The following insights are drawn from the Reasoning with o1 video course by DeepLearning.ai.
This article explores how to effectively prompt and utilize the new generation of reasoning models. Models released over the past year have demonstrated remarkable progress in reasoning and planning tasks. OpenAI has deeply optimized Chain of Thought (CoT) processing, using reinforcement learning to fine-tune models so they automatically integrate step-by-step reasoning into their response process.
While current model performance is already impressive, the more significant long-term development is reasoning-time scalability. Reasoning model performance improves not only with increased training compute but also with the thinking time allocated during inference (test-time or inference-time compute). This provides an entirely new dimension for scaling large model performance.
However, reasoning models aren’t suitable for every scenario. This article will cover the types of tasks reasoning models excel at, and when you might need smaller, faster models, or even hybrid approaches. This article structure includes:
- Introduction to Reasoning Models
- Designing Prompts for Reasoning Models
- Using Reasoning Models for Planning
- LLMs as Judges
- Meta Prompting
Introduction
Before reasoning model emerged, most AI models behaved like children-always blurting out the first thing that came to mind. The revolutionary breakthrough of reasoning models lies in learning a valuable skills: think before you speak. This enables them to achieve unprecedented performance levels in complex tasks including mathematics, programming, science, stragegic planning, and logical reasoning.
CoT: The Core Mechanism
The key advantage of reasoning models lies in their native integration of chain-of-thought reasoning process (@weiChainofThoughtPromptingElicits2023). Let’s understand this through an example. When we present the model with a letter scrambling problem:
oyfjdnisdr rtqwainr acxz mynzbhhx -> Think step by step
Use the example above to decode:
oyekaijzdf aaptcg suaokybhai ouow aght mynznvaatzacdfoulxxz
Rather than providing an immediate answer, the model engages in the following thought process: Cipher Decoding Process
- Problem Understanding: Analyze the given example to identify patterns
- Hypothesis Formation: Consider whether it’s an anagram or some form of cipher
- Hypothesis Testing: Notice that the encrypted text is exactly twice the length of the orginal
- Iternative Refinement: When the first hypothesis fails, use existing information to form new hypotheses
