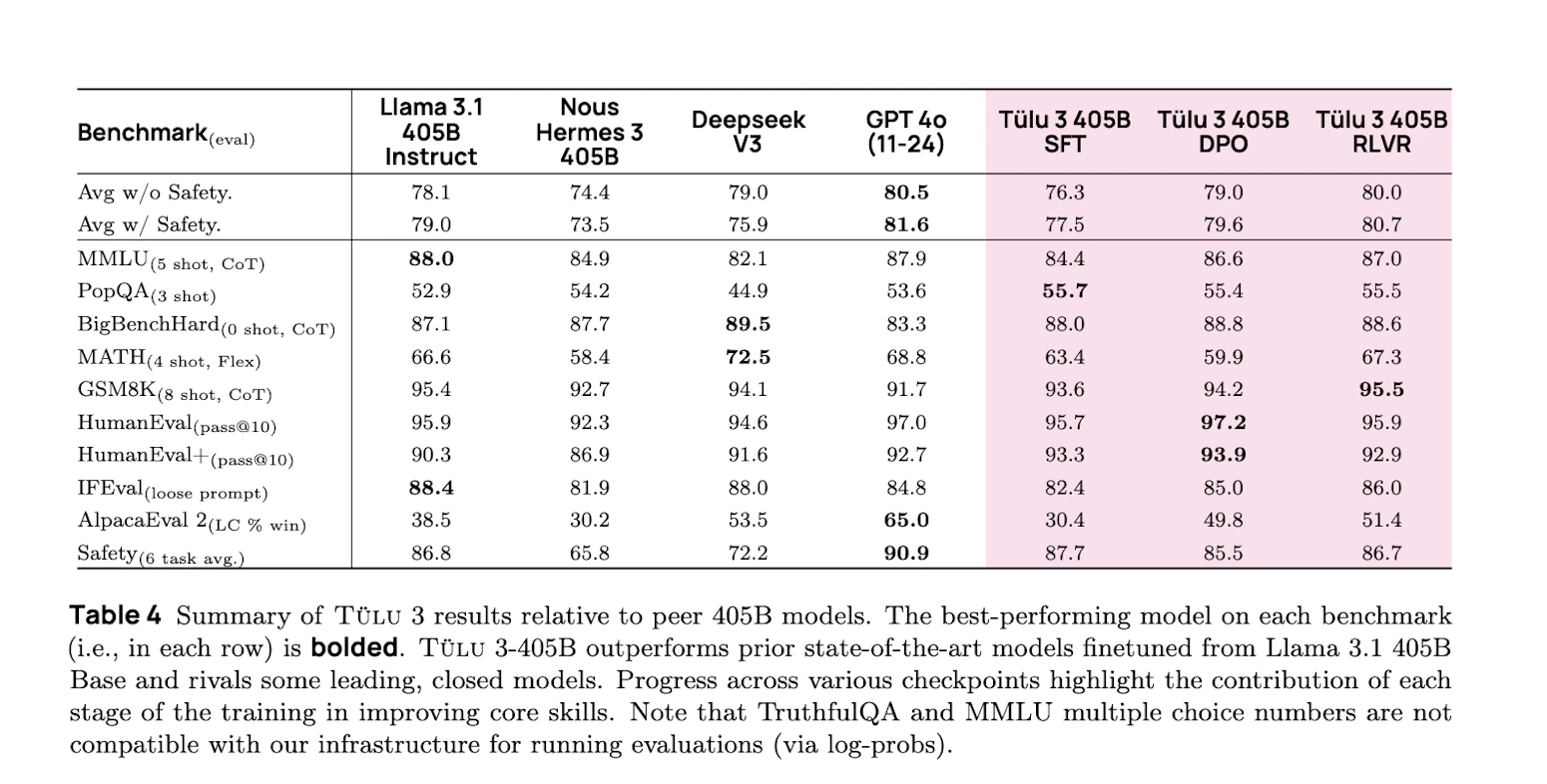
- SFT performance potential
SFT mixtures show strong performance, achieving a higher average score than other comparable mixes. All models, including Tülu 2 SFT, were trained on either Llama 3.0 or 3.1. Our final Tülu 3 70B model was used to help format this table.
Step 2: Preference Tuning
After supervised fine-tuning, we move to preference tuning to align the model with human preferences.
The key idea is: instead of training on “correct” answers, we train on preference comparisons. For example:
Input: “Write a haiku about AI”
Output 1: “Sure, here’s a haiku: …” 👍
Output 2: “Sorry, I cannot help you with that.” 👎
In this case, human annotators (or even AI models in the case of RLAIF-Reinforcement Learning with AI Feedback) choose the better response. This feedback creates strong training signals that improve the style, helpfulness, and conversational quality of responses.
While preference tuning continues to enhance skills developed in SFT, its biggest gains are in areas like tone, clarity, and user alignment - not necessarily raw task performance like math.
Since we can’t use standard supervised learning on preference comparisons, we need specialized algorithms like RLHF (Reinforcement Learning with Human Feedback).
RLHF
RLHF (@christianoDeepReinforcementLearning2023) uses a reinforcement learning framework to incorporate preference data. In this framework:
- Policy: the language model responsible for generating the next token
- State: the user’s input prompt
- Action: the model generated response
- Environment: a reward model trained on preference data, which determines which responses is better
The reward model is specially trained neural network that takes a prompt and multiple candidate responses as input, and outputs a preference score. This score guides the model to learn to produce responses more aligned with human preferences.
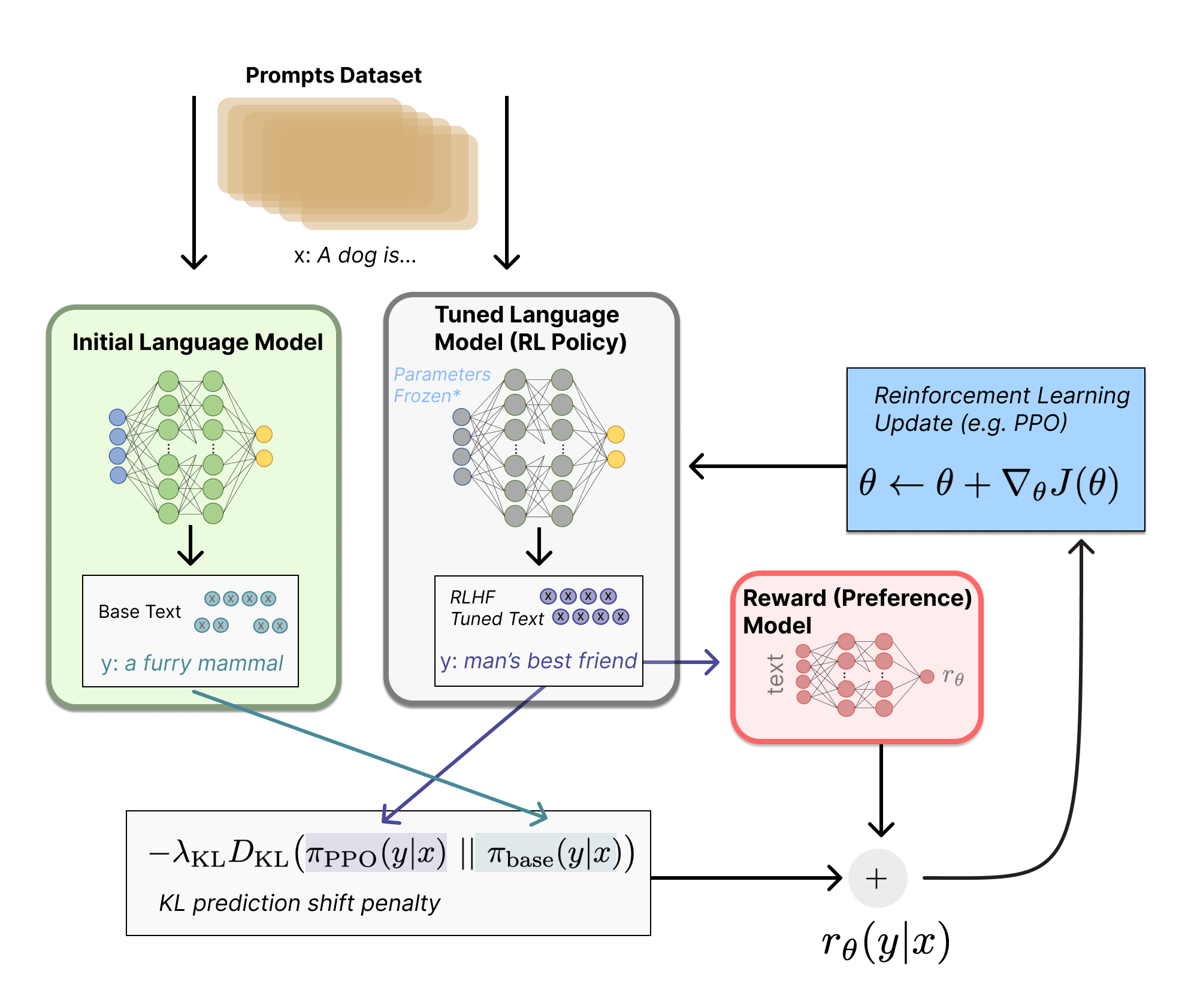
To optimize this process, algorithms like PPO (Proximal Policy Optimization) are commonly used. In newer approaches, DPO (Direct Preference Optimization) is also gaining popularity. Let’s take a closer look at how these methods work.