- Optimal Path Discovery: Through continuous trial and error, ultimately find the correct solution
This process encompasses the key steps humans use when solving complex problems:
- Problem and solution space identification
- Hypothesis development and testing
- Approach adjustment and path selection
What makes reasoning model so speical is that you don’t need complex prompts to guide them through deep thinking. This means reasoning models requires less contextual prompting to produce high-quality results for complex tasks, truly achieving the leap from “quick reaction” to “deep thinking”.
Of course, this deep reasoning comes with trade-offs - when using reasoning models, you need to balance reasoning quality against response speed.
Breakthrough and Performance Leap
The performance leap of reasoning model is primarily attributed to two key breakthroughs:
1. Inference-time Compute
Research has found that in the model’s post-training phase, the more reinforcement learning conducted, the higher the model’s accuracy. But more surprisingly, allowing models to “think longer” during inference significanly improves result quality. By giving models more thinking time, even with the same model parameters and training data, superior performance can be achieved.
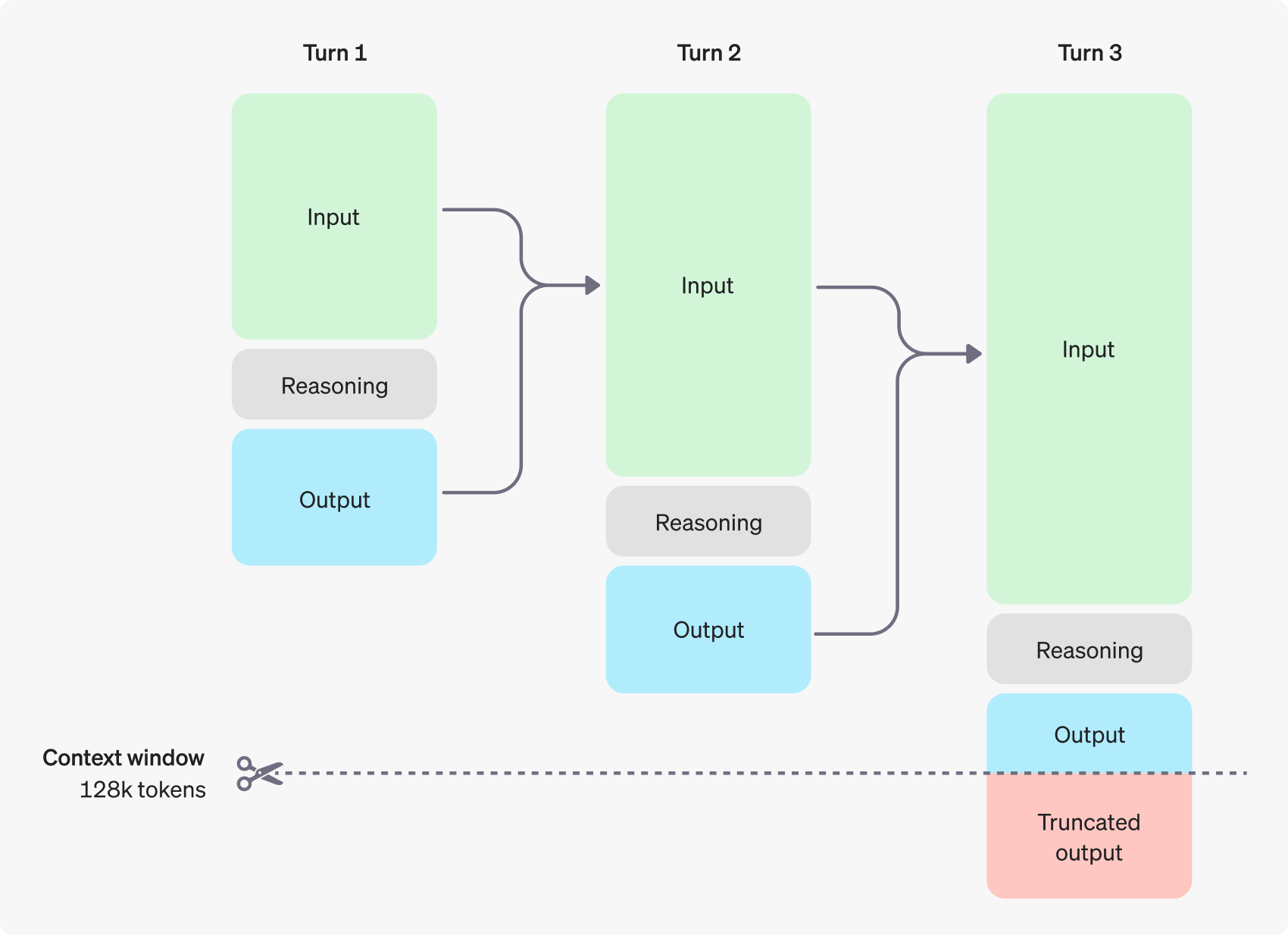
2. Consensus Voting
Another key breakthrough is teaching models to verify outputs through consensus voting. The mechanism works as follows:
- Generate multiple different solutions for the same problem
- Train the model select the most frequently occuring solution as the final answer
In Minerva’s experiments, MATH benchmark accuracy improved from 33.6% to 50.3% (@brownLargeLanguageMonkeys2024). Experiments showed that the consensus mechanism stabilizes at around 100 samples, meaning significant performance improvements can be achieved without generating massive number of samples.
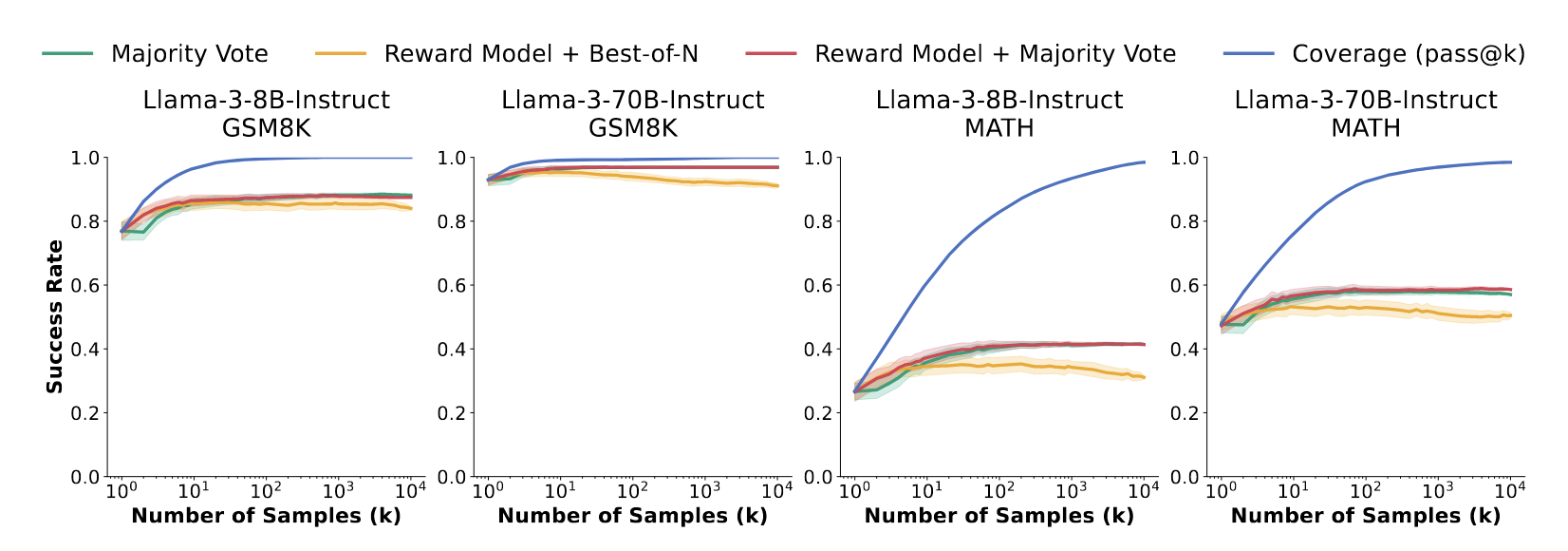
These breakthroughs have yielded remarkable results: Taking GPT-4o and o1 models as examples:
- Mathematical Olympiad-level abilities (AIME 2024): GPT-4o achieved 13% accuracy, while o1 reached 83%
- Coding abilities: GPT-4o scored 11%, while o1 achieved 89%
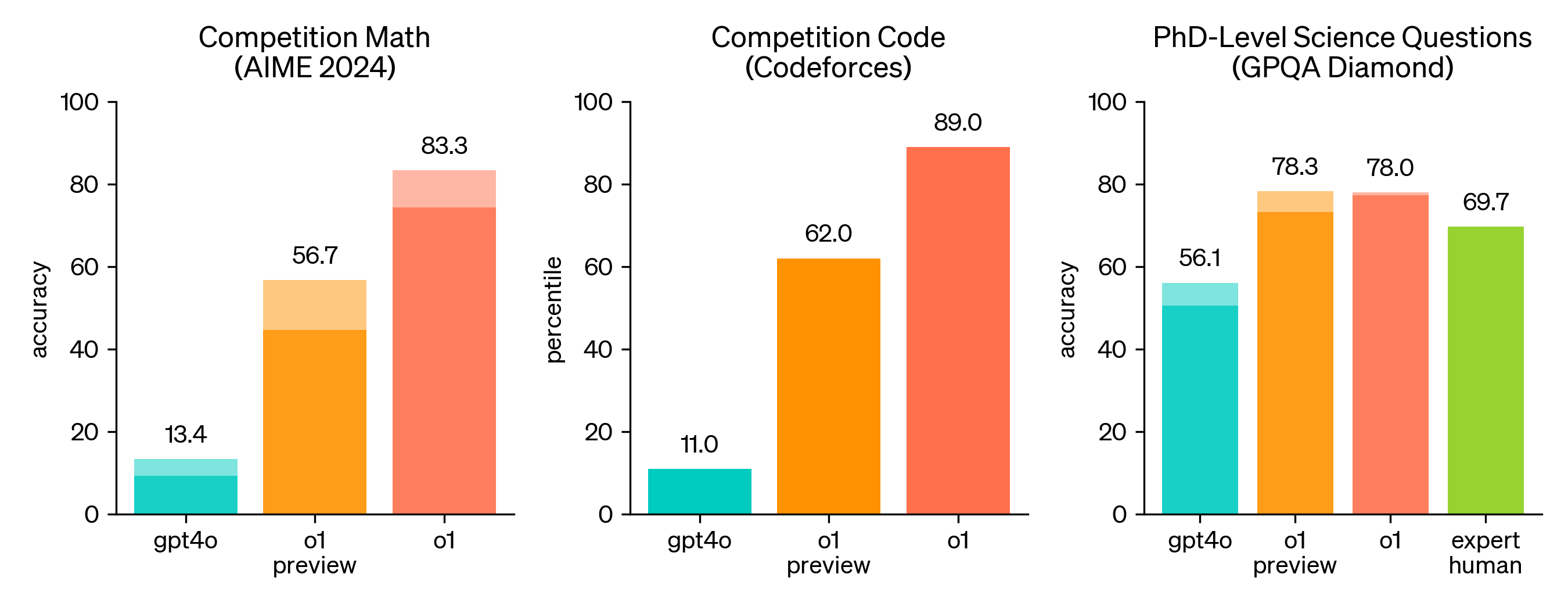
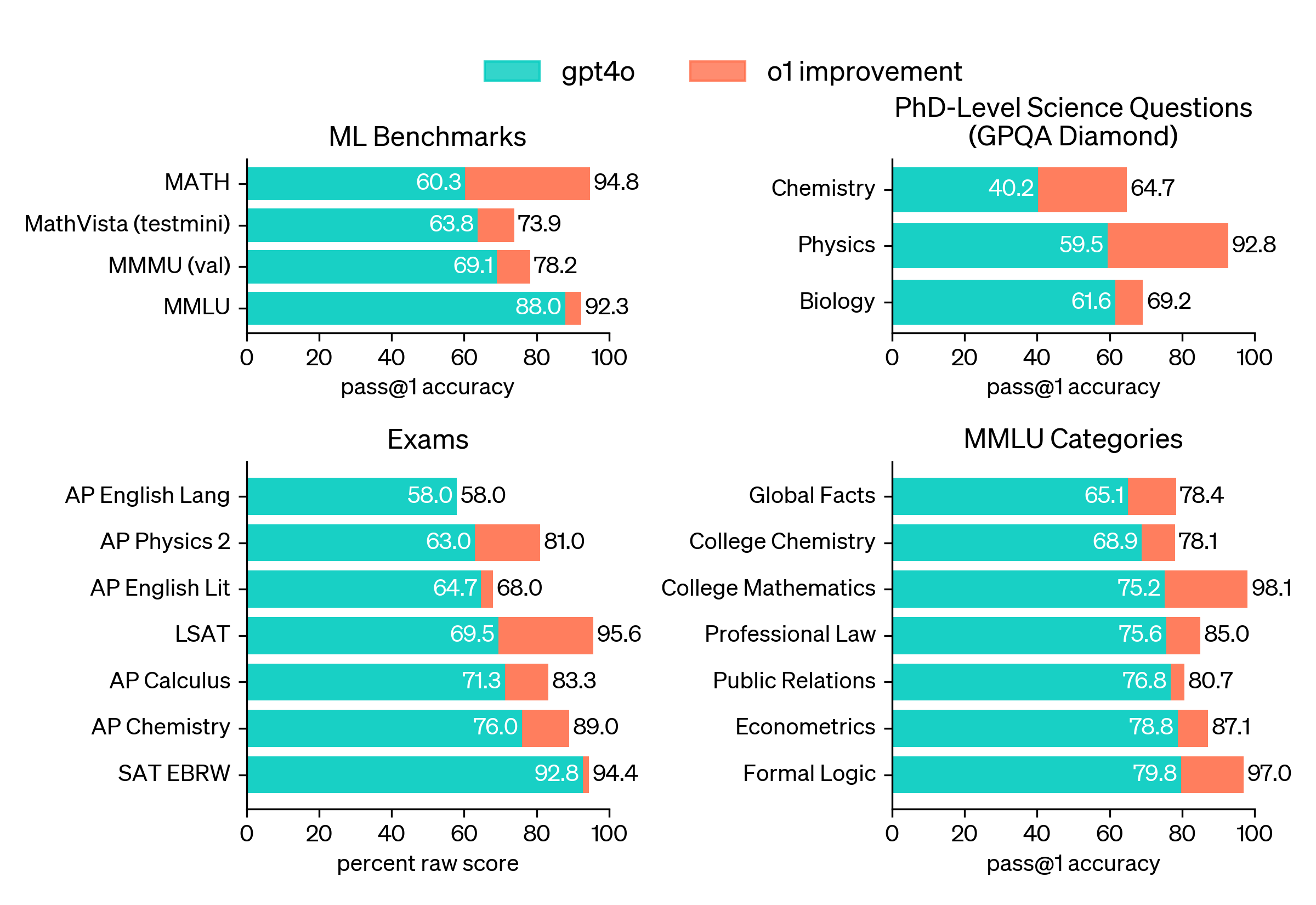
- General Mathematics (MATH): o1 achieved a massive 30% improvement over GPT-4o
- College-level Knowledge (MMLU): o1 improved across all categories, with college mathematics accuracy reaching an astounding 98.1%
Emerging Capabilities of Reasoning Models
Beyond leaps in traditional benchmarks, reasoning models have demonstrated some execiting emerging capabilities.