Unpacking DPO vs. PPO
The core challenge of preference tuning lies in balancing two goals:
- Maximizing rewards: training the mdoel to produce outputs aligned with human preferences
- Staying close to the base model: avoiding drastic shifts that could degrade core capabilities
PPO:Proximal Policy Optimization
PPO(@schulmanProximalPolicyOptimization2017) follows the traditional reinforcement learning approach, in two steps:
- Train a reward model using human preference data (e.g., A is better than B). This model learns to assign scores based on human feedback.
- Optimize the policy model (i.e., the language model) using RL to generate outputs that maximize the learned reward.
PPO delivers strong performance but is complex to implement, costly to train, and requires maintaining both a policy and a reward model.
DPO: Direct Preference Optimization
DPO (@rafailovDirectPreferenceOptimization2024a), proposed more recently, simplifies this process. Instead of training a separate reward model, it treats preference data as a ranking problem (e.g., A > B) and directly updates the policy model using a derived objective.
DPO is simplier to implement, more efficient to train and has inspired variants like SimPO(@mengSimPOSimplePreference2024) and length-normalized DPO(@IterativeLengthRegularizedDirect) for greater flexibility.
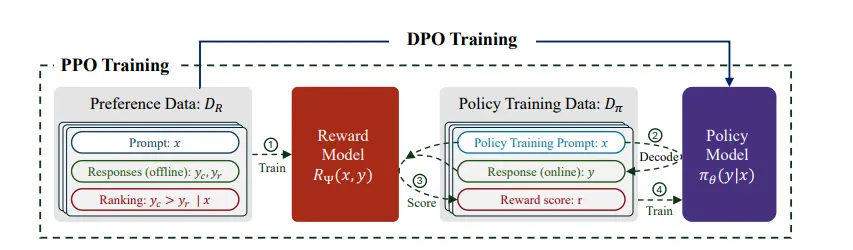
The figure below summarizes finding from a recent study on preference tuning in the Tulu system(@ivisonUnpackingDPOPPO2024a)
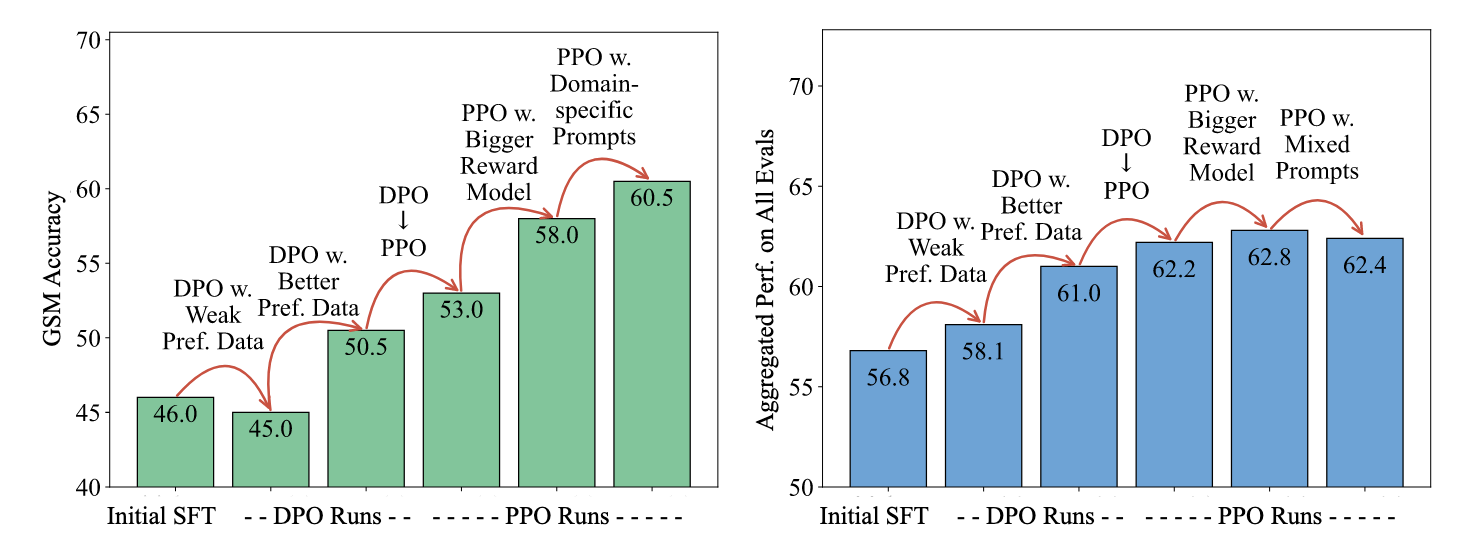
Key insights:
-
Data quality is the single most important factor: upgrading data let to a 56% -> 61% performance jump
-
PPO consistently outperforms DPO, but DPO’s simplicity makes it attractive for real-world deployment
-
Large reward models offer diminishing returins
-
Domain-specific prompting has a strong effect: to boost performance in areas like code, math, or creative writing, use targeted prompts and preference data from that domain.
Building Tulu 3
To build Tulu 3, the team systematically integrated the techniques disscussed earlier, optimizing each key component of the pipine (@lambertTulu3Pushing2025).