1. Abstract Reasoning
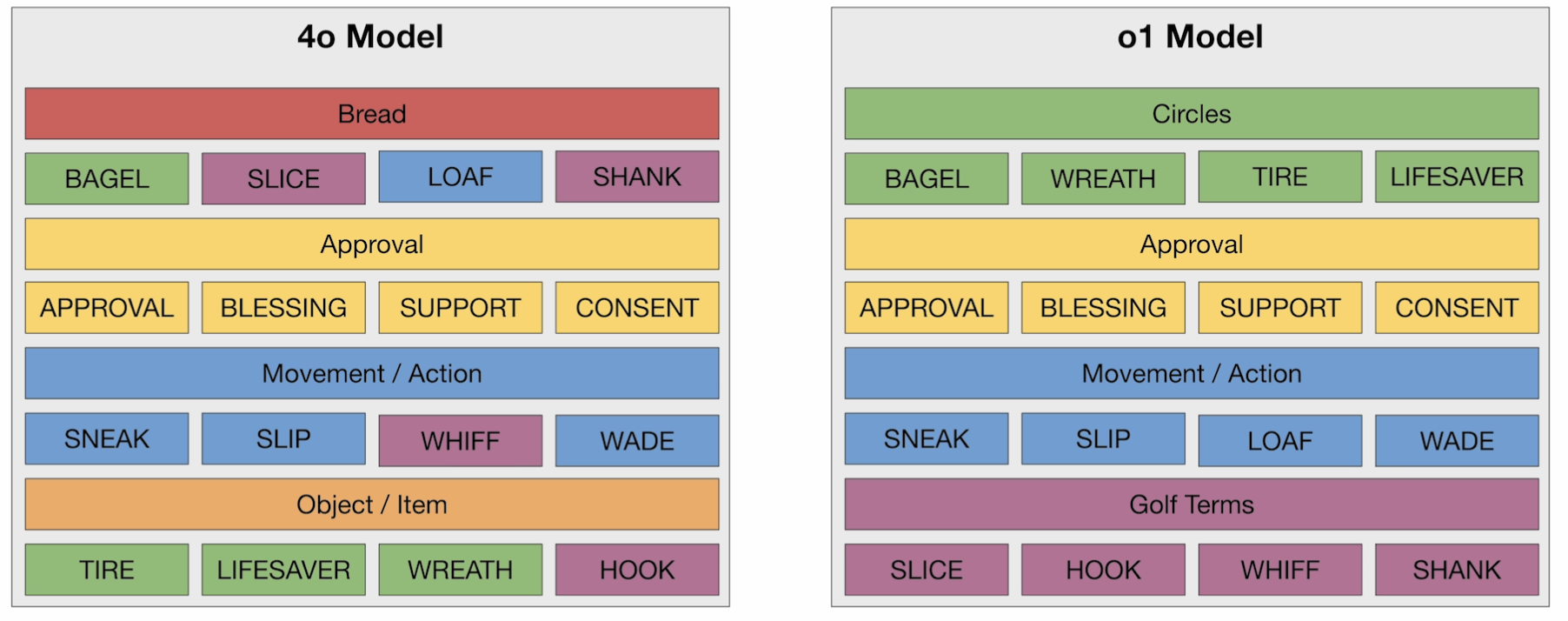
When given 16 words and asked to find underlying categories and correctly classify them, GPT-4o’s performance was somewhat random, identifying only two categories with errors. Meanwhile, o1 perfectly identified all four categories and correctly classified all 16 words. This capability is crucial for handing abstract problems beyond standardized tests.
2. Generator-Verifier Gap
For many problems (such as mathematics, programming, puzzles), verifying a good answer is much easier than generating one from scratch. Reasoning models excel at leveraging this principle. They can:
- Generate an initial solution
- Verify it and identify issues
- Iterate based on feedback, gradually approaching the perfect answer
When this generator-verifier gap exists, we can trade more computation at inference time for better performance.
3. Potential Application Areas
This powerful reasoning capability makes these models highly promising in the following domains:
- Data Analysis: Interpreting complex datasets, such as genomic sequencing results in biology
- Scientific Computing: Writing and debudding specialized code for computational fluid dynamics or astrophysics simulations
- Experimental Design: Proposing new experimental approaches in chemistry or explaining complex physics experimental results
- Algorithm Development: Assisting in creating or optimizing data analysis algorithms bioinformatics
- Literature Synthesis: Reasoning across multiple research papers to form coherent conclusions
Effective Prompting
Here are four key prompting principles that have emerged for working with reasoning models. While these principles don’t cover every scenario, they can help you explore and understand how this new generation of reasoning models differs from others.
Keep It Simple and Direct
When writing prompts, aim for clarity and conciseness. Direct instructions often produce the best results, while complex descriptions and excessive background information can actually interfere with the model’s internal reasoning process.
No Need for Explicit Chain-of-Thought
Reasoning models no longer require manually adding “think step by step” or breaking down tasks steps in your prompts like previous models did. These models have been trained to natually provide effective explanations and reasoning processes in their responses. Therefore, starting with a simple, direct prompt is always the best approach.
Of course, for highly specialized tasks or complex contexts, you might still consider adding CoT-style step-by-step peompts. However, it’s recommended to start with simple prompts and adjust details based on output quality.
For example: Suppose you need a function that outputs SMILES IDs for all molecules related to insulin.
Good Prompt
"Generate a function that outputs the SMILES IDs for all the molecules involved in insulin."
Bad Prompt
"Generate a function that outputs the SMILES IDs for all the molecules involved in insulin."
"Think through this step by step, and don't skip any steps:"
"- Identify all the molecules involve in insulin"
"- Make the function"
"- Loop through each molecule, outputting each into the function and returning a SMILES ID"
"Molecules:"
Use Structured Prompts
When your prompt content becomes complex, use separators (like Markdown, XML tags, or quotes) to break it into different sections. This structured format not only improves model accuracy but also makes troubleshooting much easier.