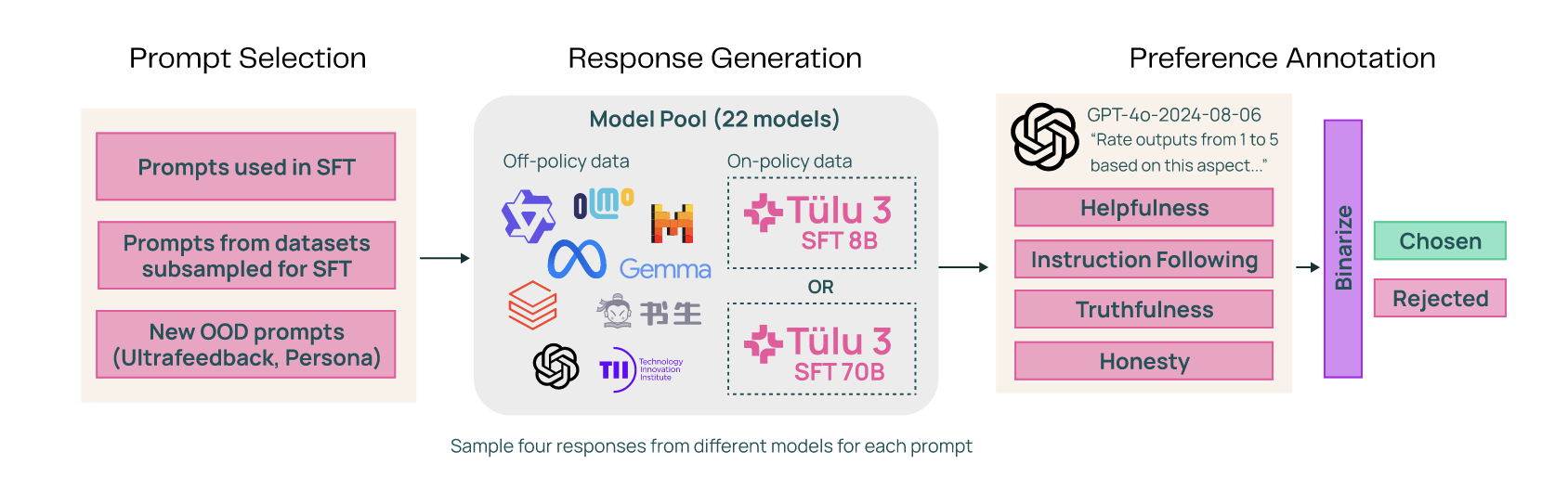
Data strategy and prompt selection
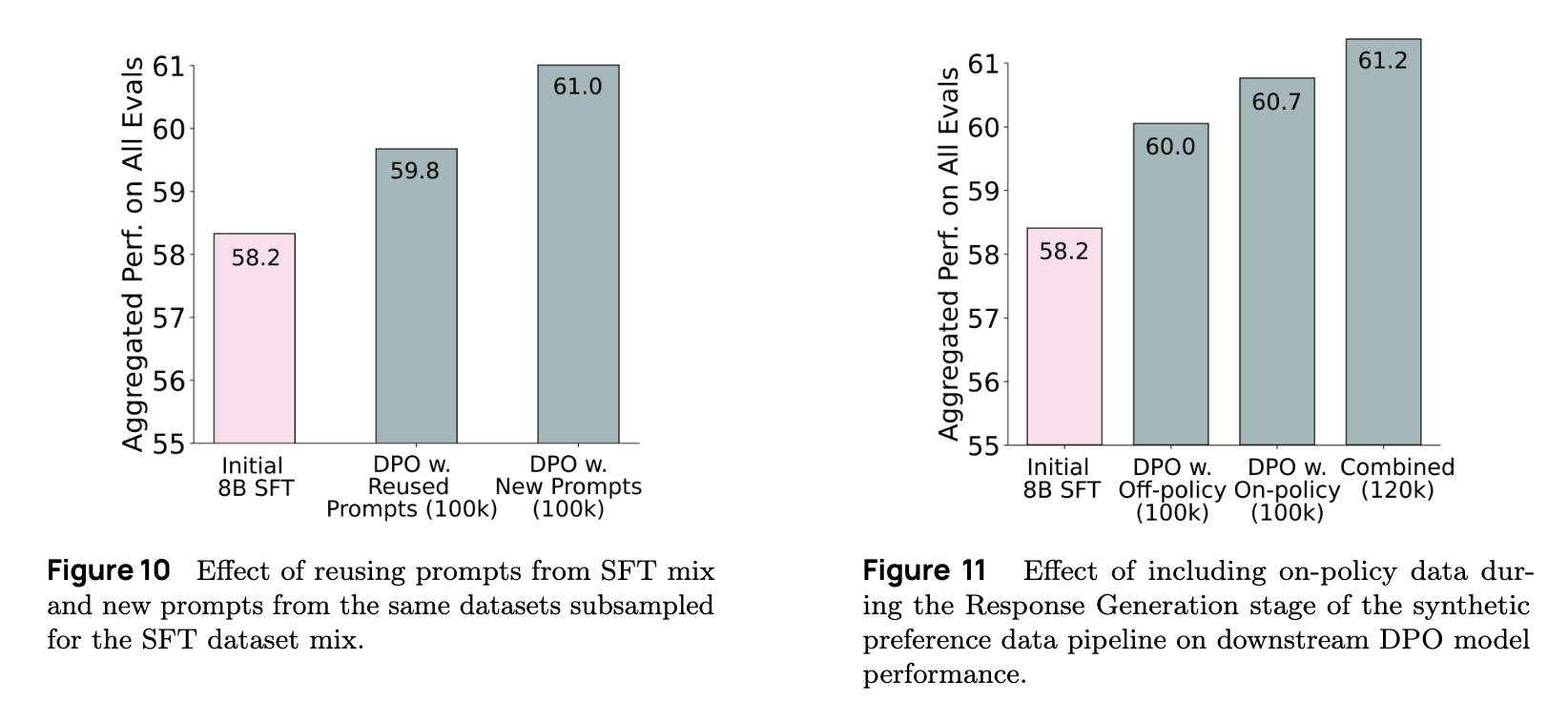
Since prompt selection plays a critical role, the team constructed a diverse dataset by combining different types of prompts:
- Prompts reused from the SFT - to retain continuity and maintain accuracy;
- New prompts not sees during SFT - to improve generalization;
- Out-of-domain prompts - to broaden the model’s ability to handle unfamiliar topics.
Response generation from multiple models
To generate high-quality preference data, the team collected responses from a range of models, from smaller Llama-7B variants to top-tier models like GPT-4o. This diversity enabled the creation of strong contrastive examples for preference learning.
Because of the importance of real-world performance, the team also included on-policy completions-responses generated by the current version of Tulu 3 itself. This helped ensure that preference data reflected how the model behaves in practice, allowing the system to learn which its own responses were better or worse than alternatives.
RLAIF and Preference Optimization
For preference modeling, the team used Reinforcement Learning from AI Feedback (RLAIF). They employed GPT-4o as a judge to evaluate response across four dimensions: helpfulness, instruction-following, truthfulness, and honesty. Each comparsion was binarized into a chosen vs. rejected label to support supervised preference training.
For optimization, they tasted several algorithms-including DPO, PPO, and CPO-but found limited gains from PPO. Given DPO’s simplicity and effectiveness, they adopted it as the main method.
Key findings of data ablations
The experiments revealed several critical insights:
- LLM as Judge: GPT-4o consistently provided the most realiable preference judgements across models.
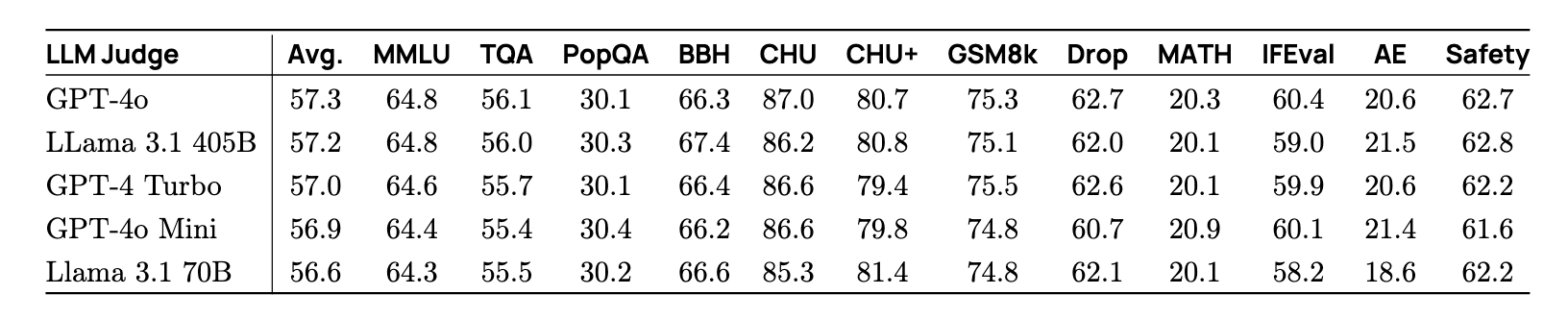
-
On-policy vs. Off-policy: Adding on-policy data yielded significantly better results than relying solely on off-policy data.
-
SFT vs. New Prompts: Introducing new and out-of-domain prompts improved overall performance.
With SFT and preference optimization complete, the team introduced a third novel step: Reinforcement Learning with Verifiable Rewards, which will be discussed in the next section.
Step 3: Reinforcement Learning with Verifiable Rewards
After completing preference tuning with methods like DPO, the Tulu team further examined how model performance evolved with increased training steps across different tasks:
- AlpacaEval: Performance quickly plateaued, showing limited further gains.
- IFEval: Accuracy in following complex instructions began to decline as training continued.
- GSM8K (Reasoning): Initially improved, but quickly overfit and degraded.
These trends suggest that for more complex tasks-like rasoning and instruction following-over optimization becomes a real concern, leading to performance drop-offs rather than improvements.
Rethinking the Reward Model
Trained on human preference data with neural reward model, these models assign scalar scores to responses (e.g., 10.5), indicating how “good” each responses is. However, these scores are often difficult to interpret, and may not align well with actual task objectives.
Consider a simple example:
Prompt: "What is 2 + 2?"
Expected Answer: "4"
A neural reward model might return scores like 1.0, 5.5, or 1000-offering little insight into correctness. For tasks with objectively verifiable outcomes, such scoring can be misleading.
This insight led the team to propose a simpler, more transparent solution: for tasks with verifiable outcomes-such as math and programming-it’s more effective to replace neural reward models with rule-based reward functions. Thses are easier to interpret, more aligned with task objectives, and offer a clearer signal for optimization.