Example: Customer service assistant scenario
"<instructions>You are a customer service assistant for AnyCorp, a provider"
"of fine storage solutions. Your role is to follow your policy to answer the user's question. "
"Be kind and respectful at all times.</instructions>\n"
"<policy>**AnyCorp Customer Service Assistant Policy**\n\n"
"1. **Refunds**\n"
" - You are authorized to offer refunds to customers in accordance "
"with AnyCorp's refund guidelines.\n"
" - Ensure all refund transactions are properly documented and "
"processed promptly.\n\n"
"2. **Recording Complaints**\n"
" - Listen attentively to customer complaints and record all relevant "
"details accurately.\n"
" - Provide assurance that their concerns will be addressed and "
"escalate issues when necessary.\n\n"
"3. **Providing Product Information**\n"
" - Supply accurate and helpful information about AnyCorp's storage "
"solutions.\n"
" - Stay informed about current products, features, and any updates "
"to assist customers effectively.\n\n"
"4. **Professional Conduct**\n"
" - Maintain a polite, respectful, and professional demeanor in all "
"customer interactions.\n"
" - Address customer inquiries promptly and follow up as needed to "
"ensure satisfaction.\n\n"
"5. **Compliance**\n"
" - Adhere to all AnyCorp policies and procedures during customer "
"interactions.\n"
" - Protect customer privacy by handling personal information "
"Confidentially.\n\n"
"6. **Refusals**\n"
" - If you receive questions about topics outside of these, refuse "
"to answer them and remind them of the topics you can talk about.</policy>\n"
We use <instructions> tags to clearly define the task role and behavioral guidelines. Then we provide structured policy content through <policy> tags, making it clear to the model what “policy” specifically refers to. This way, the model clearly understands its role, the rules it should follow, and the tasks it needs to complete, with clear boundaries and minimal confusion.
Show rather than Tell
Instead of explaining your requirements through lengthy text descriptions, provide a relevant example that allows the model to intuitively understand the task domain and output format you expect.
Here’s and example: We still use <prompt> and <policy> to define roles and rules, but we add an <example> tag that directly provides a sample question-answer pair to help the model understand the expected response format and citation style.
"<prompt>You are a lawyer specializing in competition law, "
"assisting business owners with their questions.</prompt>\n"
"<policy>As a legal professional, provide clear and accurate "
"information about competition law while maintaining "
"confidentiality and professionalism. Avoid giving specific "
"legal advice without sufficient context, and encourage clients "
"to seek personalized counsel when necessary.</policy>\n"
"""<example>
<question>
I'm considering collaborating with a competitor on a joint marketing campaign. Are there any antitrust issues I should be aware of?
</question>
<response>
Collaborating with a competitor on a joint marketing campaign can raise antitrust concerns under U.S. antitrust laws, particularly the Sherman Antitrust Act of 1890 (15 U.S.C. §§ 1–7). Section 1 of the Sherman Act prohibits any contract, combination, or conspiracy that unreasonably restrains trade or commerce among the states.
**Key Considerations:**
1. **Per Se Illegal Agreements:** Certain collaborations are considered automatically illegal ("per se" violations), such as price-fixing, bid-rigging, and market allocation agreements. For example, in *United States v. Topco Associates, Inc.*, 405 U.S. 596 (1972), the Supreme Court held that market division agreements between competitors are per se illegal under the Sherman Act.
2. **Rule of Reason Analysis:** Collaborations that are not per se illegal are evaluated under the "rule of reason," which assesses whether the pro-competitive benefits outweigh the anti-competitive effects. In *Broadcast Music, Inc. v. Columbia Broadcasting System, Inc.*, 441 U.S. 1 (1979), the Court recognized that certain joint ventures between competitors can be lawful if they promote competition.
3. **Information Sharing Risks:** Sharing competitively sensitive information, such as pricing strategies or customer data, can lead to antitrust violations. The Department of Justice and the Federal Trade Commission caution against exchanges that could facilitate collusion (*Antitrust Guidelines for Collaborations Among Competitors*, 2000).
**Recommendations:**
- **Define the Scope:** Clearly delineate the parameters of the collaboration to focus on the marketing campaign without involving competitive aspects like pricing or market division.
- **Implement Safeguards:** Establish protocols to prevent the exchange of sensitive information that is not essential to the marketing effort.
- **Legal Consultation:** Given the complexities of antitrust laws, consult with a legal professional to ensure the collaboration complies with all legal requirements.
**Conclusion:**
While joint marketing campaigns between competitors are not inherently illegal, they must be structured carefully to avoid antitrust pitfalls. Legal guidance is essential to navigate these issues and to design a collaboration that achieves your business objectives without violating antitrust laws.
</response>
</example>"""
In practice, you can use these principles as your default starting point and gradually adjust based on task complexity. If the model doesn’t perform as expected, rather than adding more explanations, prioritize adding or improving examples first. This typically leads to more robust results.
Task Planning with Reasoning Models
When building multi-step logical tasks, efficiently leveraging models with different capabilities is key to improving performance and reducing cost. Reasoning models are especially strong in multi-step planning and problem solving. Given a task scenario, constraints, and available tools, they can quickly generate structured, logical solutions.