RLVR Recipe and Analyses
The idea of replacing human preference signals with verifiable rewards is not unique. Earlier this year, the DeepSeek-V3 model adopted a similar philosophy, highlighting the growing momentum and promise of this direction.
Experimental Setup
- Starting point: Begain with the Tulu 3 model that had already been optimized via DPO
- Environment: Using targeted datasets paired with automatic verifiers to evaluate model outputs
- Algorithm: Returned to classical RL, specifically leveraging the DPO
- Datasets: Focused on three datasets where answer can be objectively verified: GSM8K, MATH, and IFEval.
Some verification tasks, like math reasoning, are straightforward: simply check if the predicted answer matches the correct one (e.g., if prediction == answer ->1, else -> 0). Others, such as constraint satisfication in instruction following, are more nuanced. These required checking which constraints are met and computing an overall satisfication rate. Nonetheless, the underlying principle remains similar.
Results and Observations
-
GSM8K: Consistent improvements were observed in both stages, with the most significant gains achieved when RLVR was applied after DPO. Notably, there was no sign of overfitting.
-
MATH: A slight dip in performance was seen when starting from DPO, but this quickly rebounded with continued training.
-
IFEval: Strong improvements emerged when starting the SFT checkpoint. However, gains from the DPO starting point were smaller-likely due to limited training data, according to the team’s analysis.
Scaling Up: From 7B to 405B
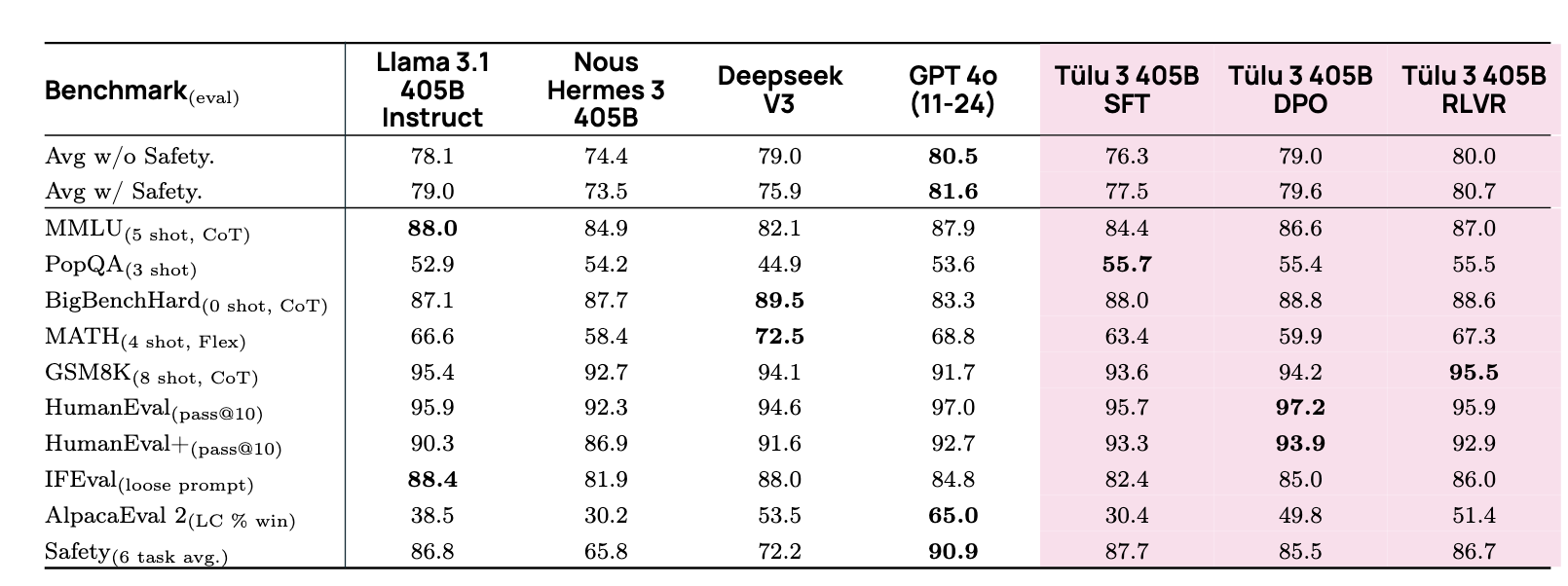
The Tulu team scaled this “three-stage” RLVR recipe (SFT -> DPO -> RLVR) across model sizes from 7B to 70B, and all the way up to 405B. The results were compelling:
- On various benchmarks, the final 405B model achieved performance on par with GPT-4o and surpassed DeepSeek V3.
- The 8B and 70B versions of Tulu 3 significantly outperformed other open-source models of similar scale, such as Qwen-Instruct and Llama-3-Instruct. In fact, these models reached performance levels comparable to small proprietary models like GPT-4o-mini and Claude 3 Haiku.
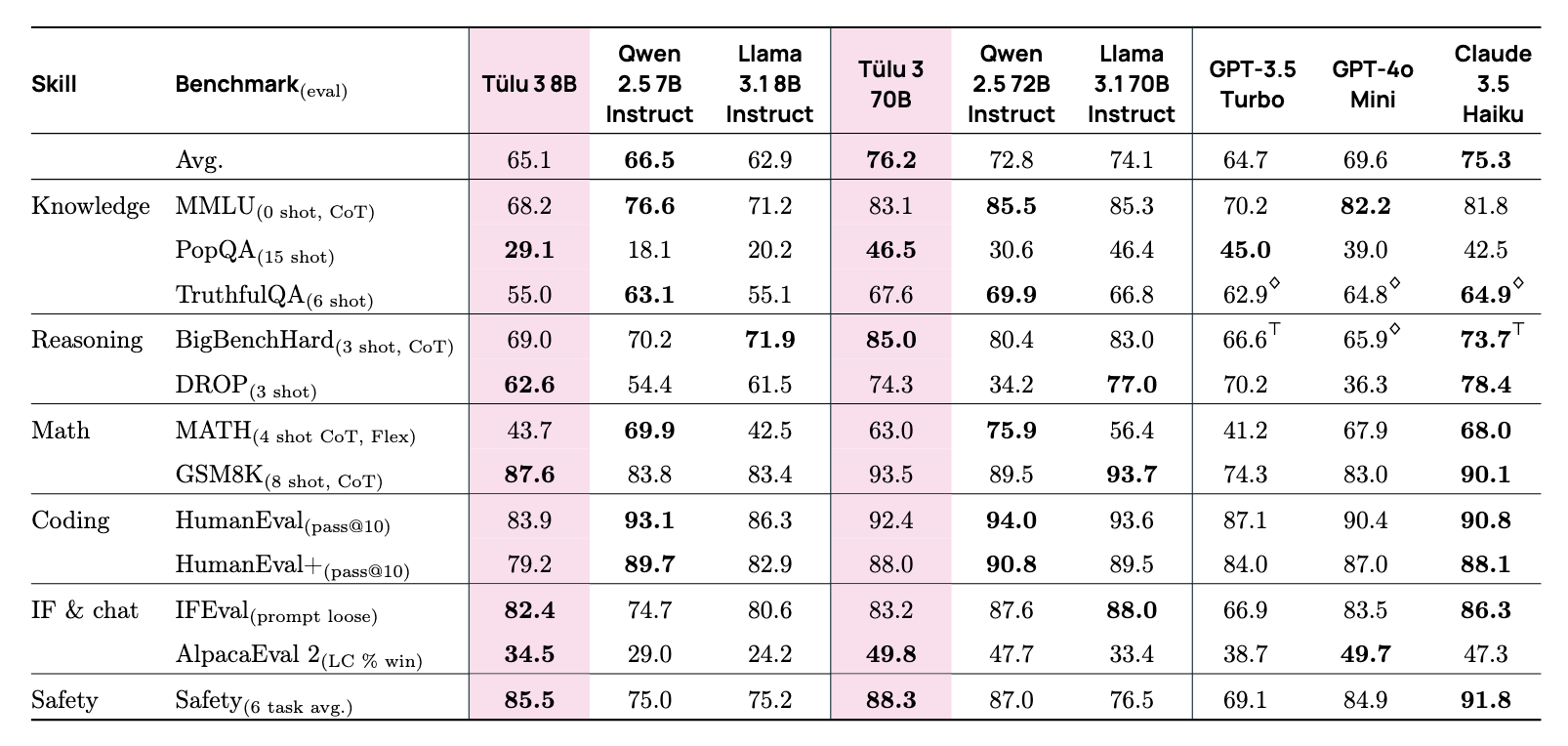
On particularly interesting insight: RLVR delivers greater gains at scale. This aligns with the team’s hypothesis that larger, stronger base models are better positioned to benefit from reinforcement via verifiable rewards.