However, using a reasoning model to execute every step can lead to high latency and unnecessary computational overhead. To address this, we adopt a two-stage strategy:
- Use a reasoning model to generate a task plan.
- Use a standard model to execute each step of the plan.
This design is widely adopted in real-world system. It combines intelligent reasoning with fast, cost-effective execution.
Plan Generation + Execution
The entire workflow can be broken down into three stages:
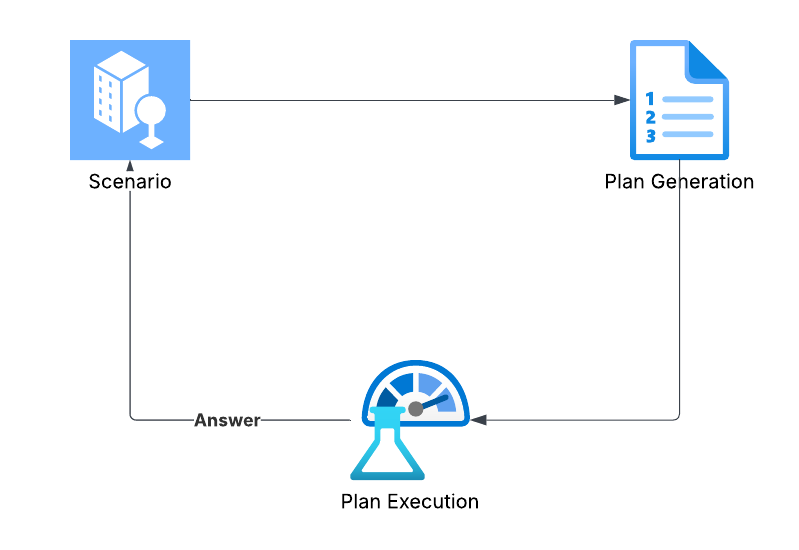
- Input Scenario & Constraints: The user submits a task request that requires multi-step logical reasoning.
- Generate Solution Plan: The reasoning model uses the task context, tool descriptions, and constraints to generate a multi-step executable plan.
- Execute Plan Steps: A standard model (in this case, DeepSeek-V3) executes each steps of the plan in sequence to produce the final result.
Core Implementation
We start with a scenario, usually a customer request that requires multi-step reasoning. This scenario is passed to a planning model (e.g., deepseek-reasoner) which is equipped with tools and planning instruction. It produces a structured execution plan. We then pass this plan to a execution model (e.g., deepseek-chat) to carry out each step. Once all steps are complete, the final answer is returned to the user.
Planning Model Prompt Design
The core task of the planning model is to understand the scenario and generate a structured execution plan. Its prompt consists of several key components:
- Role Setting: Defines the model’s role and tasked with create an executable plan to fulfill a user request.
- Tool Description: List the functions available to execution model. The planning model does not call these functions directly but must understand their capabilities to design a valid plan.
- Plan Structure Instructions: Guidelines for organizing steps to ensure the execution model can parse and execute them accuracy. Guidelines for organizing steps to ensure the chat model can parse and execute them accurately.
# Prompt for the planning model
planning_prompt = """
You are a supply chain management assistant. The first input you will receive will be a complex task that needs to be carefully reasoned through to solve.
Your task is to review the challenge, and create a detailed plan to process customer orders, manage inventory, and handle logistics.
You will have access to an LLM agent that is responsible for executing the plan that you create and will return results.
The LLM agent has access to the following functions:
- get_inventory_status(product_id)
- This gets the currently available product that we have
- get_product_details(product_id)
- This function gets the necessary components we need to manufacture additional product
...
When creating a plan for the LLM to execute, break your instructions into a logical, step-by-step order, using the specified format:
- **Main actions are numbered** (e.g., 1, 2, 3).
- **Sub-actions are lettered** under their relevant main actions (e.g., 1a, 1b).
- **Sub-actions should start on new lines**
- **Specify conditions using clear 'if...then...else' statements** (e.g., 'If the product was purchased within 30 days, then...').
- **For actions that require using one of the above functions defined**, write a step to call a function using backticks for the function name (e.g., `call the get_inventory_status function`).
- Ensure that the proper input arguments are given to the model for instruction. There should not be any ambiguity in the inputs.
- **The last step** in the instructions should always be calling the `instructions_complete` function. This is necessary so we know the LLM has completed all of the instructions you have given it.
- **Detailed steps** The plan generated must be extremely detailed and thorough with explanations at every step.
Use markdown format when generating the plan with each step and sub-step.
Please find the scenario below.
"""
Execution Model Prompt Design
Once a plan is generated, the execution model is respnsible for executing it. The system prompt clearly defines its role and behavior, including:
- Define Core Responsibility: We define its role and emphasize that its primary task it to “strictly follow the given policy.” This prevents it from deviating from the intended workflow.
- Explain Decision-Making: We require the model to explain the logic behind each step it takes. This provides real-time insight into task progress and helps identify potential issues quickly.
- Chain-of-Thought: We provide the execution model with clear CoT instructions. This helps guides its reasoning for more accurate judgments when performing specific,detailed steps.
# System prompt for the execution model
execution_prompt = """
You are a helpful assistant responsible for executing the policy on handling incoming orders. Your task is to follow the policy exactly as it is written and perform the necessary actions.
You must explain your decision-making process across various steps.
# Steps
1. **Read and Understand Policy**: Carefully read and fully understand the given policy on handling incoming orders.
2. **Identify the exact step in the policy**: Determine which step in the policy you are at, and execute the instructions according to the policy.
3. **Decision Making**: Briefly explain your actions and why you are performing them.
4. **Action Execution**: Perform the actions required by calling any relevant functions and input parameters.
POLICY:
{policy}
"""
Process Orchestration
After setting up prompts, variables, and tool functions, we define a main controller function to run the whole process:
- Receive Scenario: The function takes the initial customer scenario as input.
- Generate Plan: It calls the planning model to generate a detailed, step-by-step action plan based on the scenario.
- Initiate Execute Loop: It initializes an execution model “worker” and provides it with the plan. This worker enters a loop, using the defined function-calling mechanism to execute each step.
- Return Results: When all steps are complete, the loop terminates. The conversation history and final results are returned, clearly showing how the system addressed and completed the task.
def process_scenario(scenario):
append_message({'type': 'status', 'message': 'Generating plan...'})
plan = call_planning(scenario)
append_message({'type': 'plan', 'content': plan})
append_message({'type': 'status', 'message': 'Executing plan...'})
messages = call_execution(plan)
append_message({'type': 'status', 'message': 'Processing complete.'})
return messages
The call_execution(plan) function is the core of this process. It receives the plan from the reasoning model and initiates a while loop to interact with the execution model:
- In each iteration of the loop, it provides the current plan and conversation history to the execution model.
- The execution model analyzes the information and decides to make a tool call.
- The system intercepts this request, executes the corresponding Python function, and returns the result as a new message.
- This process repeats until the execution model calls a special
instructions_completefunction, signaling that all tasks are finished. At this point, the loop breaks, and the execution is complete.
def call_execution(plan):
execution_prompt = execution_prompt.replace("{policy}", plan)
messages = [
{'role': 'system', 'content': execution_prompt},
]
while True:
response = client.chat.completions.create(
model=V3_MODEL,
messages=messages,
tools=TOOLS,
parallel_tool_calls=False
)
assistant_message = response.choices[0].message.to_dict()
print(assistant_message)
messages.append(assistant_message)
append_message({'type': 'assistant', 'content': assistant_message.get('content', '')})
if (response.choices[0].message.tool_calls and
response.choices[0].message.tool_calls[0].function.name == 'instructions_complete'):
break
if not response.choices[0].message.tool_calls:
continue
for tool in response.choices[0].message.tool_calls:
tool_id = tool.id
function_name = tool.function.name
input_arguments_str = tool.function.arguments
append_message({'type': 'tool_call', 'function_name': function_name, 'arguments': input_arguments_str})
try:
input_arguments = json.loads(input_arguments_str)
except (ValueError, json.JSONDecodeError):
continue
if function_name in function_mapping:
try:
function_response = function_mapping[function_name](**input_arguments)
except Exception as e:
function_response = {'error': str(e)}
else:
function_response = {'error': f"Function '{function_name}' not implemented."}
try:
serialized_output = json.dumps(function_response)
except (TypeError, ValueError):
serialized_output = str(function_response)
messages.append({
"role": "tool",
"tool_call_id": tool_id,
"content": serialized_output
})
append_message({'type': 'tool_response', 'function_name': function_name, 'response': serialized_output})
return messages
Define and Run a Scenario
With everything in place, we define a specific business scenario to kick off the workflow. The scenario includes:
- Mandatory Instruction: The customer must be notified before the final set of operations is competed.
- Prioritization Rule: The strategy should prioritize fulfilling orders with existing inventory first, before placing new purchase orders for out-of-stock components.
# Example usage
scenario_text = ("We just received a major shipment of new orders. "
"Please generate a plan that gets the list of awaiting "
"orders and determines the best policy to fulfill them.\n\n"
"The plan should include checking inventory, ordering "
"necessary components from suppliers, scheduling production "
"runs with available capacity, ordering new components "
"required from suppliers, and arranging shipping to the "
"retailer’s distribution center in Los Angeles. Notify "
"the customer before completing.\n\n"
"Prioritize getting any possible orders out that you can "
"while placing orders for any backlog items.")
# Process the scenario
messages = process_scenario(scenario_text)
Finally, we pass this scenario to the system to generate a plan and observe how it autonomously executes the complex task from start to finish.