Test-Time Inference
A significant area of current research focuses on enhancing model performance during the inference phase, particularly by improving reasoning capabilities at test time.
A Minimal Recipe for Reasoning & Test-Time Scaling
We begin by introducing the paper: s1: Simple test-time scaling (@muennighoffS1SimpleTesttime2025), which presents a minimalist yet powerful approach to improving model reasoning through test-time scaling.
Similar to other advancement in the language model domain, this method’s core lies in a meticulously curated dataset, named s1K. This dataset is then paired with a straightforward test-time scaling algorithm to produce the final s1 model.
Data Curation
This s1K dataset was constructed by filtering a large collection of advanced reasoning problems, including mathematics, logic puzzles, and probability questions. The complexity of this data significantly that of previous datasets like Tulu 3 (which primarily contains elementary to high school-level math), focusing instead on highly challenging problems, such as those found in Olympaid-level math competitions.
The data curation process involved several key steps:
- Initial collection: 59k problems spanning logic puzzles, mathematics, and other domains.
- Quality filtering: reduced to 52k
- Difficulty filtering: reduced further to 24k
- Diversity optimization: final selection of 1k unique and challenging questions
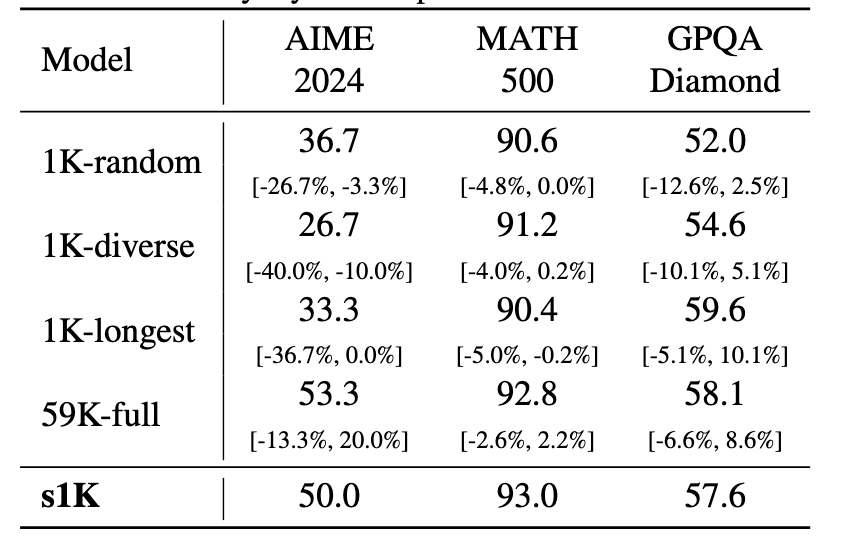
Interestingly, benchmark evaluations revealed that performance using curated 1k dataset was nearly identical to its performance using the full 59k dataset.
Distill Reasoning Traces & Answers
Once the problems were selected, they were annotated with detailed reasoning traces and answers. For instance, given the following problem:
An often-repeated fun fact is that humans produce more power per unit volume than stars. If the sun were the same size, but it produced the same amount of power per unit volume as a human, what would its surface temperature be?...
The researchers initially used Google’s Gemini model to generate CoT annotations. These annotations intentionally included “thinking” tokens (e.g., “that happens, but let me think more”) to capture the reasoning process.
In the latest version of s1, these annotations were replaced with results from DeepSeek R1, whcih unexpectedly led to a significant improvement in the final performance.
The resulting dataset spans a wide range of domains, from geometry and number theory to control theory and astronomy.
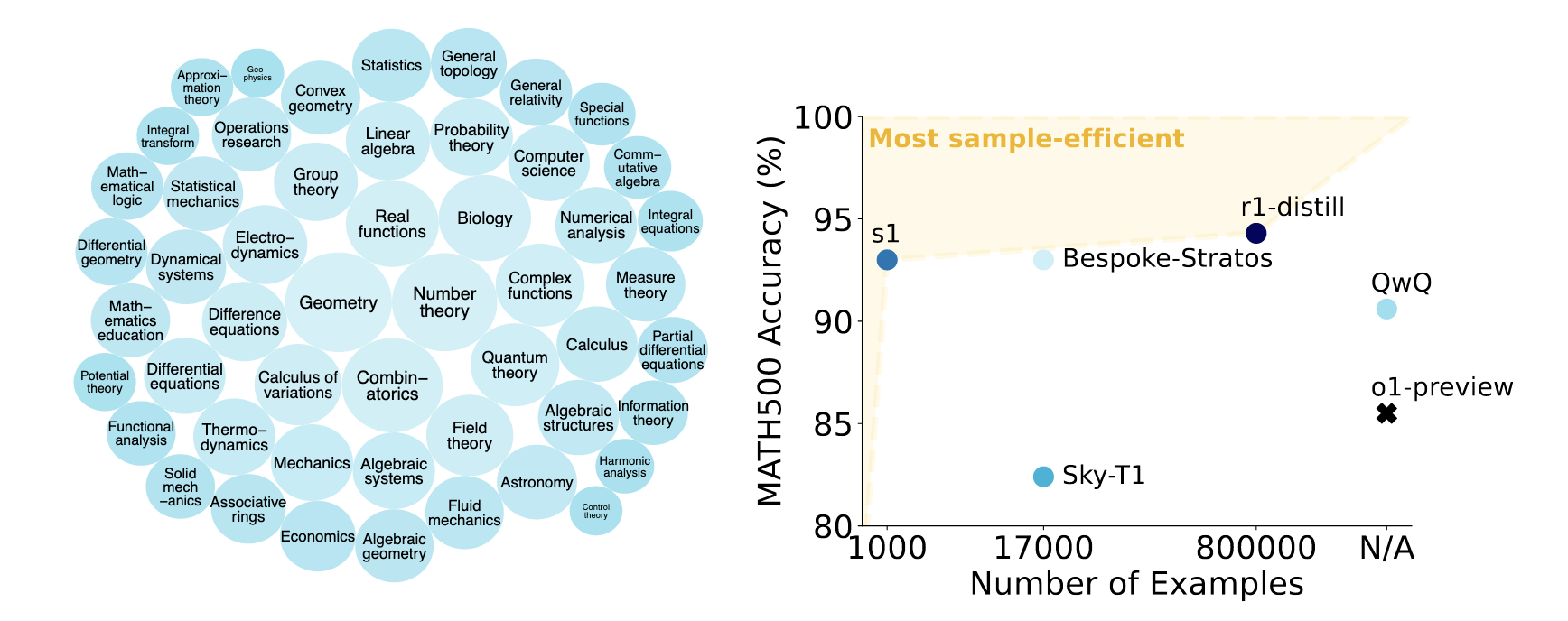
Test-Time Scaling with Budget Forcing
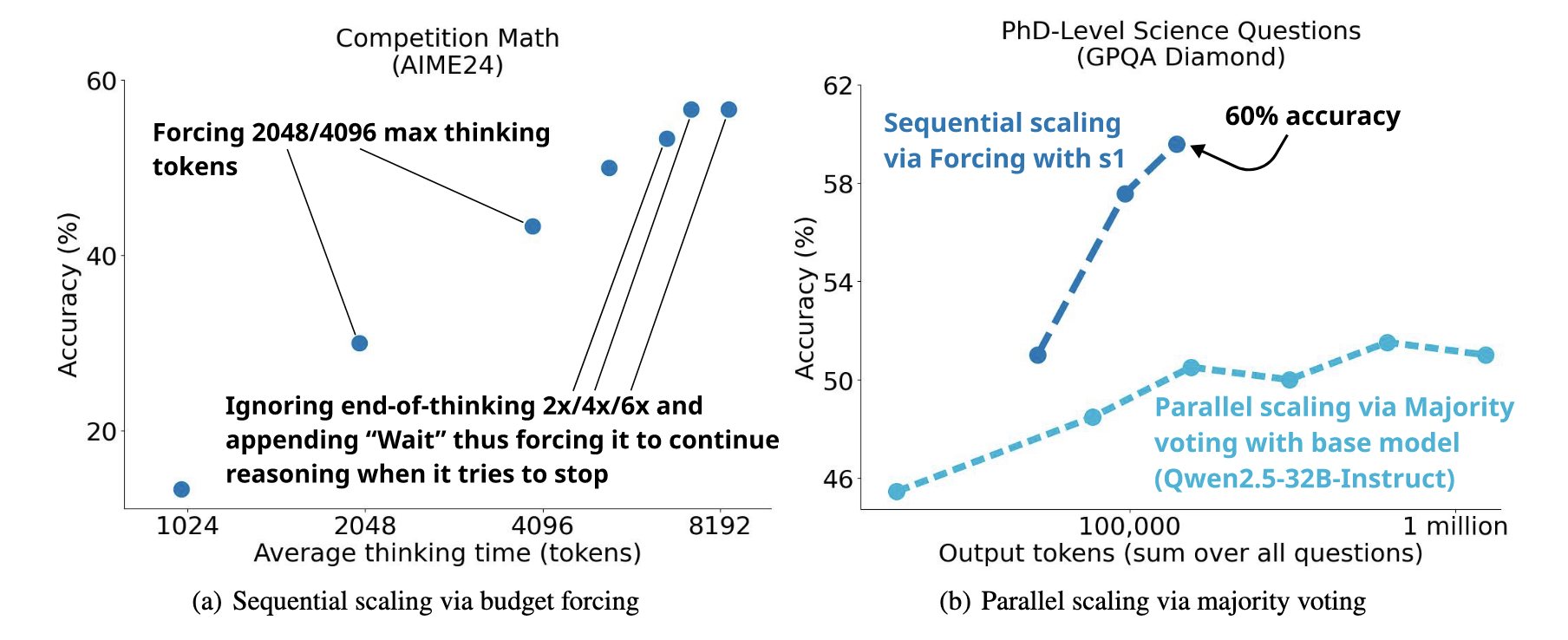
Researchers employed a surprisingly simple yet highly effective method called budget forcing.
The mechanism is straightforward: when the model generates a response to a prompt (e.g., “How many r’s are in the raspberry?”), its output length is checked against a predefined token budget. If the output is shorter than the budget, a special wait token is appended to the sequence, prompting the model to continue generating. The wait tokens acts as a hint, effectively telling the model, “We are not sure your answer is complete; please continue thinking.”

Training and Results
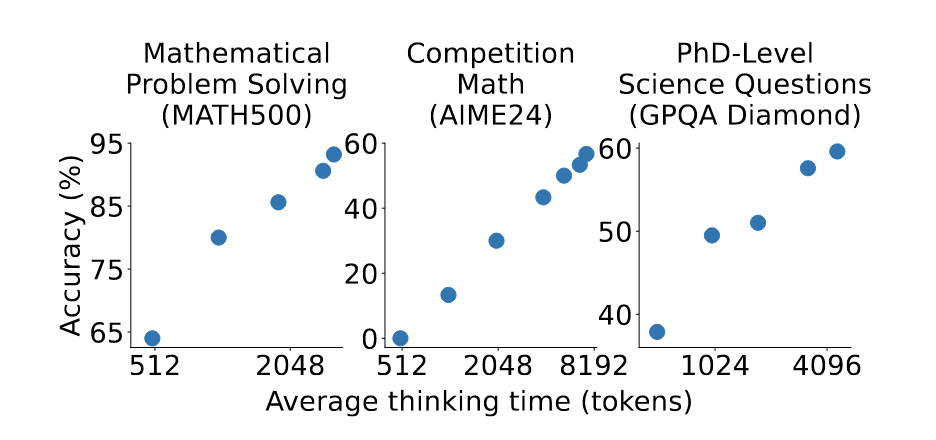
A Qwen 32B model was fine-tuned on the s1K data. The results demonstrate a clear scaling trend:
-
MATH500 Dataset: As the allocated token budget was increased from 512 to 2048, the model’s accuracy consistently improved, demonstrating a clear scaling law.
-
AIME24 & GPQA Datasets: On these more challenging datasets, the model was prompted to generated even longer responses (exceeding 8,000 tokens). Again, performance scaled positively with the number of generated tokens.
Researchers compared different test-time scaling methods. Budget forcing, a form of sequential scaling, produced a steeper performance curve and proved more effective than parallel scaling methods. Parallel approaches, such as generating multiple reasoning paths and using majority voting or self-consistency checks, showed some gains but were less significant.
Ablation studies further validated these findings. The performance different between the 1k s1K dataset and the full 59k dataset was minimal. However, using a randomly selected 1k sample resulted in significantly worse performance, underscoring the critical importance of high-quality, curated data.
Self-Guided Generation at Inference
The Self-RAG framework (@asaiSelfRAGLearningRetrieve2023) introduces an innovative approach based on RAG. Its unique characteristic is a language model trained not only to generate content but also to actively criticize its output and self-improve.
This process establishes a feedback loop. During generation, the model periodically inserts critic tokens to evaluate whether its response is sound and if the retrieved documents are relevant. This mechanism allows the model to dynamically optimize its answers during inference, enabling more powerful test-time scaling.
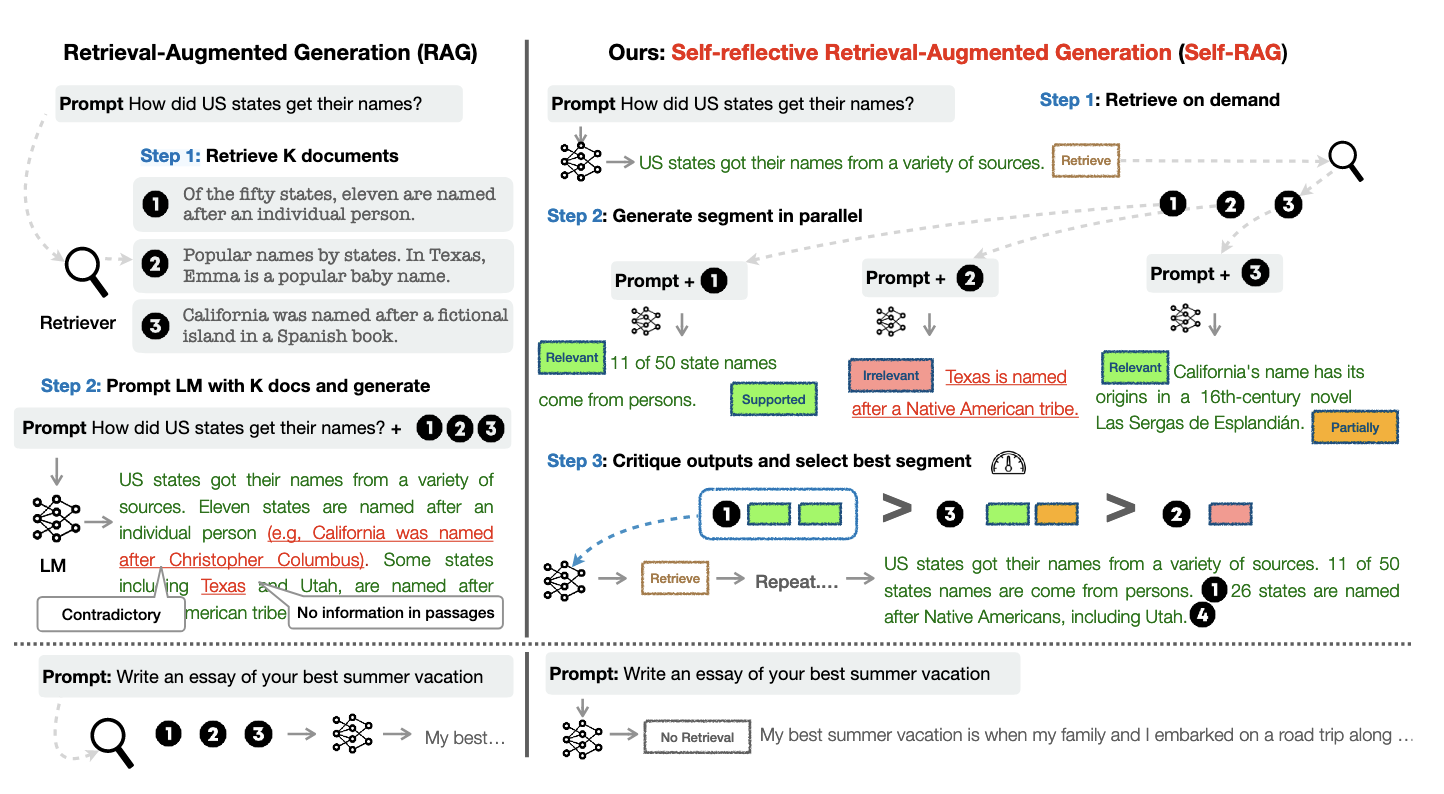
Further research shows this self-improvement loop is especially effective for tasks requiring substantial reasoning, such as synthesizing scientific literature and answering complex scientific question (@asaiOpenScholarSynthesizingScientific2024).
You can interact with a live demo at openscholar.allen.ai. There, you can input complex queries and observe how the model retrieves, integrates information from multiple sources, and constructs a well-reasoned answer.
Open Pre Training: OLMo
Early attempts showed that methods like RLVR are not effective on weaker base models. This makes strengthening the base model itself acritical priority. A modern “base model” isn’t built in a single pass of next-token prediction with a fixed learning rate; instead, it’s forged through a multi-stage training process.
Stage 1: Pre-training
This is the most resource-intensive phase, consuming about 99% of the total compute budget.
-
Objective: To learn broad knowledge and language patterns through next-token prediction.
-
Data: The model is trained on trillions of tokens of unstructured, diverse text sourced from the web, code repositories, academic papers, and more. The strategy is to use the largest and most diverse dataset possible within the given compute constrains.
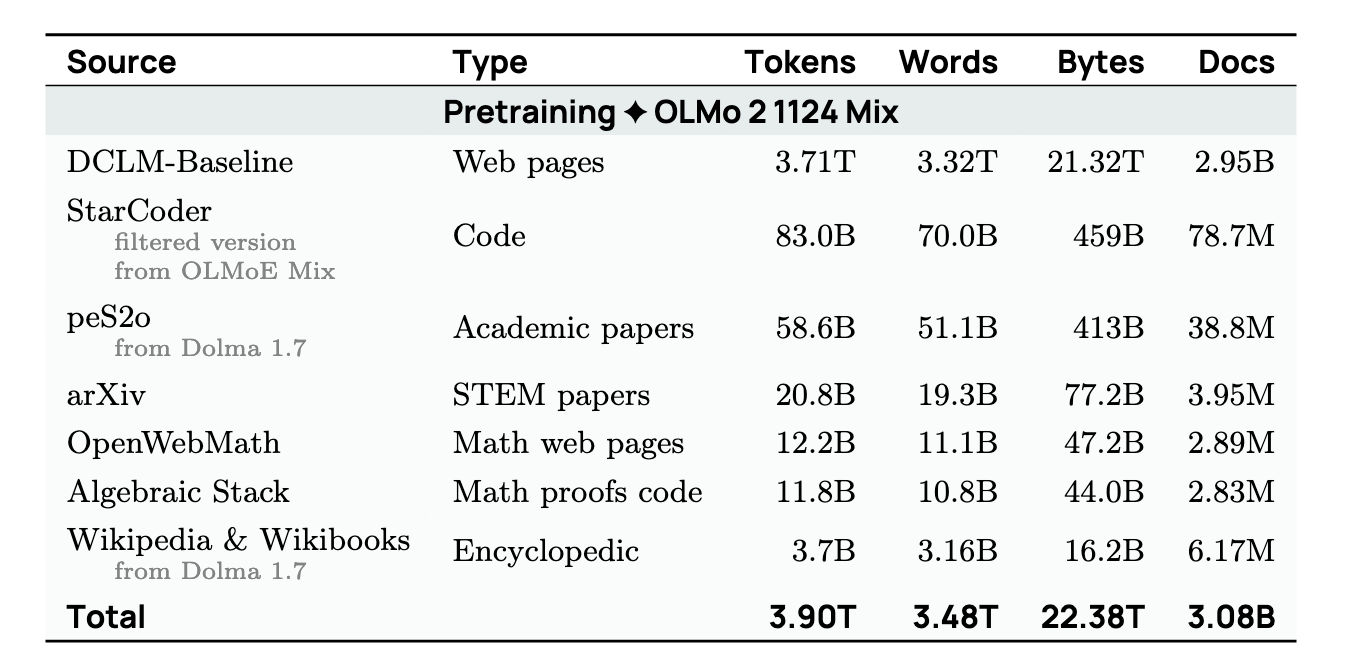
Stage 2: Mid-training
Following the extensive pre-training, the model enters a bried but crucial mid-training stage. This phase uses only about 1% of the compute budget but is vital for enhancing complex reasoning abilities.
-
Objective: To selectively strengthen specific capabilities, particularly addressing weaknesses from the pre-training stage.
-
Data: Unlike pre-training, this stage uses a smaller, highly curated dataset designed to:
- Boost reasoning and code: Upsample high-quality data focused on reasoning, mathematics, and code.
- Patch model weaknesses: Identify and fix shortcomings by “injecting” targeted knowledge.
- Introduce new knowledge: Incorporate valuable data that was too scarce to be used effectively during pre-training.
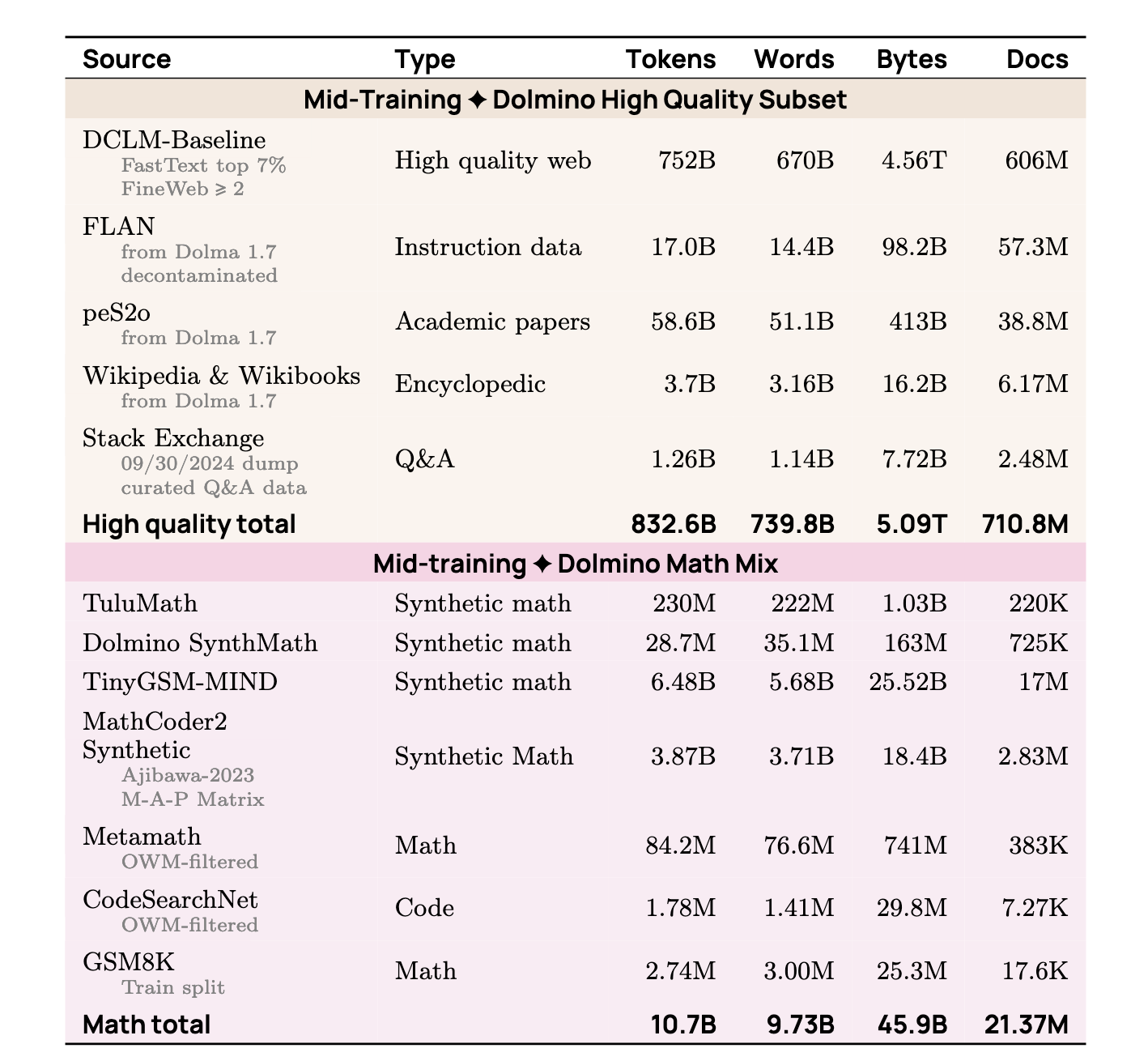
Results and Evaluation
This two-stage approach yields significant results. Evaluations of the OLMo 2 model show a dramatic performance boost after mid-training across multiple benchmarks. The most significant gains were observed in tasks requiring complex reasoning, such as GSM8K and DROP (reading comprehension with reasoning).
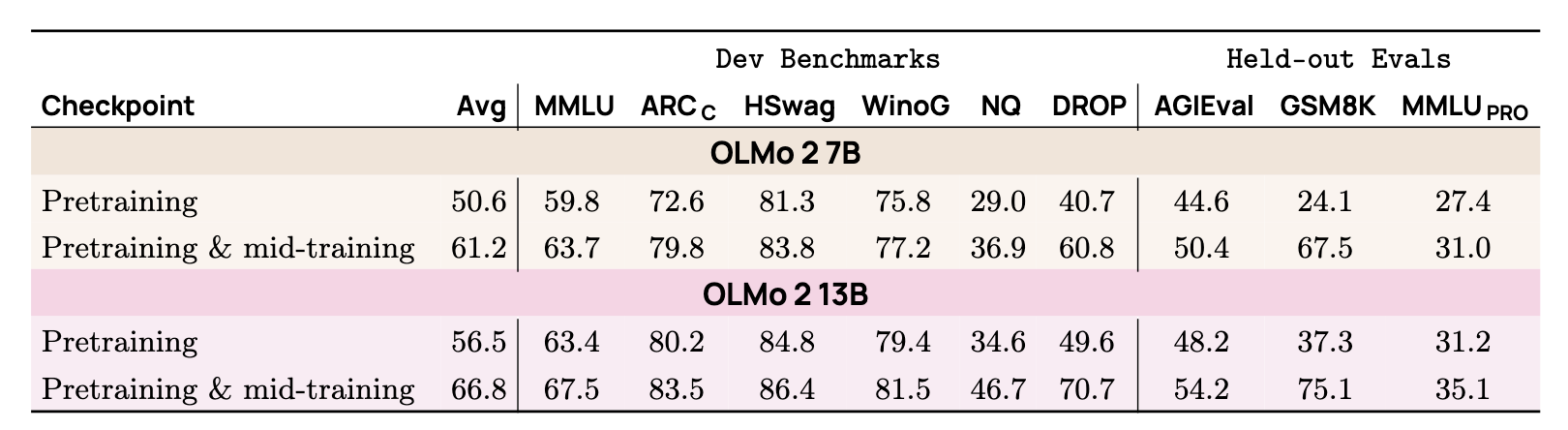
Ultimately, the optimized OLMo 2 model achieves performance that is on par with or better than models like Llama 3 8B.
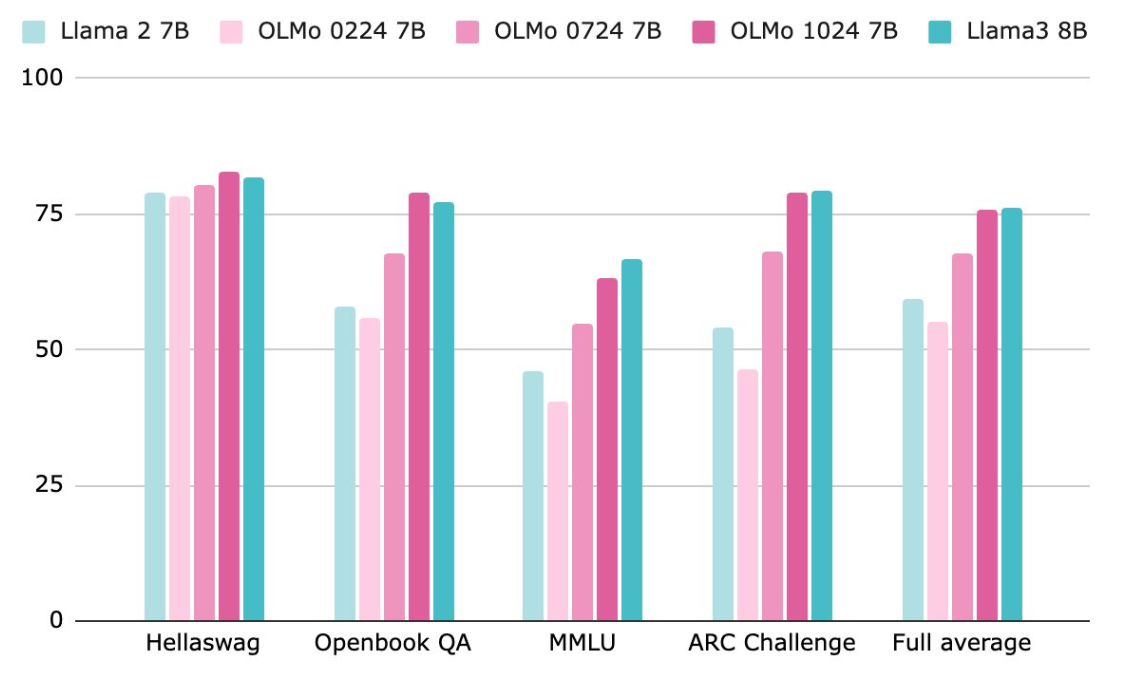
Conclusion and Outlook
While the AI field has made tremendous progress, significant challenges and opportunities remain. Areas like reasoning agents and domain-specific language models are particularly ripe for future research and innovation.

Reference
Asai, Akari, Jacqueline He, Rulin Shao, Weijia Shi, Amanpreet Singh, Joseph Chee Chang, Kyle Lo, et al. 2024. “OpenScholar: Synthesizing Scientific Literature with Retrieval-augmented LMs.” arXiv. https://doi.org/10.48550/arXiv.2411.14199.
Asai, Akari, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. 2023. “Self-RAG: Learning to Retrieve, Generate, and Critique Through Self-Reflection.” arXiv.org. https://arxiv.org/abs/2310.11511v1.
Christiano, Paul, Jan Leike, Tom B. Brown, Miljan Martic, Shane Legg, and Dario Amodei. 2023. “Deep Reinforcement Learning from Human Preferences.” arXiv. https://doi.org/10.48550/arXiv.1706.03741.
Ge, Tao, Xin Chan, Xiaoyang Wang, Dian Yu, Haitao Mi, and Dong Yu. 2025. “Scaling Synthetic Data Creation with 1,000,000,000 Personas.” arXiv. https://doi.org/10.48550/arXiv.2406.20094.
“Iterative Length-Regularized Direct Preference Optimization: A Case Study on Improving 7B Language Models to GPT-4 Level.” n.d. https://arxiv.org/html/2406.11817v1. Accessed June 6, 2025.
Ivison, Hamish, Yizhong Wang, Jiacheng Liu, Zeqiu Wu, Valentina Pyatkin, Nathan Lambert, Noah A. Smith, Yejin Choi, and Hannaneh Hajishirzi. 2024. “Unpacking DPO and PPO: Disentangling Best Practices for Learning from Preference Feedback.” arXiv. https://doi.org/10.48550/arXiv.2406.09279.
Lambert, Nathan, Jacob Morrison, Valentina Pyatkin, Shengyi Huang, Hamish Ivison, Faeze Brahman, Lester James V. Miranda, et al. 2025. “Tulu 3: Pushing Frontiers in Open Language Model Post-Training.” arXiv. https://doi.org/10.48550/arXiv.2411.15124.
Meng, Yu, Mengzhou Xia, and Danqi Chen. 2024. “SimPO: Simple Preference Optimization with a Reference-Free Reward.” arXiv. https://doi.org/10.48550/arXiv.2405.14734.
Muennighoff, Niklas, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candès, and Tatsunori Hashimoto. 2025. “S1: Simple Test-Time Scaling.” arXiv. https://doi.org/10.48550/arXiv.2501.19393.
OLMo, Team, Pete Walsh, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Shane Arora, Akshita Bhagia, et al. 2025. “2 OLMo 2 Furious.” arXiv. https://doi.org/10.48550/arXiv.2501.00656.
Rafailov, Rafael, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. 2024. “Direct Preference Optimization: Your Language Model Is Secretly a Reward Model.” arXiv. https://doi.org/10.48550/arXiv.2305.18290.
Schulman, John, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. “Proximal Policy Optimization Algorithms.” arXiv. https://doi.org/10.48550/arXiv.1707.06347.
“Tülu 3 Opens Language Model Post-Training up to More Tasks and More People Ai2.” n.d. https://allenai.org/blog/tulu-3. Accessed May 18, 2025.